
缓存Bigkey坚决不要用,拆分是王道
共 1559字,需浏览 4分钟
·
2021-12-24 23:23
点击上方蓝字“设为星标”
大家好,我是架构摆渡人。这是实践经验系列的第四篇文章,这个系列会给大家分享很多在实际工作中有用的经验,如果有收获,还请分享给更多的朋友。

背景介绍
在高并发的业务场景中,缓存是必须要上的,用来扛高并发。在某个业务场景中,增加了对一个配置信息的缓存,最开始是直接读取DB的,为了性能考虑在前面加了一层缓存。
加完后很长一段时间也没问题,DB的压力也减小了很多。不幸的是在某天的一个时间点内,流量增加了好几倍,RT直线上升,接口各种超时,就这样,一个线上故障诞生了。
整个过程持续了1分钟左右,监控告警稍微有点延迟,刚看完监控告警,准备介入处理时流量已经跌下来了,接口也恢复了正常。
事后,通过监控发现接口超时的原因是因为底层Redis超时了,说到这可能大家都抱着怀疑的态度,Redis这么快也能超时?是的,你没看错,就是Redis超时了。
而Redis超时的原因并不是说Redis性能不行,而是在同一时刻有大量的请求访问了同一个Key,这个Key缓存的内容很大,导致一瞬间就把网络带宽给占用完了,后续请求都进不来。
解决方案
扩容带宽
直接扩容是最简单有效的方式,如果有持续的高流量造成了影响,紧急扩容是必须要走的,先解决当前问题。
等流量平稳后再考虑代码层面的改造,因为带宽也不是无限的,程序不处理好,始终是个风险点。
拆分BigKey
数据量大了,我们会分库分表。耦合严重了,我们会拆新的模块或者独立的服务。小组人多了,我们会拆分成多个组。遇到BigKey,那就是拆它拆它拆它。
假设这是你的缓存内容,里面是一个很大的Json字符串,存储的是配置信息:
{"a":"....","b":"....","c":"....".........}
