
【数据竞赛】竞赛常见问题解答
问题:Kaggle与国内比赛有什么区别么?
Kaggle与国内竞赛模式存在区别,比如Notebook平台资源,其次Kaggle的分享机制比较好。
Kaggle整体面向全球,国内人数也蛮多,整体难度也会更难。
问题:机器学习、深度学习算法方向,需要有多少数学基础?
大学数学的基础即可,特别是线性代数、矩阵计算。可以多关注如何计算和求导的过程,其他的过程可以之后用到再学。
问题:CV方面轻量化transformer有哪些idea,可以从哪些方面入手,可以不使用官方预训练评判模型效果吗?
答:transformer在推荐系统和CV中有使用,具体可以参考CNN轻量化的思路。
问题:lightgbm如何调参?
可以关注比较核心的参数:https://lightgbm.readthedocs.io/en/latest/Parameters-Tuning.html
同时也建议多去理解模型的参数含义,以及参数如何影响模型的精度。
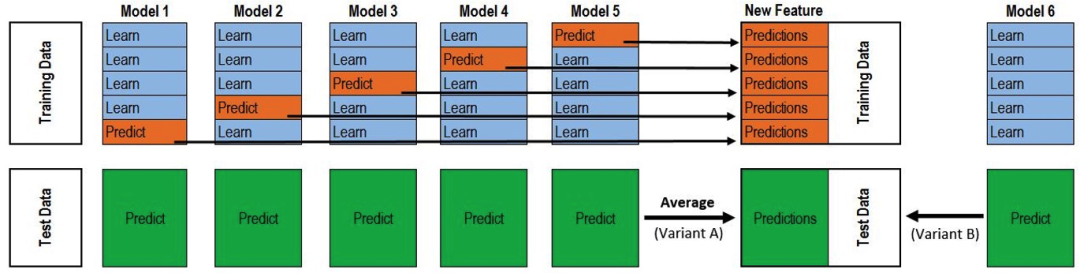
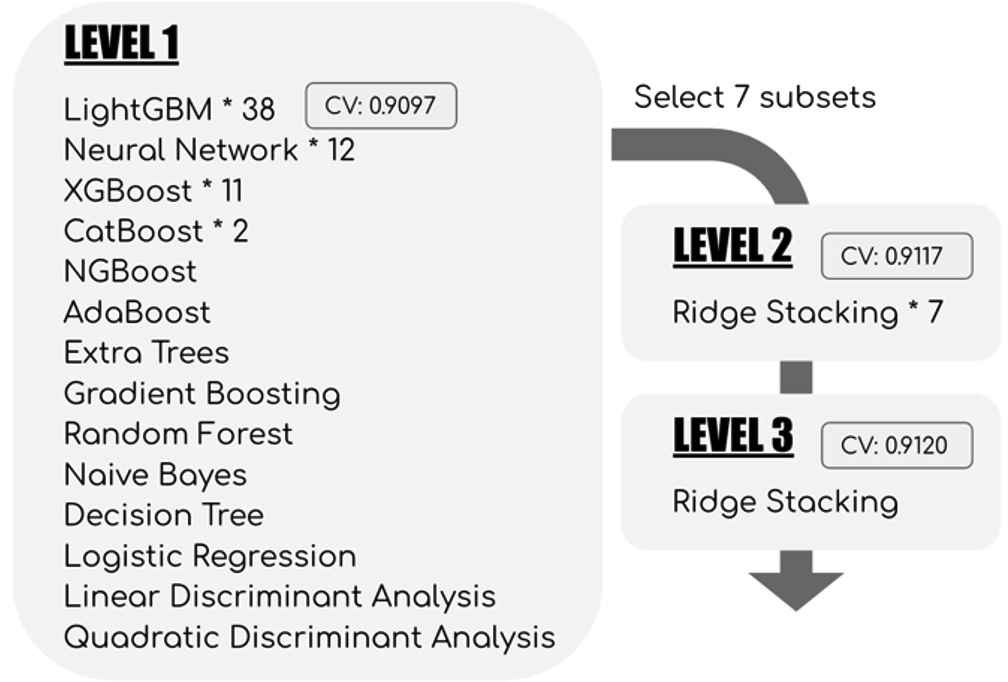
问题:stacking具体的细节能讲讲吗?
