
Transformer在计算机视觉中的应用-VIT、TNT模型
共 4902字,需浏览 10分钟
·
2023-09-01 18:13

向AI转型的程序员都关注了这个号👇👇👇
Transforme这一模型并不难,依旧是传统机器翻译模型中常见的seq2seq网络,里面加入了注意力机制,QKV矩阵的运算使得计算并行。
当然,最大的重点不是矩阵运算,而是注意力机制的出现。
一、CNN最大的问题是什么
CNN依旧是十分优秀的特征提取器,然而注意力机制的出现使得CNN隐含的一些问题显露了出来
CNN中一个很重要的概念是感受野,一开始神经网络渐层的的卷积核中只能看到一些线条边角等信息,而后才能不断加大,看到一个小小的“面”,看到鼻子眼睛,再到后来看到整个头部。一方面的问题是:做到这些需要网络层数不断地加深(不考虑卷积核的大小),感受野才会变大;另一方面的问题是:特征图所表达出来的信息往往是十分抽象的,我们不清楚到底需要多少层也不清楚每层的抽象信息是否都有用(ResNet出现)。
假设我们的脸贴在一幅画上,我们无法看出一幅画里都有什么;“管中窥豹”、“坐井观天”、“一叶障目” 等都是我们此时的感受野太小了;稍微抬下头,我们看到了画中的人;稍微站得远一步,我们看到了整幅画从脑中的经验得知,这是《清明上河图》。

上面这种情况是我们机械的从视野的角度去分辨看待事物,然而我们是人类,我们拥有注意力。
我们会在观察一张图片时会忽略背景,注意图片中的主体(或相反)
我们会在区分狮子还是老虎时,更注意看它们的毛发,它们的头上有没有“王”。

回想注意力机制的特点,它是从"整体"上观察我们需要什么,要注意的地方在哪里。既然是在整体上观察,那么其“感受野”,一定就相当于许多层之后的CNN了。
CNN许多层才做到的事情,在Transformer中第一层就做到了。
二、VIT整体架构解读
2.1 图像转换成序列
