
【107期】谈谈面试必问的Java内存区域(运行时数据区域)和内存模型(JMM)

阅读本文大概需要 12 分钟。
来自:www.cnblogs.com/czwbig/p/11127124.html
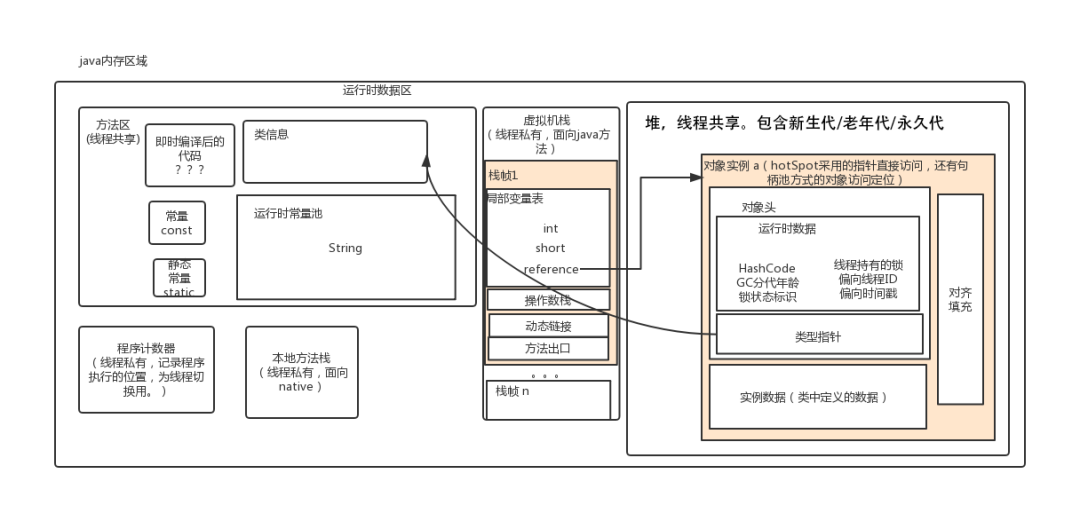
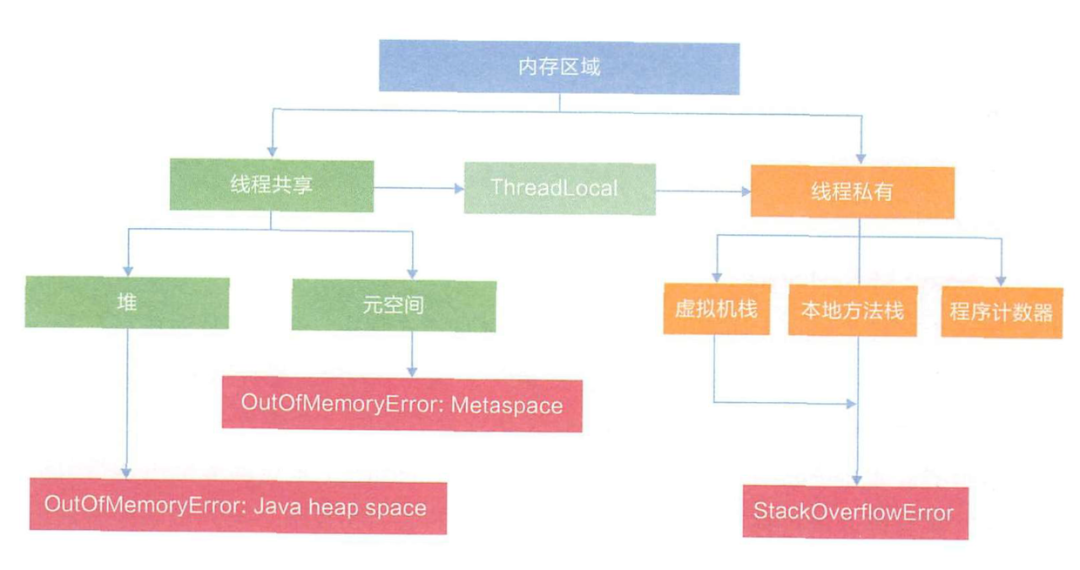
Java运行时数据区域
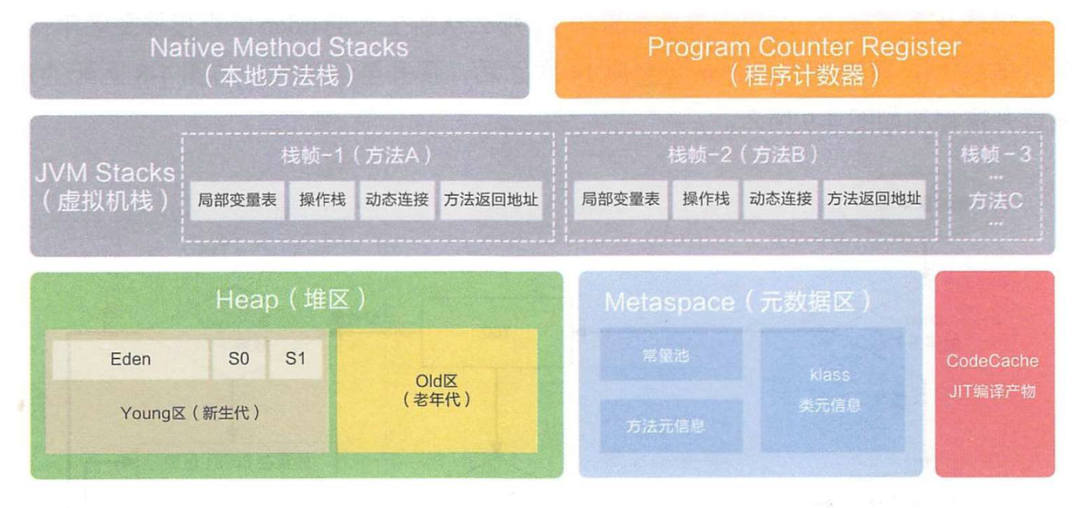
由于 PermGen 内存经常会溢出,引发恼人的 java.lang.OutOfMemoryError: PermGen,因此 JVM 的开发者希望这一块内存可以更灵活地被管理,不要再经常出现这样的 OOM
移除 PermGen 可以促进 HotSpot JVM 与 JRockit VM 的融合,因为 JRockit 没有永久代。根据上面的各种原因,PermGen 最终被移除,方法区移至 Metaspace,字符串常量移至 Java Heap。
引用自https://www.sczyh30.com/posts/Java/jvm-metaspace/
