
用python写一个图像文字识别OCR工具

向AI转型的程序员都关注了这个号👇👇👇
什么是OCR?
OCR是英文optical character recognition的首字母缩写,中文意思:光学字符识别。或者我们管它叫做:文字识别。文字识别是指电子设备(例如扫描仪或数码相机)检查纸上打印的字符,然后用字符识别方法将形状翻译成计算机文字的过程;即,对文本资料进行扫描,然后对图像文件进行分析处理,获取文字及版面信息的过程。通俗理解,举个例子:就是把图片\PDF里的文字信息进行抓取,转换成Word、TXT等可以编辑的文字文本。
扫描文档仅仅呈现纸质文档最原始的图像形式,由于文本无法被软件读取,从扫描文档中提取信息通常需要耗时耗力的手动工作。工作量大且容易出错。然而,通过光学字符识别 (OCR)可识别获取文档内容,将其自动转化为可搜索的文字文档,如word/PDF,转换后的文档可以作为数据保存,大幅降低劳动力,提高工作效率。
衡量一个OCR系统性能好坏的主要指标有:拒识率、误识率、识别速度、用户界面的友好性,产品的稳定性,易用性及可行性等。
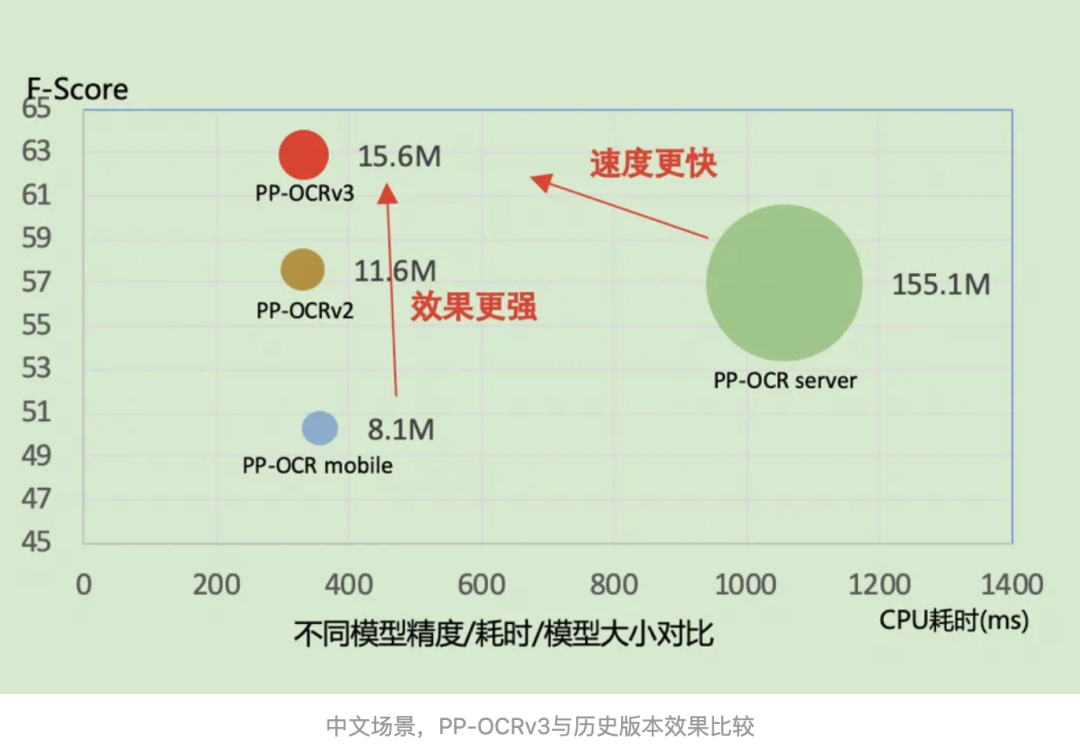
PP-OCR是PaddleOCR团队自研的超轻量OCR系统,面向OCR产业应用,权衡精度与速度。近期,PaddleOCR团队针对PP-OCRv2的检测模块和识别模块,进行共计9个方面的升级,打造出一款全新的、效果更优的超轻量OCR系统:PP-OCRv3。
从效果上看,速度可比情况下,多种场景精度均有大幅提升:
-
中文场景,相比于PP-OCRv2中文模型提升超5%;
-
英文数字场景,相比于PP-OCRv2英文数字模型提升11%;
-
多语言场景,优化80+语种识别效果,平均准确率提升超5%。
-

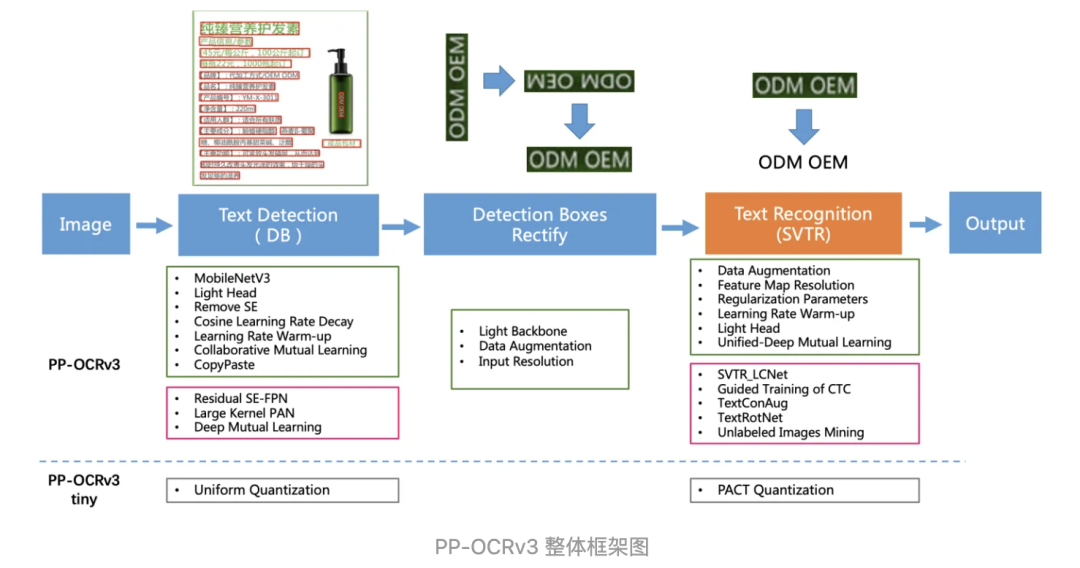
全新升级的PP-OCRv3的整体的框架图(粉色框中为PP-OCRv3新增策略)如下图。检测模块仍基于DB算法优化,而识别模块不再采用CRNN,更新为IJCAI 2022最新收录的文本识别算法SVTR (论文名称:SVTR: Scene Text Recognition with a Single Visual Model ),并对其进行产业适配。
