
扩散模型爆火!这是首篇综述
本文首次对现有的扩散生成模型(diffusion model)进行了全面的总结分析,还在Github分类汇总了相关论文。


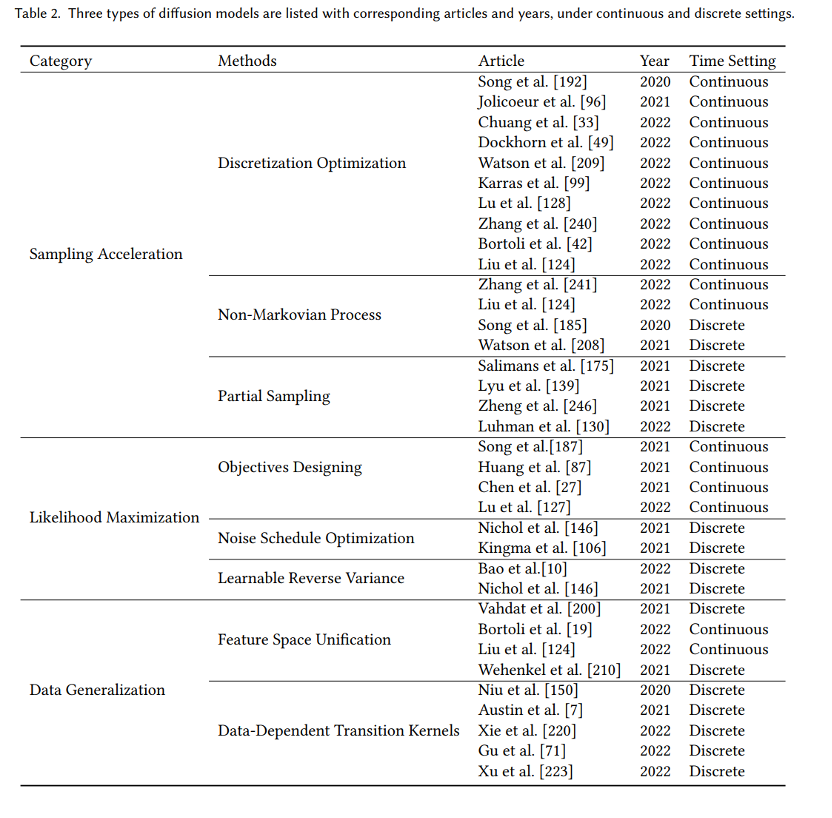
新的分类方法:我们对扩散模型和其应用提出了一种新的、系统的分类法。具体的我们将模型分为三类:采样速度增强、最大似然估计增强、数据泛化增强。进一步地,我们将扩散模型的应用分为七类:计算机视觉,NLP、波形信号处理、多模态建模、分子图建模、时间序列建模、对抗性净化。 全面的回顾:我们首次全面地概述了现代扩散模型及其应用。我们展示了每种扩散模型的主要改进,和原始模型进行了必要的比较,并总结了相应的论文。对于扩散模型的每种类型的应用,我们展示了扩散模型要解决的主要问题,并说明它们如何解决这些问题。 未来研究方向:我们对未来研究提出了开放型问题,并对扩散模型在算法和应用方面的未来发展提供了一些建议。
 表示原始数据及其分布, 则前向链的分布是可由下式表达:
表示原始数据及其分布, 则前向链的分布是可由下式表达:
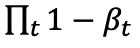 趋于 1 时,x_T 可以近似认为服从标准高斯分布。当β_t 很小时,逆向过程的转移核可以近似认为也是高斯的:
趋于 1 时,x_T 可以近似认为服从标准高斯分布。当β_t 很小时,逆向过程的转移核可以近似认为也是高斯的: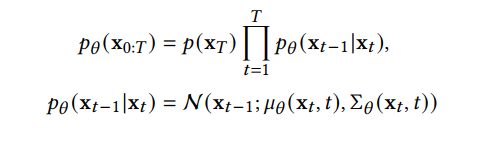
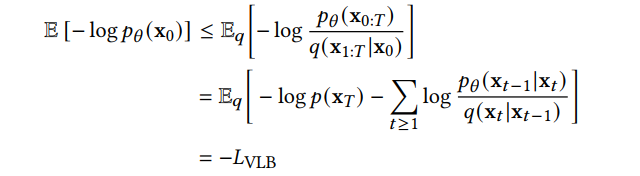
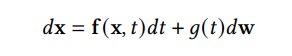
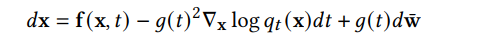
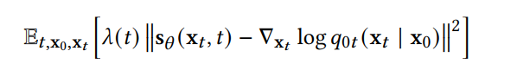
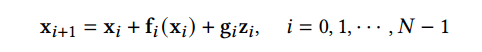
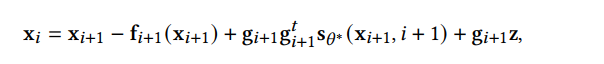
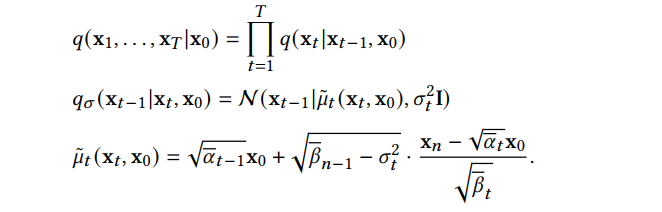