那么可以把对象中的每个Key再拆分一次,作为一个独立的Key,这样它的Value就小了很多。不同的key会在集群中的不同节点上,也就不会出现集中访问某个节点,带宽不够的场景。
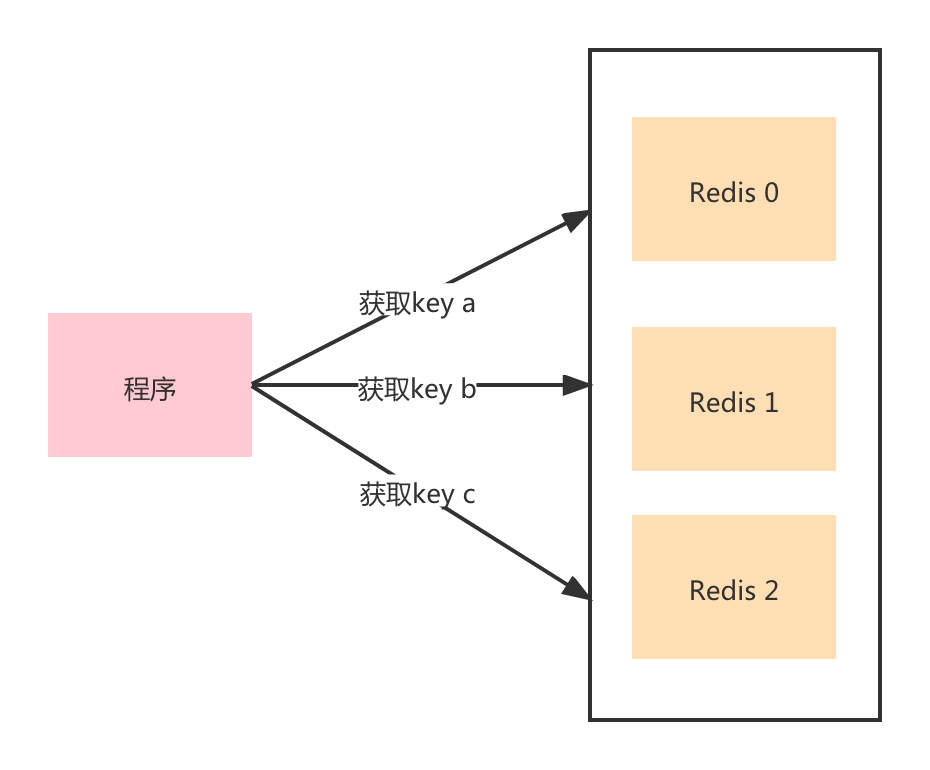
当然我这边说的是String类型,如果你的是List, Set这种,其实原理是一样的,同样是拆分成多个小的List, Key的前缀或者后缀不一样即可。
本地缓存
本地缓存,也是应对热点Key的常用解决方案。大家想想,一个固定的Key存储在Redis中,然后存储的内容也很大,访问量也比较高,带宽很容易成为瓶颈,因为要远程访问获取缓存内容。
如果将缓存存储在本地,那么就可以不用远程访问,从而带宽也就不会成为瓶颈。
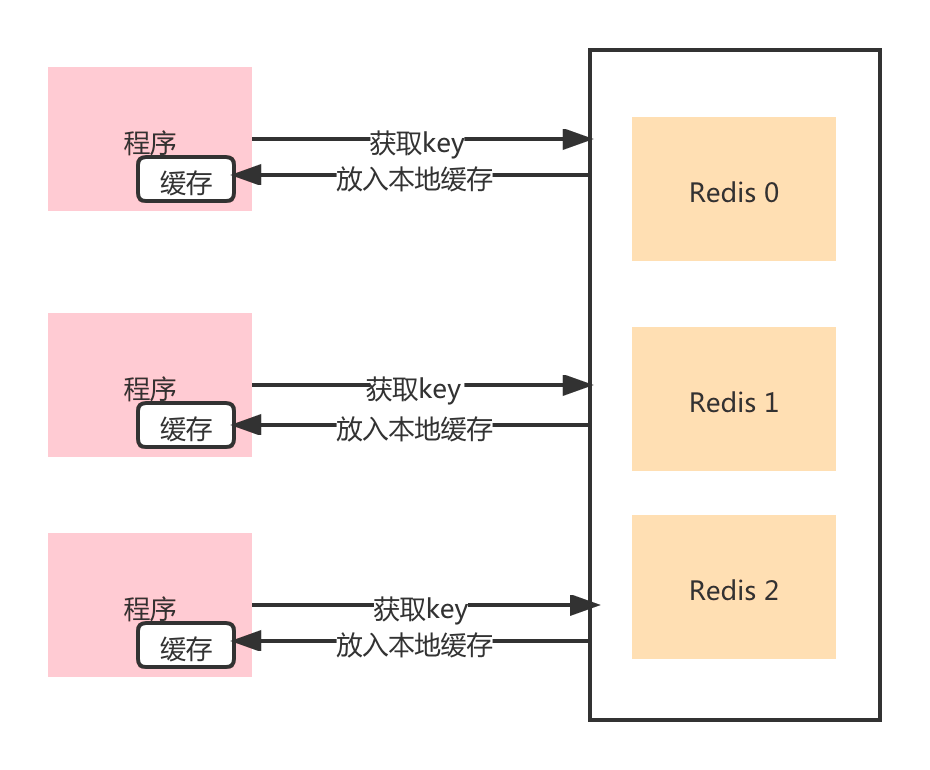
如果用了本地缓存,相信很多读者第一想法就是一致性怎么维护,这个无论是在实际应用中还是面试中都是一个高频的问题。
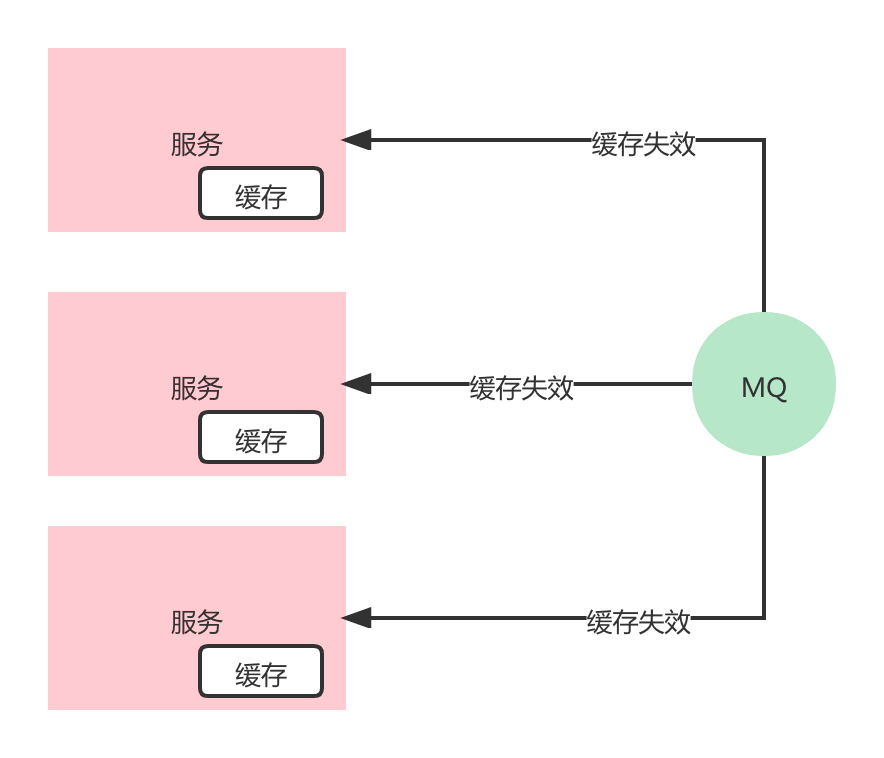
还是得从业务场景触发,用缓存的场景肯定就是没有强一致性的要求,能够容忍短暂的不一致。所以在Redis缓存失效或者数据有变更的时候,本地缓存也需要同步清除。
一般都会采用消息广播的方式进行通知本地缓存失效,因为服务是集群部署的,每个节点上都有一份缓存数据,所以需要广播通知。
BigKey的治理
最后要进行BigKey的治理,梳理出来目前已有的BigKey,根据业务场景进行优化。同时在后续使用缓存的场景对缓存内容严格把关,防止出现类似的问题。
大家好,我是从古代穿越过来的美男子:架构摆渡人。我将把我的武功秘籍全部传授与你们,觉得有用请分享给身边的朋友。来个三连吧,感谢各位!另外我还在B站录制了《真实订单业务,亿级数据带你实战分库分表》的实战课程,记得去学习哦!
点击阅读原文直达主页