接下来就是该怎么做了,由于Transofrmer是序列到序列模型,我们需要把图像信息转为序列传给Encoder。
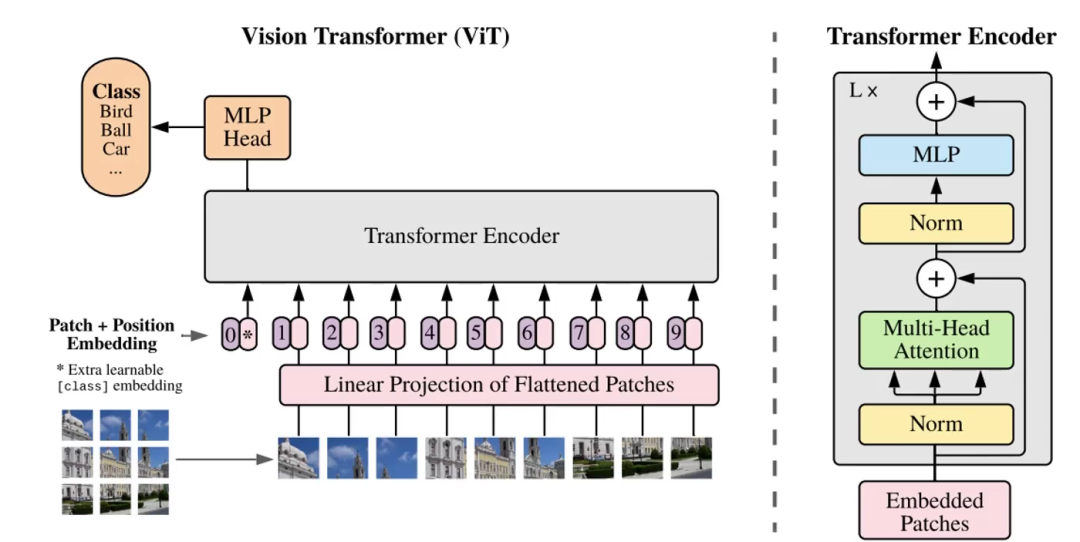
观察上图左下角,一个完整的图片,我们可以把它切割成9份(举例),9个patch,每一份比如说是10x10x3的矩阵。将每一份通过一次卷积变成1x300的矩阵,由此变成序列。
如上图,9个300维的向量传递给Linear Projection of Flattened Patches层,其实就是一次全连接进行映射,把我们这些300维的向量映射成256/512维等的向量。
之后传递给Transformer Encoder。
2.2 VIT位置编码
我们上面把一张图片切成了9份,每份都有建筑物的一部分,要让计算机更好地识别出图片内容,这9份应当给它们加上序号,即位置编码。
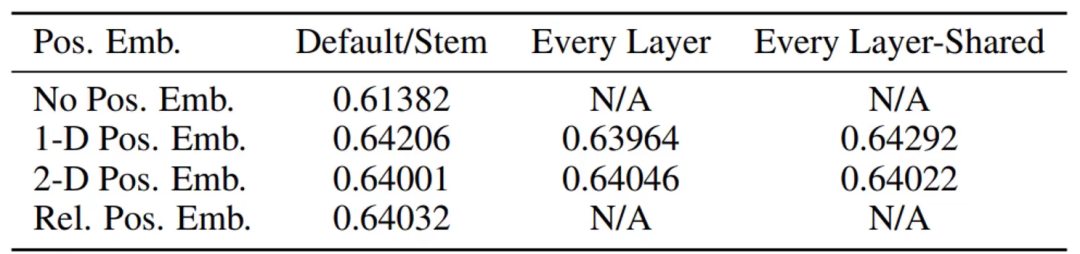
论文实验证明,加上序号比不加效果好;以1-9为序号和以(1,1) (1,2) (1,3) (2,1)...(3,3)为序号结果相差不大
当然,该论文进行的是分类任务,位置编码1D和2D确实没有太大区别。但如果放在分割等任务就不一定了。
2.3 VIT工作原理
可以看到,上图除了1-9以外,还存在一个序列0,我们把这个0叫做token。这个token一般只用于分类任务,而检测分割一般用不到。
以分类任务为例,无非是多了一行序列。
当把0号token+序列1-9传递给Encoder后,它内部进行QKV计算,和权重矩阵计算转变为QKV矩阵继续计算。其本质就是0号token+序列1-9这10个序列点积,这样0号token中就是存储着序列1-9的特征9个patch的。如此经过L轮,经过L轮计算,0号token中的信息就是全局信息了。