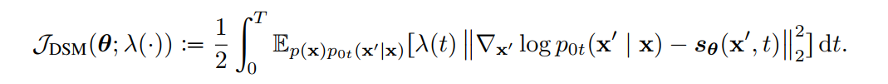
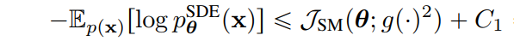
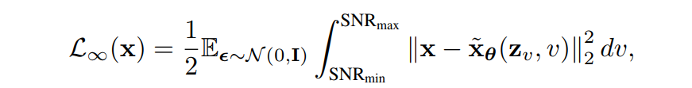



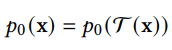
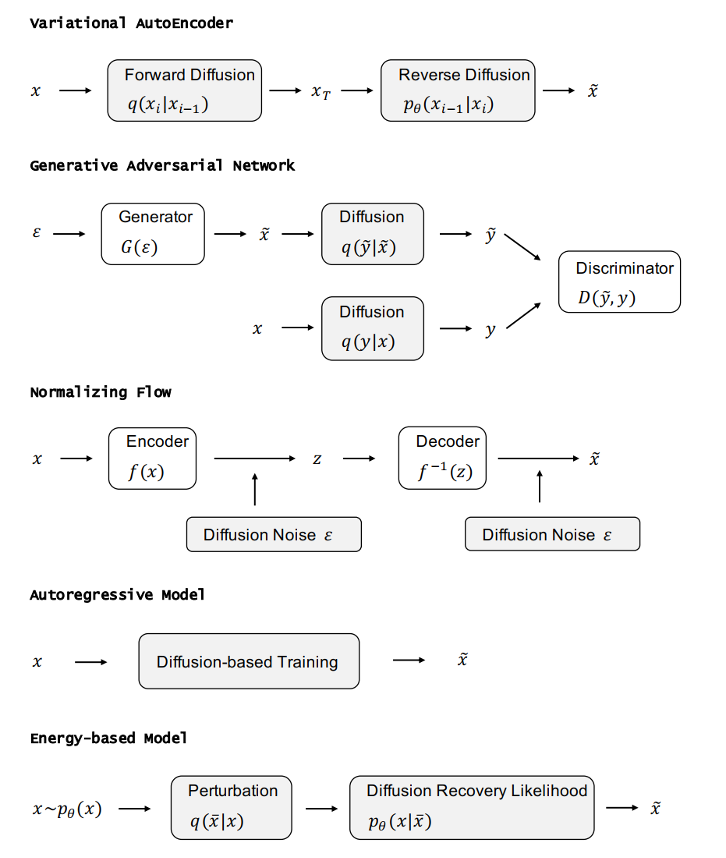
DDPM 可以视作层次马尔可夫 VAE(hierarchical Markovian VAE)。但 DDPM 和一般的 VAE 也有区别。DDPM 作为 VAE,它的 encoder 和 decoder 都服从高斯分布、有马尔科夫行;其隐变量的维数和数据维数相同;decoder 的所有层都共用一个神经网络。 DDPM 可以帮助 GAN 解决训练不稳定的问题。因为数据是在高维空间中的低维流形中,所以 GAN 生成数据的分布和真实数据的分布重合度低,导致训练不稳定。扩散模型提供了一个系统地增加噪音的过程,通过扩散模型向生成的数据和真实数据添加噪音,然后将加入噪音的数据送入判别器,这样可以高效地解决 GAN 无法训练、训练不稳定的问题。 Normalizing flow 通过双射函数将数据转换到先验分布,这样的作法限制了 Normalizing flow 的表达能力,导致应用效果较差。类比扩散模型向 encoder 中加入噪声,可以增加 Normalizing flow 的表达能力,而从另一个视角看,这样的做法是将扩散模型推广到前向过程也可学习的模型。 Autoregressive model 在需要保证数据有一定的结构,这导致设计和参数化自回归模型非常困难。扩散模型的训练启发了自回归模型的训练,通过特定的训练方式避免了设计的困难。 Energy-based model 直接对原始数据的分布建模,但直接建模导致学习和采样都比较困难。通过使用扩散恢复似然,模型可以先对样本加入微小的噪声,再从有略微噪声的样本分布来推断原始样本的分布,使的学习和采样过程更简单和稳定。




应用假设再检验。我们需要检查我们在应用中普遍接受的假设。例如,实践中普遍认为扩散模型的前向过程会将数据转换为标准高斯分布,但事实并非如此,更多的前向扩散步骤会使最终的样本分布与标准高斯分布更接近,与采样过程一致;但更多的前向扩散步骤也会使估计分数函数更加困难。理论的条件很难获得,因此在实践中操作中会导致理论和实践的不匹配。我们应该意识到这种情况并设计适当的扩散模型。 从离散时间到连续时间。由于扩散模型的灵活性,许多经验方法可以通过进一步分析得到加强。通过将离散时间的模型转化到对应的连续时间模型,然后再设计更多、更好的离散方法,这样的研究思路有前景。 新的生成过程。扩散模型通过两种主要方法生成样本:一是离散化反向扩散 SDE,然后通过离散的反向 SDE 生成样本;另一个是使用逆过程中马尔可夫性质对样本逐步去噪。然而,对于一些任务,在实践中很难应用这些方法来生成样本。因此,需要进一步研究新的生成过程和视角。 泛化到更复杂的场景和更多的研究领域。虽然目前 diffusion model 已经应用到多个场景中,但是大多数局限于单输入单输出的场景,将来可以考虑将其应用到更复杂的场景,比如 text-to-audiovisual speech synthesis。也可以考虑和更多的研究领域相结合。
“整理不易,点赞三连↓
评论