最近在技术交流群里聊到一个关于图像文字识别的需求,在工作、生活中常常会用到,比如票据、漫画、扫描件、照片的文本提取。
基于 PyQt + labelme + PaddleOCR 写了一个桌面端的OCR工具,用于快速实现图片中文本区域自动检测+文本自动识别。
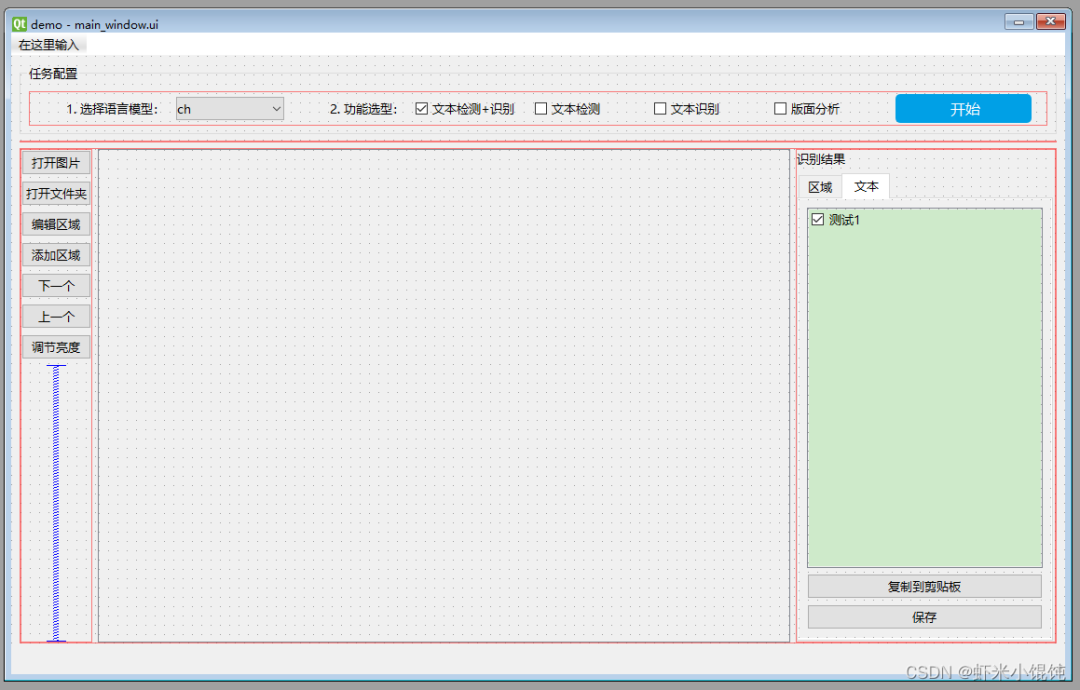
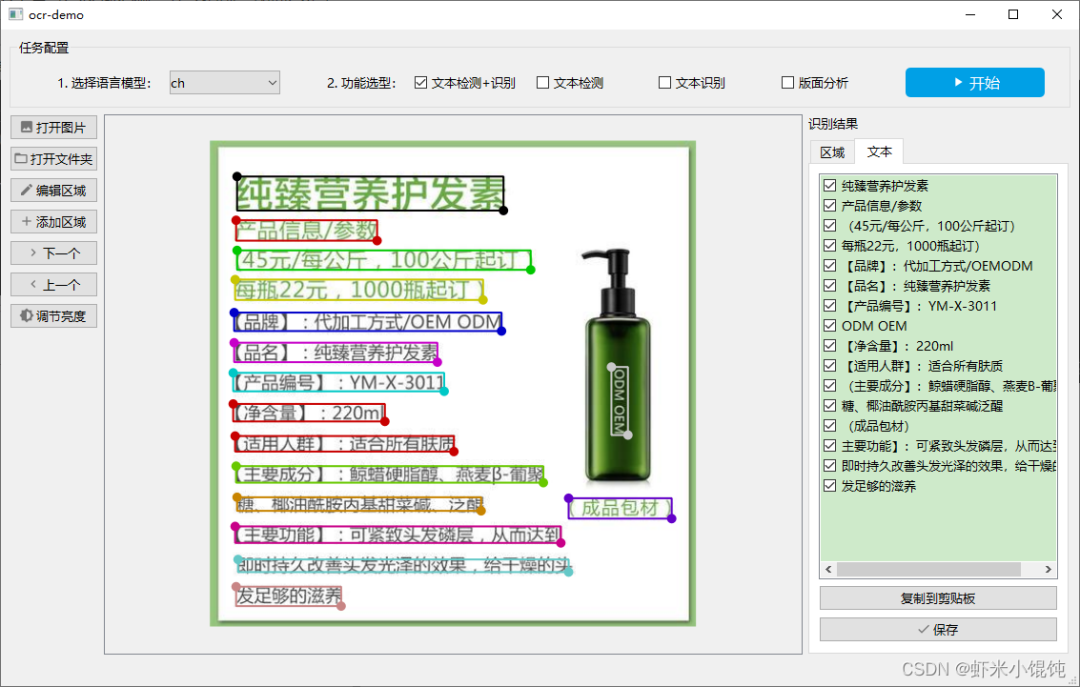
识别效果如下图所示:
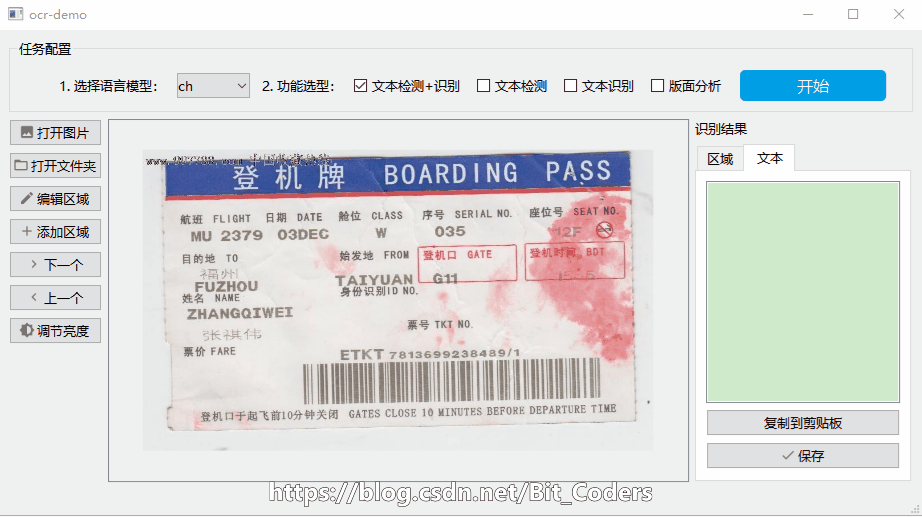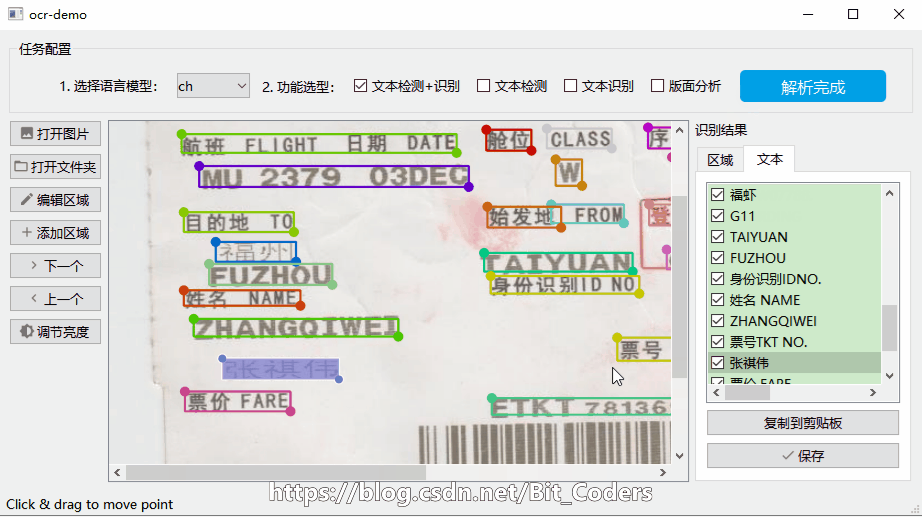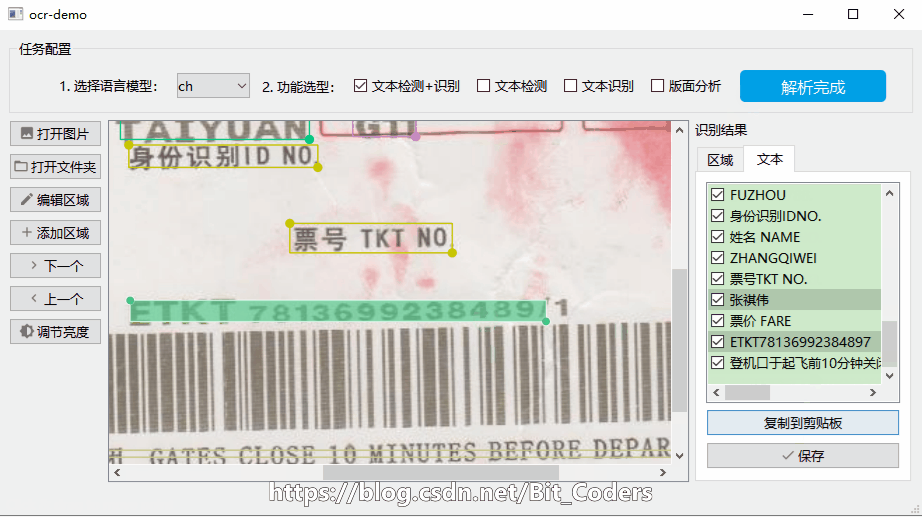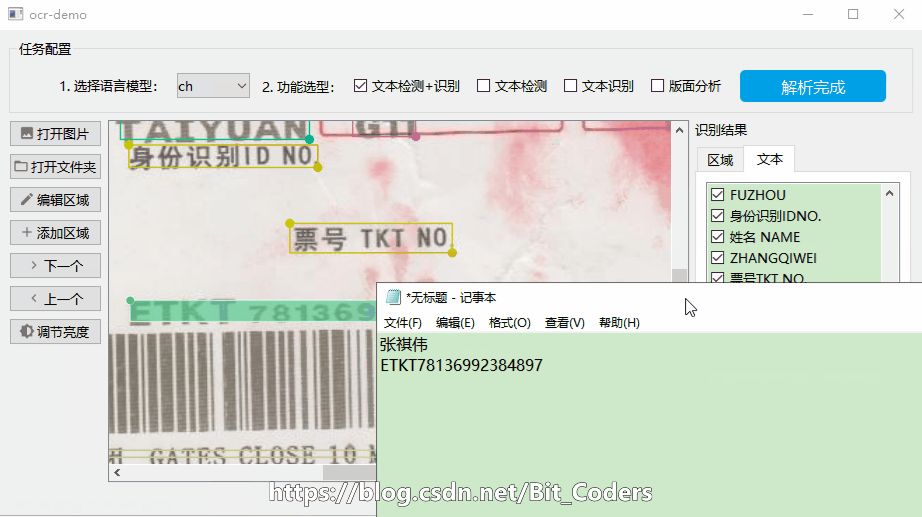
所有框选区域为OCR算法自动检测,右侧列表有每个框对应的文字内容;
点击右侧“识别结果”中的文本记录,然后点击“复制到剪贴板”即可复制该文本内容。