程序计数器
Java虚拟机栈
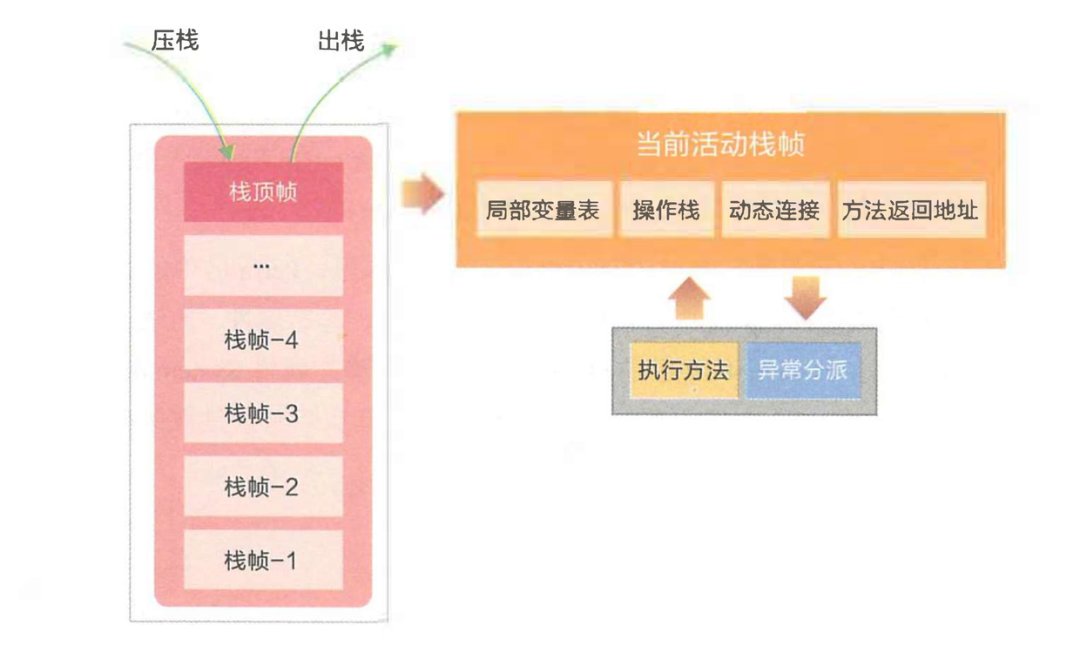
1. 局部变量表
2. 操作栈
栈中写入和提取信息。JVM 的执行引擎是基于栈的执行引擎, 其中的栈指的就是操
作栈。字节码指令集的定义都是基于栈类型的,栈的深度在方法元信息的 stack 属性中。
i++:从局部变量表取出 i 并压入操作栈,然后对局部变量表中的 i 自增 1,将操作栈栈顶值取出使用,最后,使用栈顶值更新局部变量表,如此线程从操作栈读到的是自增之前的值。
++i:先对局部变量表的 i 自增 1,然后取出并压入操作栈,再将操作栈栈顶值取出使用,最后,使用栈顶值更新局部变量表,线程从操作栈读到的是自增之后的值。
3. 动态链接
4.方法返回地址
正常退出,即正常执行到任何方法的返回字节码指令,如 RETURN、IRETURN、ARETURN 等;
异常退出。
返回值压入上层调用栈帧。
异常信息抛给能够处理的栈帧。
PC计数器指向方法调用后的下一条指令。
本地方法栈
Java堆
方法区
字符串存在永久代中,容易出现性能问题和内存溢出。