之后,就可以使用0号token这个向量去做分类了。
2.4 backbone

如上,Embedded Patches+位置编码后经过层归一化,多头注意力,层归一化,全连接,期间还有这残差连接。
另外这不只是一轮,而是会执行多次
三、Transformer为什么能
就像 一 中末尾说的那样,它是从"整体"上观察我们需要什么,要注意的地方在哪里。既然是在整体上观察,那么其“感受野”,一定就相当于许多层之后的CNN了。
因为0号token是最后拿去进行分类的,在计算时,第一层第一次的计算0号就分别于1-9patch进行了点积,这9个局部信息组成的整体便是这张图片。

上图可以看到,这样做在浅层就能获得较大的范围信息;可能5层就做得比CNN好了;全局信息丰富,更有助于理解图像。
四、VIT公式解读和效果图
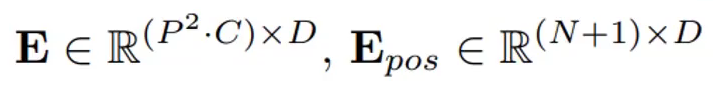
E表示的是全连接,P²·C的矩阵映射为P²·D维。后面的则是位置编码,(N+1)·D维,N是N个patch,+1是因为前面所提的0号token。
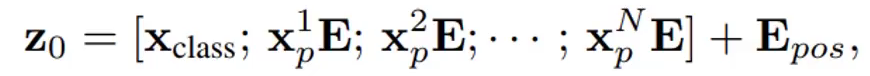
Z是每层的输入,Z0就是第0层,记得加上位置编码。
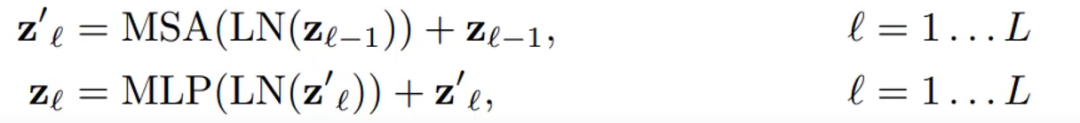
然后就是进行多轮多头注意力机制的运算,MSA是多头注意力,LN是层归一化,MLP是全连接。后面的加法是残差连接。
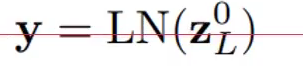
最后输出结果。
效果图
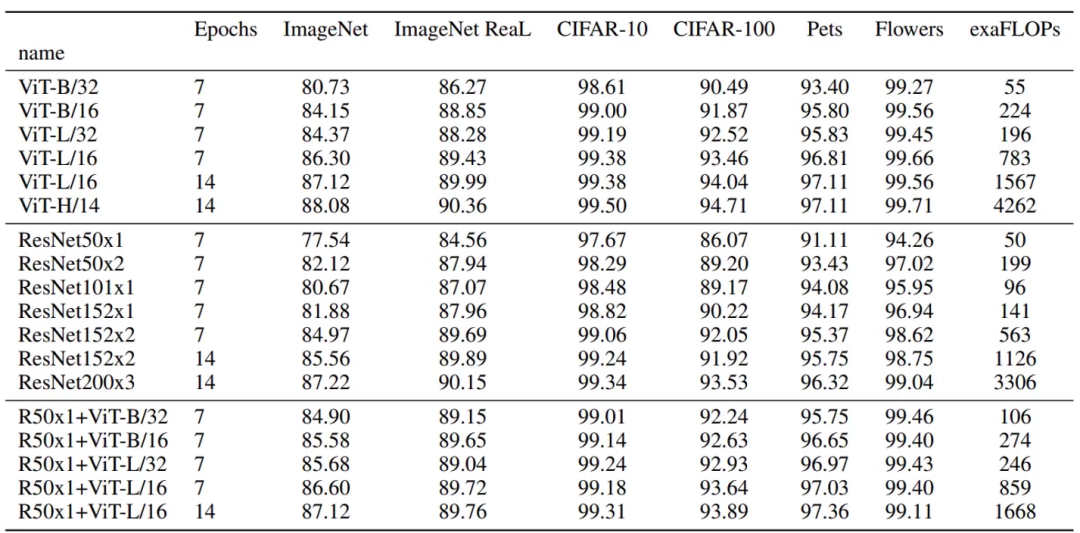
其中ViT后面的16 14 32指的是patch的大小,对于一张图片来说,patch越大窗口数量越少,patch越小窗口数量越多。
