
MAGIC: 即插即用、无需训练的图像-文本生成框架
来源:知乎—刘亚辉
地址:https://zhuanlan.zhihu.com/p/510927638

01
02
03
3.1 无监督语言建模
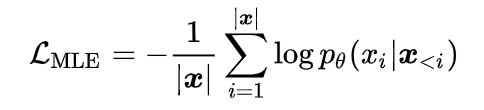
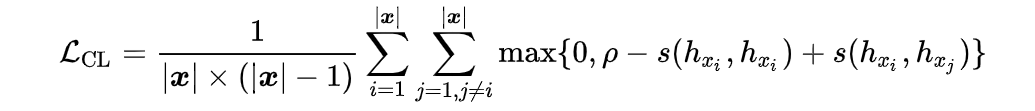
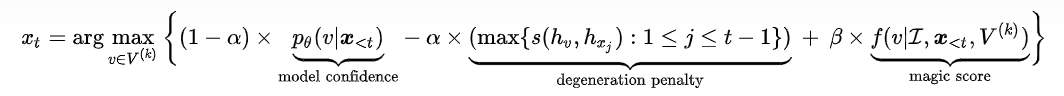
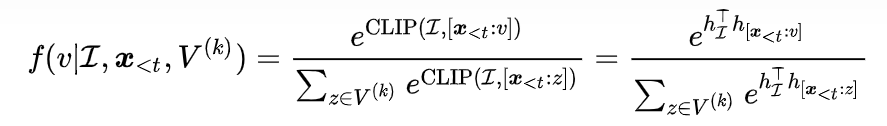
04
4.1 Zero-shot Image Captioning
4.1.1 实验设置
4.1.2 MS-COCO和Flickr30k实验结果
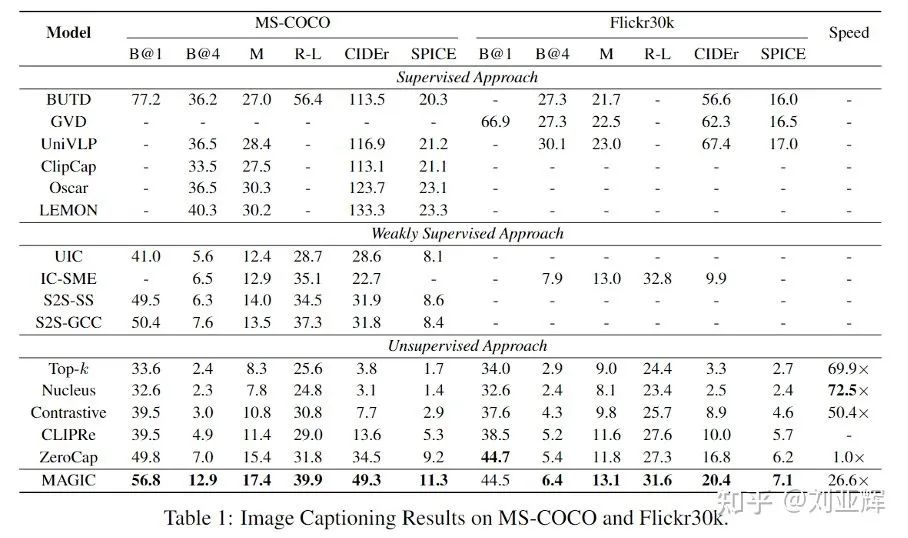
4.1.3. 跨领域实验结果
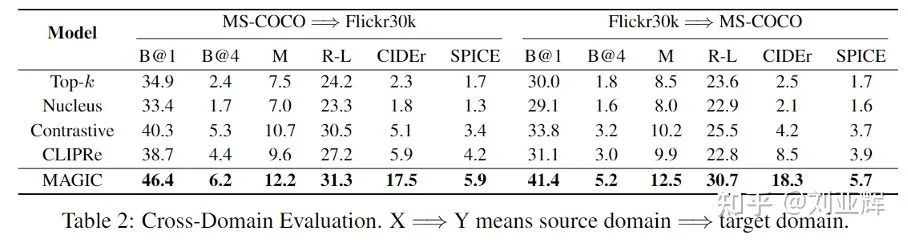
4.1.4. Case Study

4.2 Visually Grounded Story Generation
4.2.1 实验设置
4.2.2 实验结果
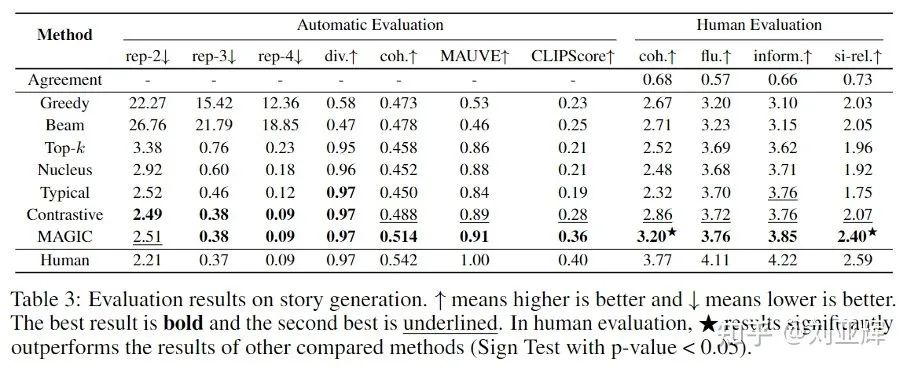
4.2.3 Case Study

猜您喜欢:
 戳我,查看GAN的系列专辑~!
戳我,查看GAN的系列专辑~!附下载 |《TensorFlow 2.0 深度学习算法实战》
评论