类及方法的信息等比较难确定其大小,因此对于永久代的大小指定比较困难,太小容易出现永久代溢出,太大则容易导致老年代溢出。
永久代会为 GC 带来不必要的复杂度,并且回收效率偏低。
将 HotSpot 与 JRockit 合二为一。
运行时常量池
直接内存
Java内存模型
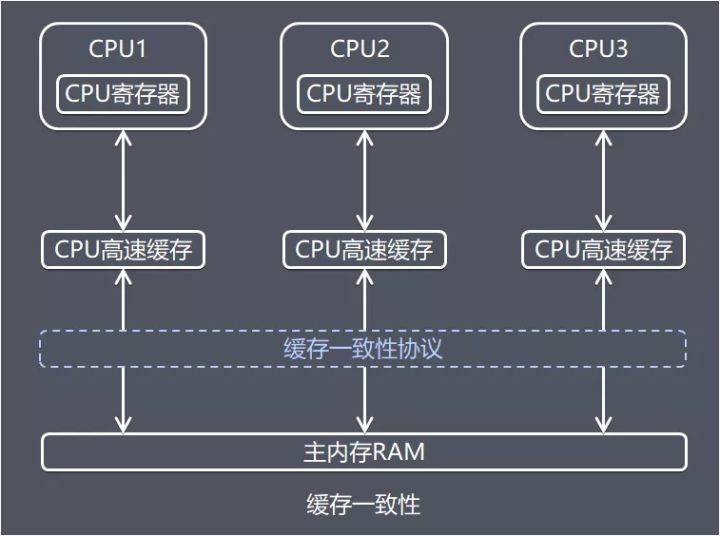
计算机高速缓存和缓存一致性
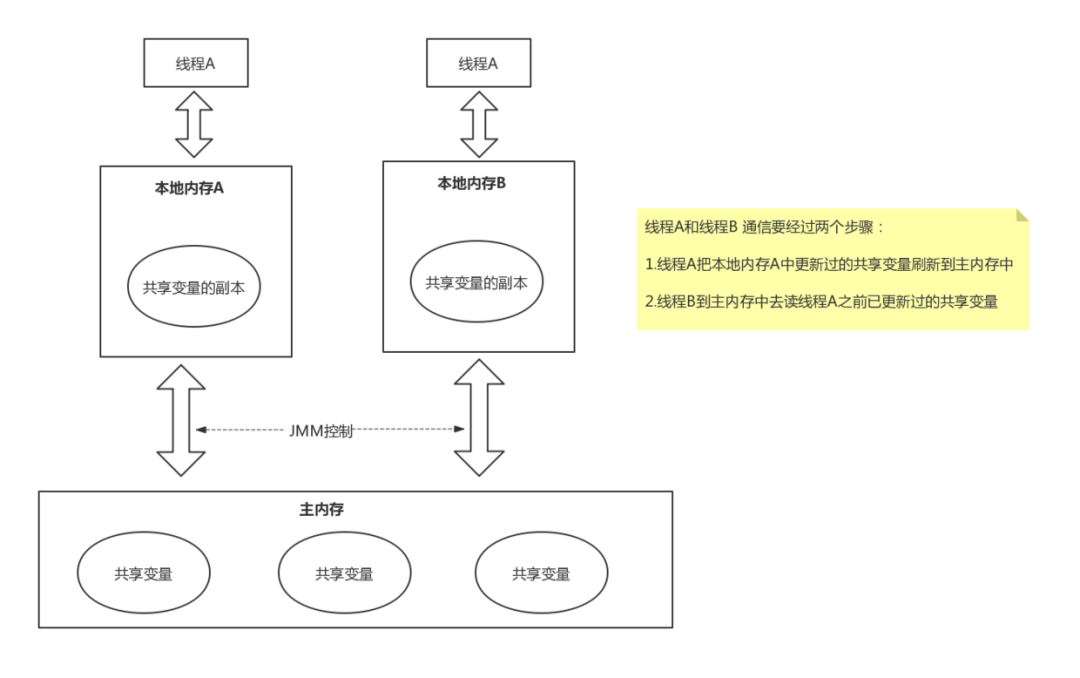
JVM主内存与工作内存
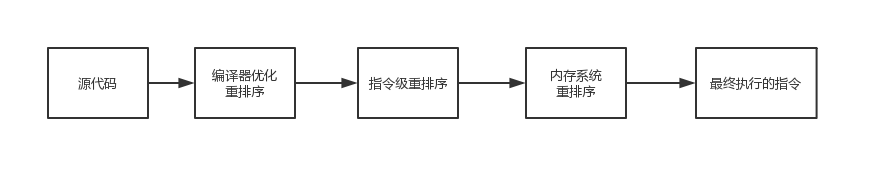
重排序和happens-before规则
编译器优化的重排序。编译器在不改变单线程程序语义的前提下,可以重新安排语句的执行顺序。
指令级并行的重排序。现代处理器采用了指令级并行技术(Instruction-Level Parallelism, ILP)来将多条指令重叠执行。如果不存在数据依赖性,处理器可以改变语句对应机器指令的执行顺序。
内存系统的重排序。由于处理器使用缓存和读 / 写缓冲区,这使得加载和存储操作看上去可能是在乱序执行。
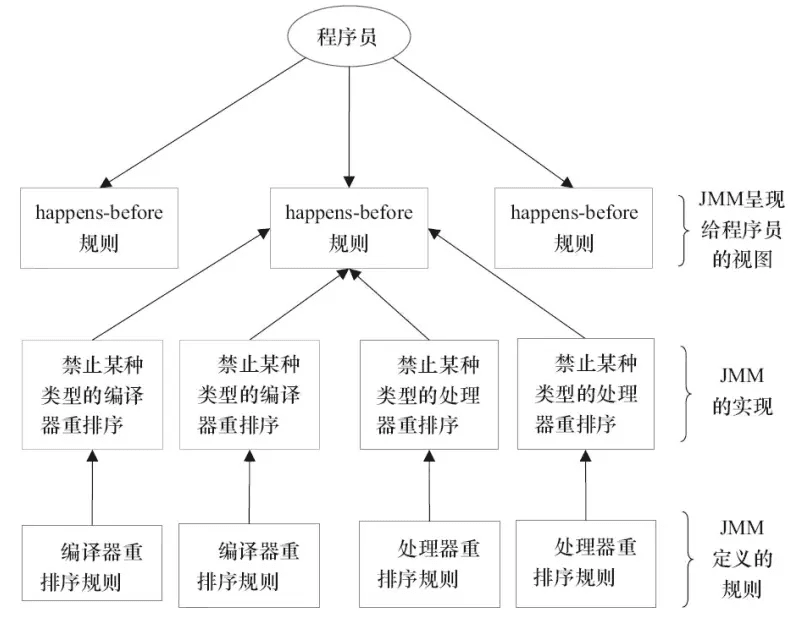
happens-before
程序顺序规则:一个线程中的每个操作,happens- before 于该线程中的任意后续操作。
监视器锁规则:对一个监视器锁的解锁,happens- before 于随后对这个监视器锁的加锁。
volatile 变量规则:对一个 volatile 域的写,happens- before 于任意后续对这个 volatile 域的读。
传递性:如果 A happens- before B,且 B happens- before C,那么 A happens- before C。
volatile关键字
保证此变量对所有线程的可见性。而普通变量不能做到这一点,普通变量的值在线程间传递均需要通过主内存来完成。
禁止指令重排序优化。普通的变量仅仅会保证在该方法的执行过程中所有依赖赋值结果的地方都能获取到正确的结果,而不能保证变量赋值操作的顺序与程序代码中的执行顺序一致。
推荐阅读:
【106期】面试官:Java中的finally一定会被执行吗?
【105期】面试官:注册中心全部宕掉后,Dubbo服务还能进行调用吗?
微信扫描二维码,关注我的公众号
朕已阅 