显然与ResNet相比,ViT更好些。
五、TNT模型
5.1 TNT介绍
TNT:Transformer in Transformer
在VIT中,只针对patch进行了建模,比如一个patch是16*16*C (其中C是特征图个数,可能是256、512等)。每个patch可能有点大了,越大的patch所蕴含的信息就越多,学习起来难度就越大。
因此,一方面可以基于patch去做,另一方面还可以把patch再分得细一点,如16*16分成4个4*4。
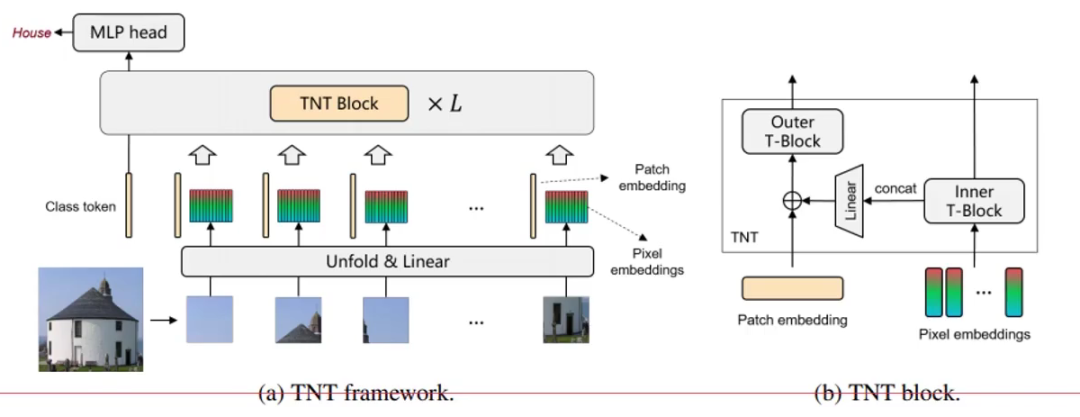
所以TNT的名字就代表了它要做什么,在Transformer里嵌套一个Transformer。
5.2 TNT模型做法分析
TNT由外部Transformer和内部Transoformer组成,其中:
外部Transformer与VIT的做法一样

内部把每个patch组成多个超像素(4个像素点),把重组的序列继续做Transformer。

以16*16为例,序列的长度就是256了,太长了太慢了效率低,且通常一个像素点也不能表达什么信息。至少也是4个点。因此内部将每个patch拆分成很多个4*4的小块,即分成更多个batch,然后重组。
以内部的一个16*16*3的patch为例,拆分成4*4的超像素,结果就是每一个超像素,每一个小patch上特征的个数。
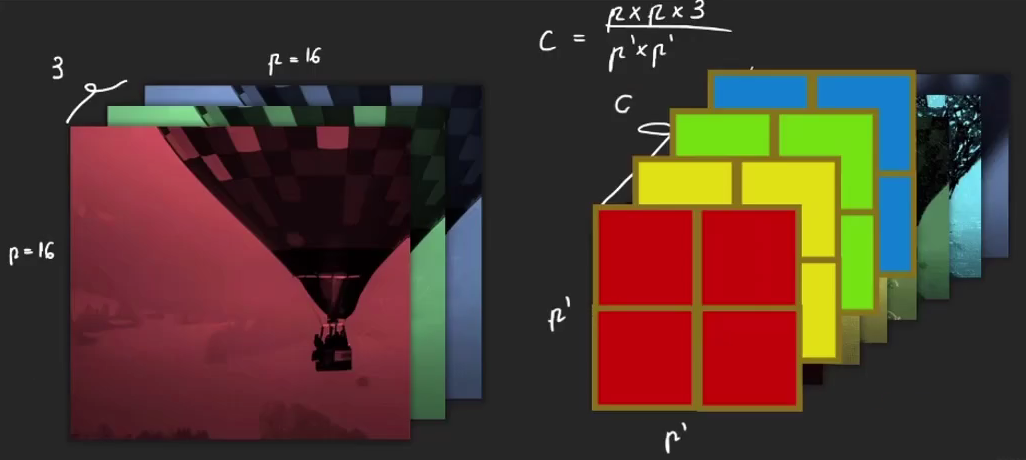
(16∗16∗3)/(4∗4)=48
之前一个点上有3个channel的信息,而现在一个点上有48个。patch变小了但浓缩了。
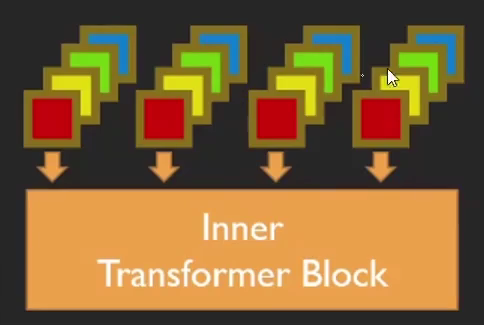
把这些小patch整合在一起,全连接,之后的Transformer与前面一样。