功能列表
文本区域检测+文字识别
文本区域可视化
文字内容列表
图像、文件夹加载
图像滚轮缩放查看
绘制区域、编辑区域
复制所选文本识别结果
OCR部分
图像文字检测+文字识别算法,主要借助 paddleocr 实现。
创建或者选择一个虚拟环境,安装需要用到的第三方库。
conda create -n ocr conda activate ocr
安装框架
如果你没有NVIDIA GPU,或GPU不支持CUDA,可以安装CPU版本:
# CPU版本
pip install paddlepaddle == 2.1 .0
-i https://mirror.baidu.com/pypi/simple
如果你的GPU安装过CUDA9或CUDA10,cuDNN 7.6+,可以选择下面这个GPU版本:
# GPU版本 python3 -m
pip install paddlepaddle-gpu == 2.1 .0
-i https://mirror.baidu.com/pypi/simple
安装 PaddleOCR
安装paddleocr:
pip install "paddleocr>=2.0.1" # 推荐使用2.0.1+版本
版面分析,需要安装 Layout-Parser:
pip3 install -U https://paddleocr.bj.bcebos.com/whl/layoutparser-0.0.0-py3-none-any.whl
测试安装是否成功
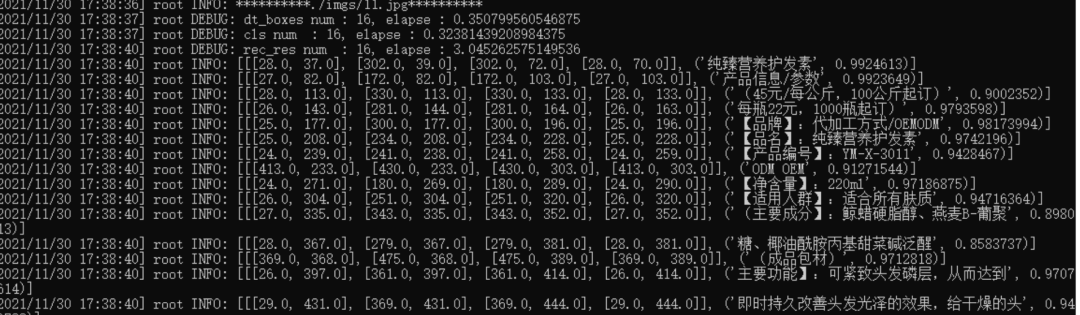
安装完成后,测试一张图片--image_dir ./imgs/11.jpg,采用中英文检测+方向分类器+识别全流程:
paddleocr --image_dir ./imgs/11.jpg --use_angle_cls true --use_gpu false
输出一个list:
在python中调用
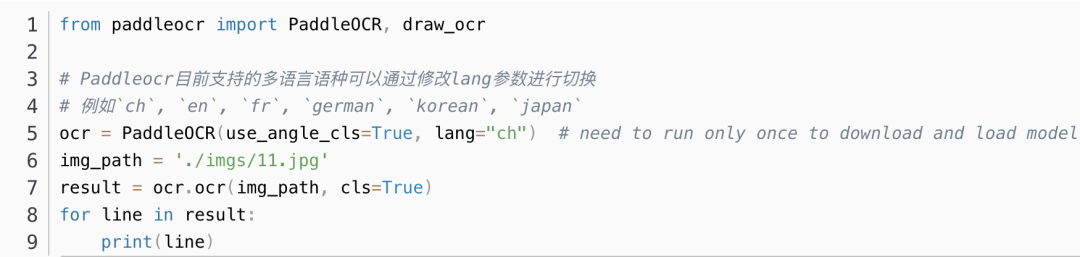
输出结果是一个list,每个item包含了文本框,文字和识别置信度:

界面部分
界面部分基于 pyqt5 实现。
pyqt GUI程序开发入门和环境配置,详见这篇博客。