按照如下交叉验证的思路进行,每个模型对训练集和测试集增加一列特征,迭代进行。
问题:智能科学与技术专业大四在读,老师说毕业设计题目任选,且目前在准备考研,想问关于选题有什么建议吗?
首先建议考研方向和选题相关,其次本科毕业设计其实要求不是很多,要么是做应用,要么是研究。
问题:能说一下,对于nan值的处理方法吗?
你应该知道数据是如何产生的,哪些特征对业务有影响,只有这样你才能给出最好的数据结果。
具体参考我们之前的文章Kaggle知识点:缺失值处理方法
问题:怎么处理数据类别极度不均衡的情况?
可以从损失函数、样本权重、评价指标、数据采样考虑。调节权重与采样在概率部分存在区别,采样后的模型的输出概率需要校准。
问题:回归用什么损失函数比较好,训练后期进行验证,验证集上指标有1到3个点波动正常吗?
这个看看数据量和标签量级,从文字表达暂时看不出问题。
问题:如果构造一个验证集?
首先分任务,时序任务 & 非时序任务
时序任务:与测试集最近的一天 & 最相似的一天作为验证集 非时序任务:按照样本的分布采样验证集
问题:小白不知道怎么开始一个有质量的竞赛
推荐先掌握pandas、sklearn工具,理论和工具不断累计即可。
问题:结构化数据中的文本特征应该如何处理,(不采用nn,使用树模型的话)
- 文本 -> 分词 -> TFIDF -> SVD/PCA/LDA降维
- 文本 -> 嵌入 -> mean/max pooling
问题:如何形成规模的代码块?
可以按照模型API、数据特征处理、特征编码
问题:对数据比赛无从下手,该从什么地方开始好?或者很难在baseline上做提升,怎么办?
如果无从下手,可以去尝试做一个baseline。如果想对baseline做改进,可以从验证集的分数去分析,然后做改进,可以参考类似的模型,或者添加业务特征。
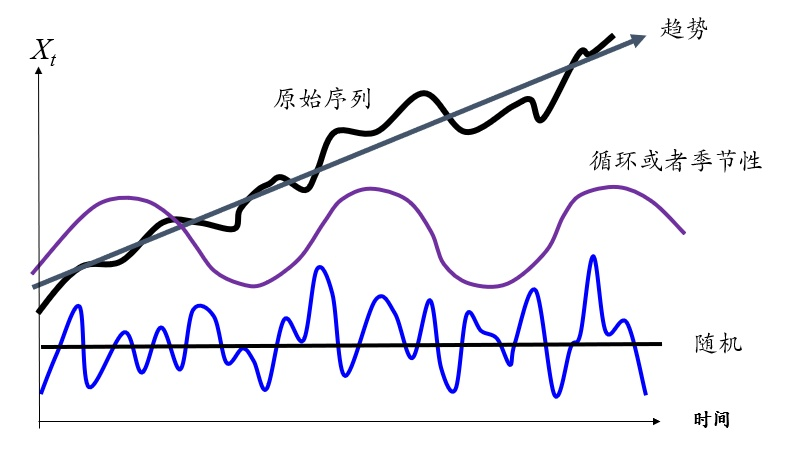
问题:就那种用历史数据预测未来数据时,如何构造特征呢
序列的模式,趋势、周期、相关性、随机性 自回归 & 多元回归
问题:全是匿名字段的结构化数据应该怎么进行特征构造和eda探索呢。
首先看字段类型、看字段分布、相关性
问题:想请教水哥和鱼佬,业内通常是怎么做分布式训练的呀?
工业主要看库和平台,具体的方法有模型并行,数据并行和参数平均。
具体细节可以参考:《分布式机器学习:算法、理论与实践》
问题:torch和tensorflow推荐?
初学者torch,tensorflow1.X比较多,paddlepaddle也是不错的选择。
问题:在分类问题中,对于树模型输出的特征重要度里面有些重要度为0的特征,drop后auc下降了,那这类特征需要删除吗?
树模型的特征重要性和最终的得分并不是一致的,这里可以通过模型包裹式来选择特征。
问题:鱼佬,你的书有推荐的阅读路线吗?小白读的读起来有点难懂。
如果数据集比较大可以用部分数据集进行训练,小白建议按照章节依次阅读。
往期精彩回顾 本站qq群554839127,加入微信群请扫码: