
高性能内存池实现

对于从事c/c++开发的人来说,malloc/new再也熟悉不过了,对于堆上的内存分配,都是使用标准库提供的函数来进行内存分配,而这些函数最终也会进入到系统调用(brk等),每次的内存申请和释放,都可能会涉及到底层内存数据的调整,所以效率会非常低。如果我们一次申请一块很大的内存块,后续所有的内存申请和分配,都是基于这一块内存来进行,这样效率就会提升很多,本文主要就是实现一个高效的固定大小的内存池。
结构
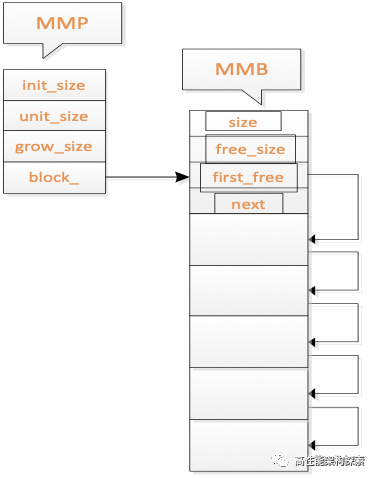
图一
实现
内存块定义:
typedef struct memory_block {unsigned int size;unsigned int free_size;unsigned int first_free;struct memory_block *next;char a_data[1];} s_memory_block;
内存池Header:
typedef struct memory_pool {unsigned int unit_size;unsigned int init_size;unsigned int grow_size;s_memory_block *block;} s_memory_pool;
初始化内存池:
//此函数初始化内存池Headers_memory_pool *memory_pool_create(unsigned int size) {s_memory_pool *mp;mp = (s_memory_pool*)malloc(sizeof(s_memory_pool));mp->first_block = NULL;mp->init_size = 10000;mp->grow_size = 10000;if(size < sizeof(unsigned int))mp->obj_size = sizeof(unsigned int);//对齐mp->unit_size = (size + (MEMPOOL_ALIGNMENT-1)) & ~(MEMPOOL_ALIGNMENT-1);return mp;}
当初始化之后,内存池结构变成:

图二
从函数实现内容来看,是初始化了内存池的头。
内存分配函数:
1、从mp的first_block开始,如果其为空,则表明该内存池为首次创建,需要分配内存块,并在该内存块内进行链式初始化,返回该块的第一小块地址。
2、从first_block开始,查找一个有内存可分配的block,如果有,则分配,并将first_free指向该块的下一个地址。
3、重新建一个block,进行分配,并将该新块插入到mp的头部
void *memory_alloc(s_memory_pool *mp) {register unsigned int i;register char *data;//unsigned int length;if(mp->first_block == NULL)//memory_pool is NULL{s_memory_block *mb;mb = (s_memory_block *)malloc((mp->init_size)*(mp->obj_size) + sizeof(s_memory_block));//create first memory_blockif(mb == NULL){perror("memory allocate failed!\n");return NULL;}/* init the first block */mb->next = NULL;mb->free_size = mp->init_size - 1;mb->first_free = 1;mb->size = mp->init_size*mp->obj_size;mp->first_block = mb;data = mb->a_data;/* set the mark */for(i=1; iinit_size; ++i) {//初始化块,链接方式类似于链表}return (void *)mb->a_data;} //如图三s_memory_block *pm_block = mp->first_block;while((pm_block!=NULL) && (pm_block->free_size==0)){pm_block = pm_block->next;}if(pm_block != NULL){char *pfree = pm_block->a_data + pm_block->first_free * mp->obj_size;//查找一个可用块返回// ......return (void *)pfree;}else{if(mp->grow_size == 0)return NULL;s_memory_block *new_block = (s_memory_block *)malloc((mp->grow_size)*(mp->obj_size) + sizeof(s_memory_block));if(new_block == NULL)return NULL;data = new_block->a_data;for(i=1; igrow_size; ++i) {//链式}//将新块插入到链表头首部return (void *)(new_block->a_data);}}
释放函数:
1、遍历该内存池,查找所要释放的内存块pfree所在的block
2、将该block的first指向该pfree的偏移
3、该pfree的偏移指向之前block的first
注:2、3处相当于链表的插入
inline void* memory_free(s_memory_pool *mp, void *pfree){if(mp->first_block == NULL)return;s_memory_block *pm_block = mp->first_block;s_memory_block *pm_pre_block = mp->first_block;/* research the memory_block which the pfree in */while(pm_block && ((unsigned int)pfree<(unsigned int)pm_block->a_data ||(unsigned int)pfree>((unsigned int)pm_block->a_data+pm_block->size))){//pm_pre_block = pm_block;pm_block = pm_block->next;if(pm_block == NULL)return NULL;}//获取偏移地址unsigned int offset = pfree -(void*) pm_block->a_data;if((offset&(mp->obj_size -1)) > 0)return pfree;//将释放的内存块返回给内存池对应的Block块pm_block->free_size++;*((unsigned int *)pfree) = pm_block->first_free;pm_block->first_free=(unsigned int)(offset/mp->obj_size);return NULL;}
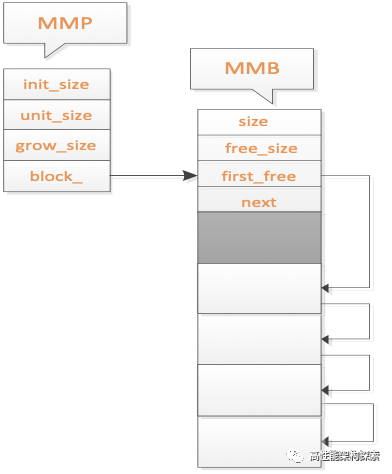
图三
当内存池为空的时候,也就是首次调用memory_alloc函数时候,会创建一个新的Block,并对这个Block进行初始化,然后返回首块地址 。
当第二次调用memory_alloc之后,如图四所示。
当第三次调用memory_alloc之后,如图五所示。
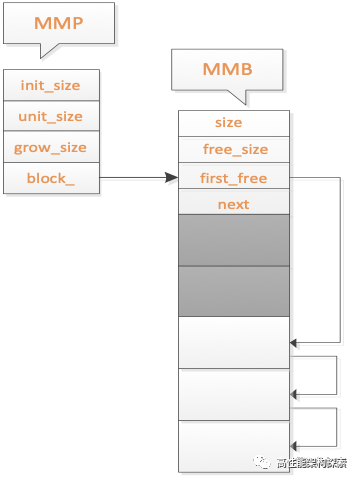
图四
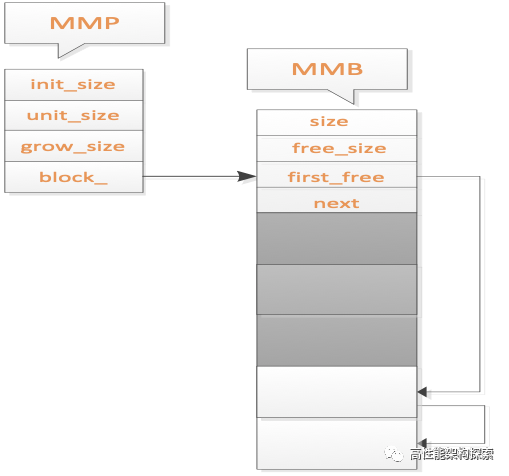
图五
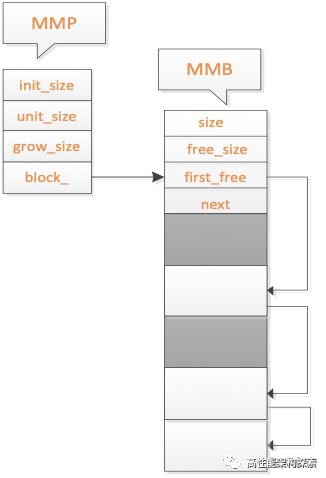
图六
当释放第二次分配的内存之后,整个内存块链表如图六所示。
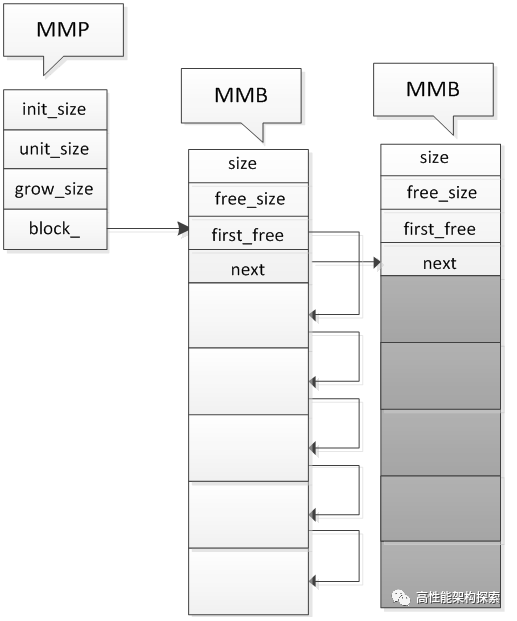
图八
当现在所有的Block里面都没有可用内存之后,就重新申请一块Block,并插入到Header的头部,如图八所示。
内存池数据结果:
与库函数malloc相比,性能提升了大概25%左右
注:本文旨在于提供一种设计思路,在本文实现的内存池,仅仅支持单线程,固定大小的,读者可以针对该思路,进行改进