https://blog.csdn.net/Bit_Coders/article/details/119304488
主要步骤:
1. 界面布局设计
在QtDesigner中拖拽控件,完成程序界面布局,并保存*.ui文件。
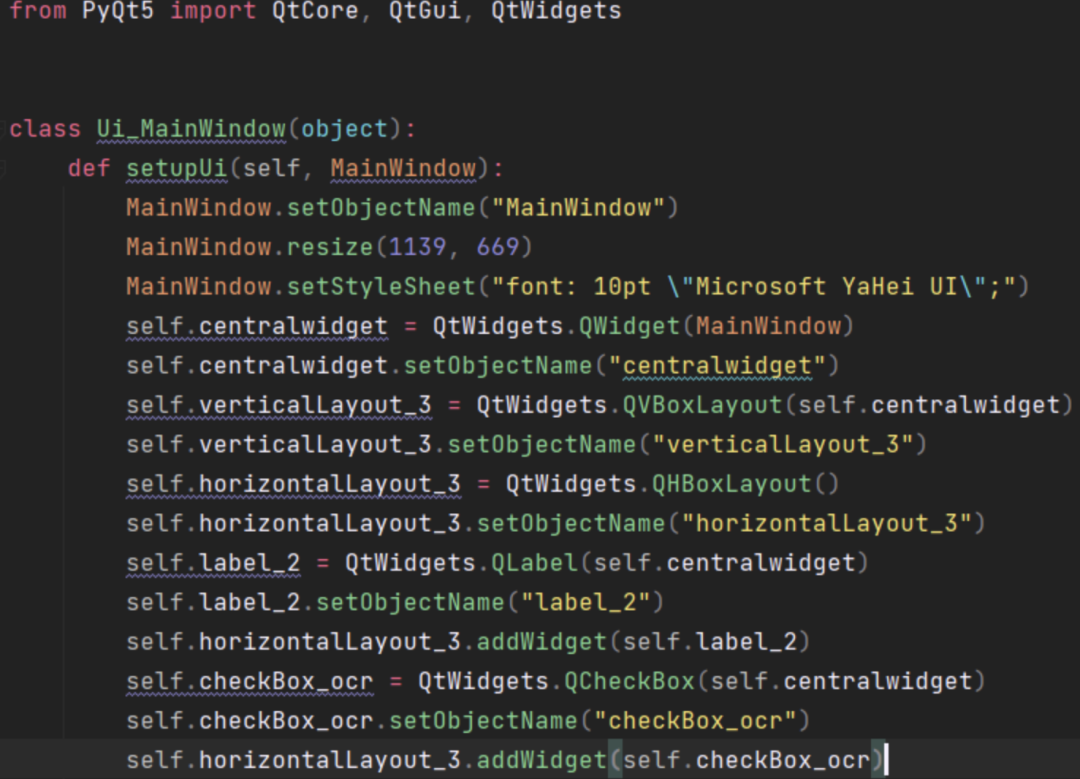
2. 利用 pyuic 自动生成界面代码
在 pycharm 的项目文件结构中找到*.ui文件,右键——External Tools——pyuic,会在ui文件同级目录下自动生成界面 ui 的 python 代码。
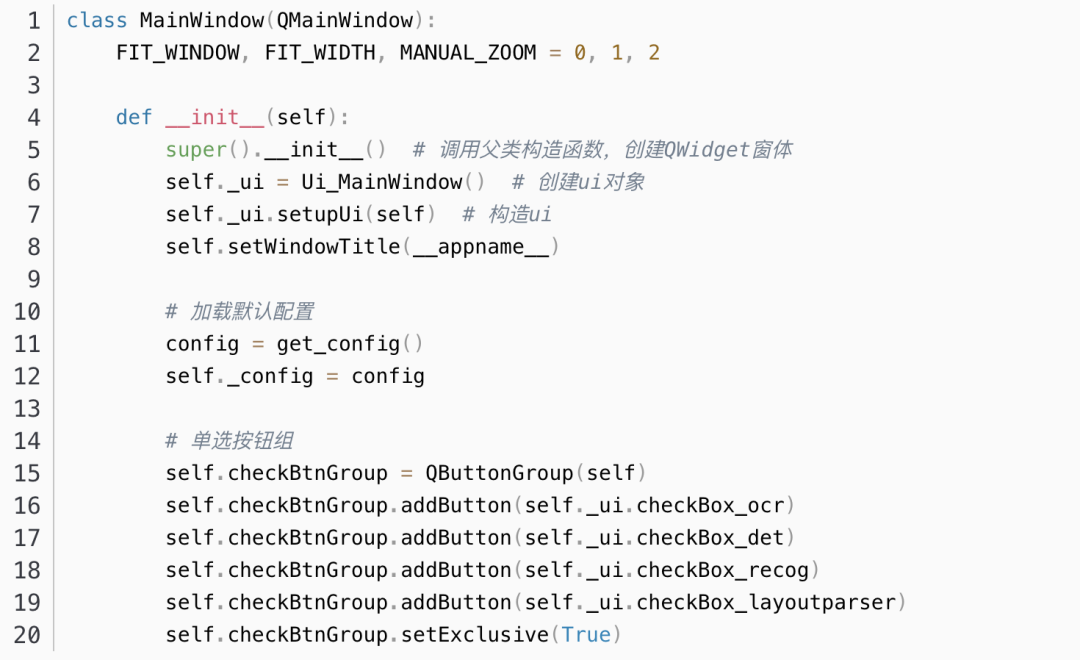
3. 编写界面业务类
业务类 MainWindow 实现程序逻辑和算法功能,与前面第2步生成的ui实现解耦,避免每次修改ui文件会影响业务代码。ui界面上的控件可以通过self._ui.xxxObjectName 访问。
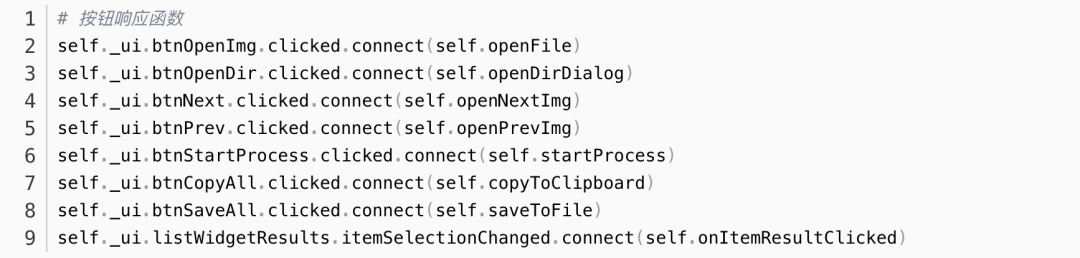
4. 实现界面业务逻辑
对主界面上的按钮、列表、绘图控件进行信号槽连接。自定义的槽函数不用专门声明,如果是自定义的信号,需要在类__init__()前加上 yourSignal= pyqtSignal(args)。
这里以按钮响应函数、列表响应函数为例。按钮点击的信号是 clicked,listWidget列表切换选择的信号是 itemSelectionChanged 。
5. 运行看看效果
运行 python main.py 即可启动GUI程序。
打开图片→选择语言模型ch(中文)→选择文本检测+识别→点击开始,检测完的文本区域会自动画框,并在右侧识别结果——文本Tab页的列表中显示。
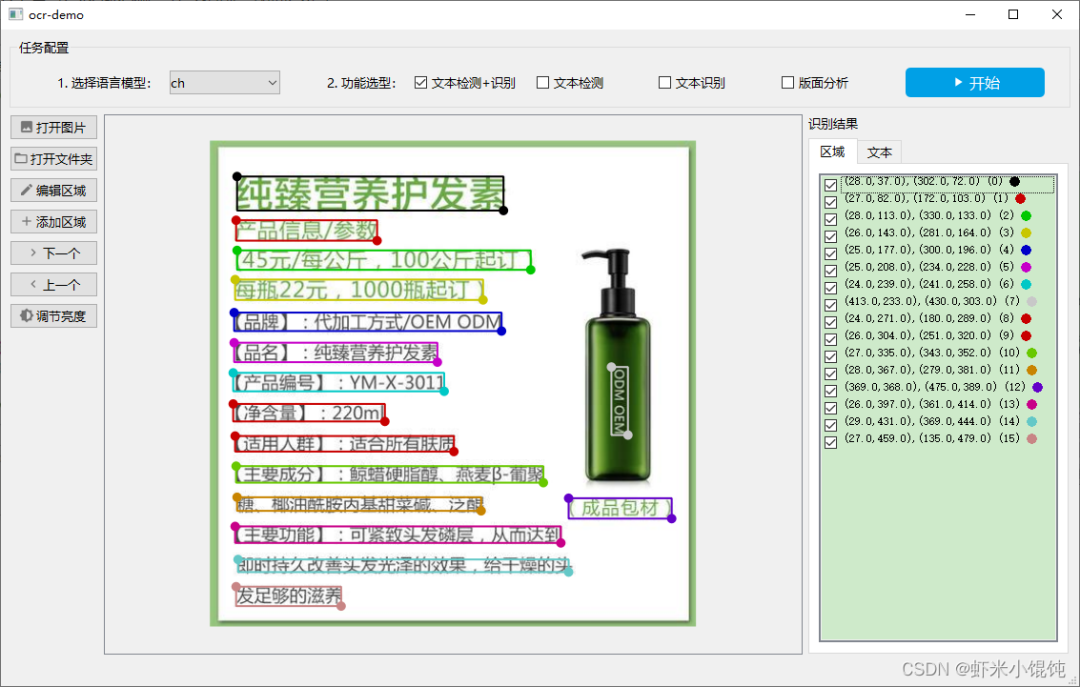
所有检测出文本的区域列表,在识别结果——区域Tab页:
原文地址
https://blog.csdn.net/Bit_Coders/article/details/121561632
机器学习算法AI大数据技术
搜索公众号添加: datanlp
长按图片,识别二维码
阅读过本文的人还看了以下文章:
基于40万表格数据集TableBank,用MaskRCNN做表格检测
《深度学习入门:基于Python的理论与实现》高清中文PDF+源码
2019最新《PyTorch自然语言处理》英、中文版PDF+源码
《21个项目玩转深度学习:基于TensorFlow的实践详解》完整版PDF+附书代码
PyTorch深度学习快速实战入门《pytorch-handbook》
【下载】豆瓣评分8.1,《机器学习实战:基于Scikit-Learn和TensorFlow》
李沐大神开源《动手学深度学习》,加州伯克利深度学习(2019春)教材
【Keras】完整实现‘交通标志’分类、‘票据’分类两个项目,让你掌握深度学习图像分类
如何利用全新的决策树集成级联结构gcForest做特征工程并打分?
Machine Learning Yearning 中文翻译稿
斯坦福CS230官方指南:CNN、RNN及使用技巧速查(打印收藏)
中科院Kaggle全球文本匹配竞赛华人第1名团队-深度学习与特征工程
不断更新资源
深度学习、机器学习、数据分析、python
搜索公众号添加: datayx