如上,每个patch经过外部Transformer计算得到向量,每个patch又拆分成小patch后全连接,经过内部Transformer得到同样维度的输出向量。两个向量加在一起,作为最后的输出结果。
5.4 TNT模型位置编码
实验证明,内外Transormer都进行位置编码效果更好。
5.5 TNT效果
上方是DeiT,就当作是VIT把,下面是TNT。
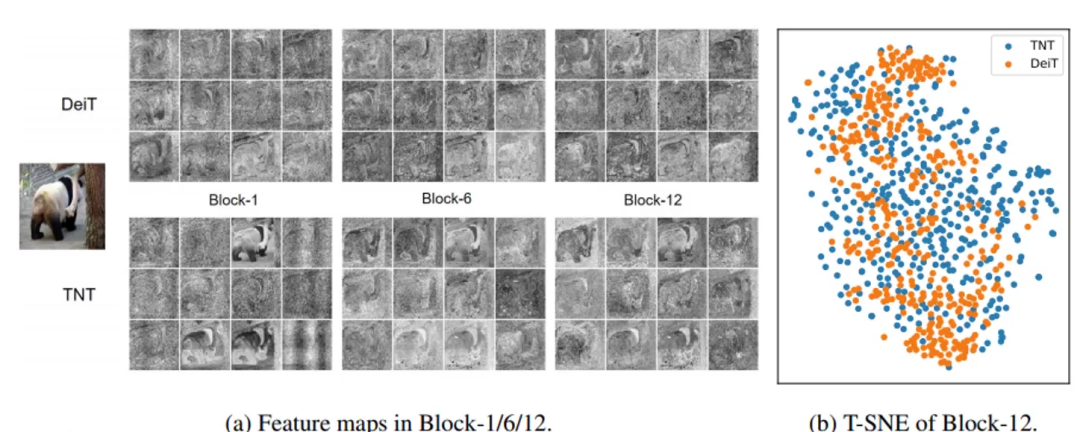
显而易见TNT特征提取得更鲜明,效果更好,更细腻。
右图可见TNT点更发散些,说明特征更发散些,更好区分。
机器学习算法AI大数据技术
搜索公众号添加: datanlp
长按图片,识别二维码
阅读过本文的人还看了以下文章:
基于40万表格数据集TableBank,用MaskRCNN做表格检测
《深度学习入门:基于Python的理论与实现》高清中文PDF+源码
2019最新《PyTorch自然语言处理》英、中文版PDF+源码
《21个项目玩转深度学习:基于TensorFlow的实践详解》完整版PDF+附书代码
PyTorch深度学习快速实战入门《pytorch-handbook》
【下载】豆瓣评分8.1,《机器学习实战:基于Scikit-Learn和TensorFlow》
李沐大神开源《动手学深度学习》,加州伯克利深度学习(2019春)教材
【Keras】完整实现‘交通标志’分类、‘票据’分类两个项目,让你掌握深度学习图像分类
如何利用全新的决策树集成级联结构gcForest做特征工程并打分?
Machine Learning Yearning 中文翻译稿
斯坦福CS230官方指南:CNN、RNN及使用技巧速查(打印收藏)
中科院Kaggle全球文本匹配竞赛华人第1名团队-深度学习与特征工程
不断更新资源
深度学习、机器学习、数据分析、python
搜索公众号添加: datayx