
Elasticsearch 断路器报错了,怎么办?
共 3556字,需浏览 8分钟
·
2022-02-17 16:45
1、引言
本系列文章介绍如何修复 Elasticsearch 集群的常见错误和问题。
这是系列文章的第三篇,主要探讨:Elasticsearch 断路器报错了,怎么办?
第一篇: Elasticsearch 磁盘使用率超过警戒水位线,怎么办?
第二篇:Elasitcsearch CPU 使用率突然飙升,怎么办?
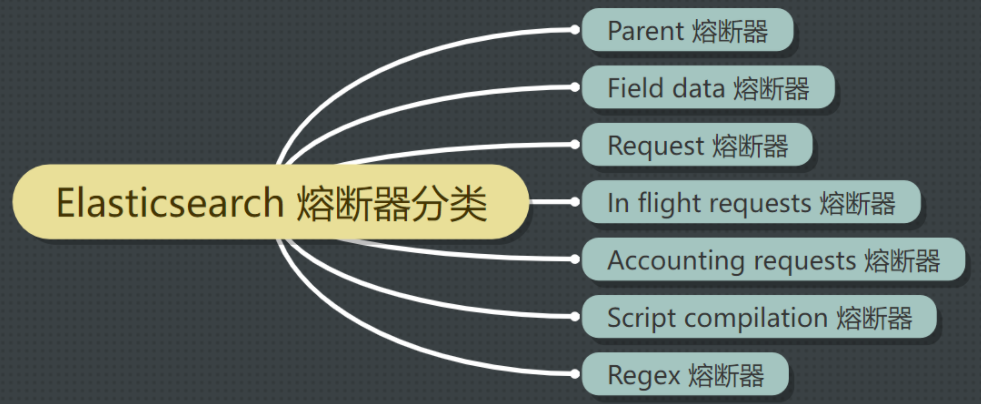
2、 啥是断路器?
断路器(circuit breakers)都指定了它可以使用内存的限制。
Elasticsearch 包含多个断路器,用于防止操作导致内存泄露错误(OutOfMemoryError)。
此外,还有一个父级断路器(parent-level breaker),规定了所有断路器可以使用的内存总量。
如果Elasticsearch估计某项操作会导致内存使用率超过断路器设置的上限,它会停止操作并返回错误。
默认情况下,父级断路器在 JVM 内存使用率达到 95% 时触发。为了防止错误,官方建议在使用率持续超过 85% 的情况下,采取措施减少内存压力。
3、Elasticsearch 断路器报错示例
3.1 客户端请求报 429 错误
如果一个请求触发了一个断路器,Elasticsearch会返回一个错误,其 HTTP 状态代码为429。
{
'error': {
'type': 'circuit_breaking_exception',
'reason': '[parent] Data too large, data for [] would be [123848638/118.1mb], which is larger than the limit of [123273216/117.5mb], real usage: [120182112/114.6mb], new bytes reserved: [3666526/3.4mb]' ,
'bytes_wanted': 123848638,
'bytes_limit': 123273216,
'durability': 'TRANSIENT'
},
'status': 429
}
熟悉Http 协议的同学都知道:在HTTP协议中,响应状态码 429 Too Many Requests 表示在一定的时间内用户发送了太多的请求,即超出了“频次限制”。
3.2 日志报错 Data too large
elasticsearch.log 也会记录断路器错误。例如:分片的过程中会触发断路器。
可能的报错如下:
Caused by: org.elasticsearch.common.breaker.CircuitBreakingException: [parent] Data too large, data for [] would be [num/numGB], which is larger than the limit of [num/numGB], usages [request=0/0b, fielddata=num/numKB, in_flight_requests=num/numGB, accounting=num/numGB]
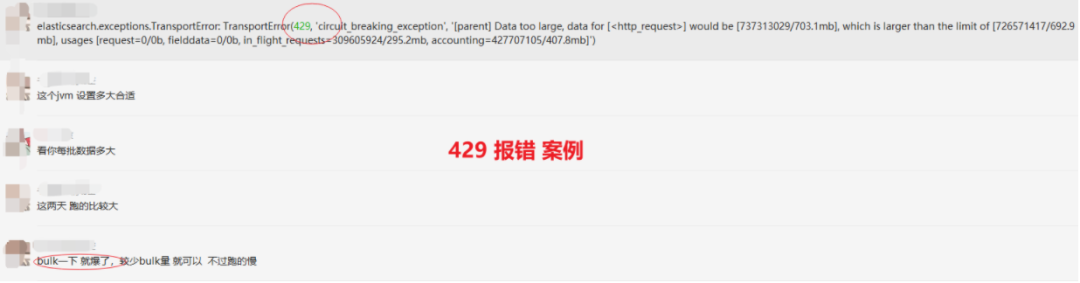
——来自《死磕Elasticsearch 知识星球》
4、检查JVM的内存使用情况
4.1 在kibana 中查看 JVM 使用率
Step1:先实现个小目标:构造1个亿+的数据

光速达成一个亿小目标,如下图所示:

step2:构造检索语句
wildcard bool 组合前缀查询语句曾经导致我线上显示环境宕机,我记忆犹新,今天就构造它!
关于 wildcard,推荐阅读:Elasticsearch 警惕使用 wildcard 检索!然后呢?
我初步构造了 bool 组合 416个(400+,416是自己随机构造的)wildcard 检索语句。
python 打印 DSL 部分截图
kibana DSL 执行类似如下截图:

DSL 部分截图
我用 python 脚本实现,这种检索非常耗时,超时时间我设置的是:20000s,确保不超时且确保可以拿回结果。
执行结果部分截图如下:
执行结果图
第一列是:评分;
第二列是:name名称(写入时随机构造生成的)。
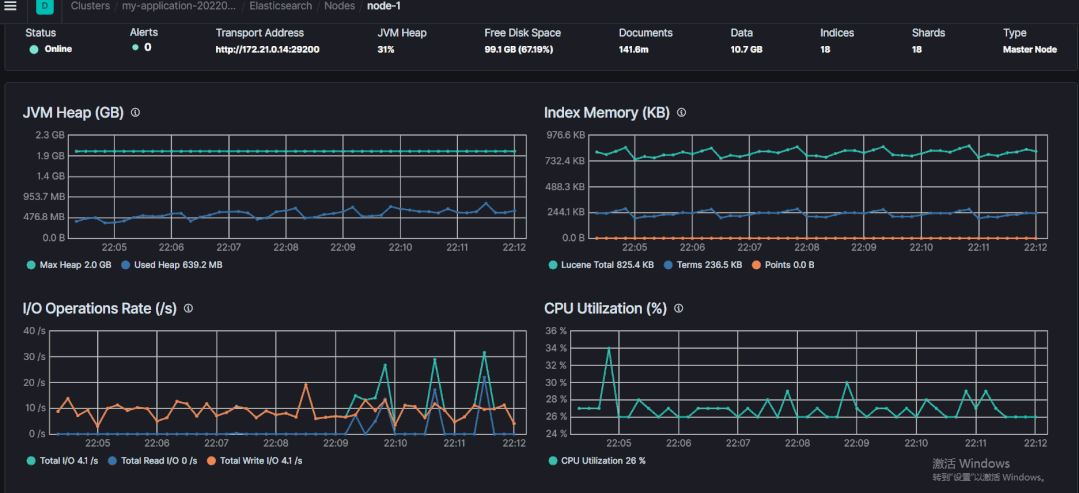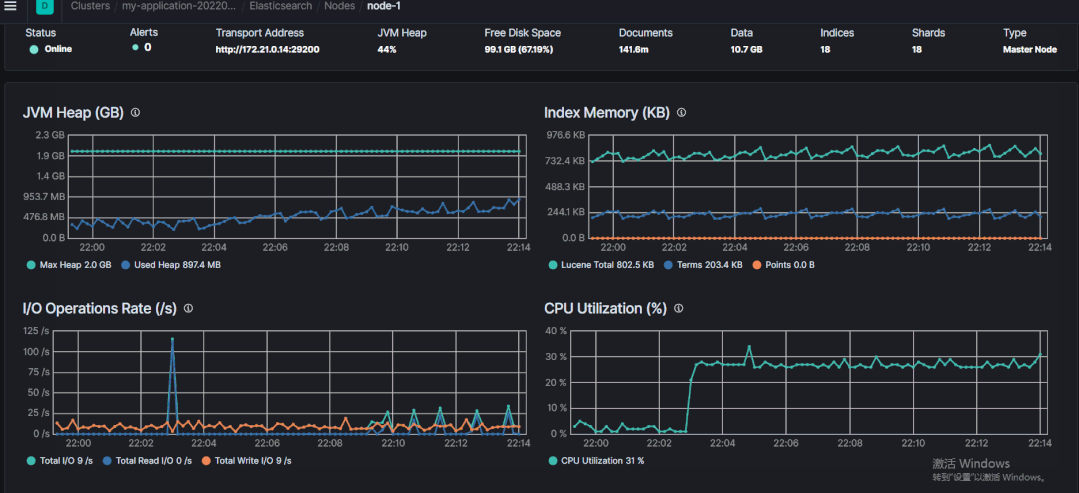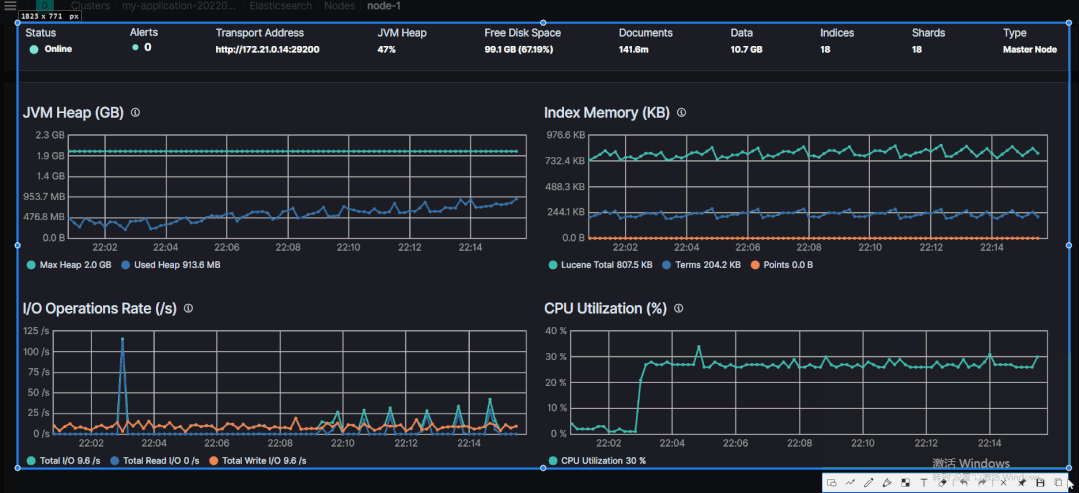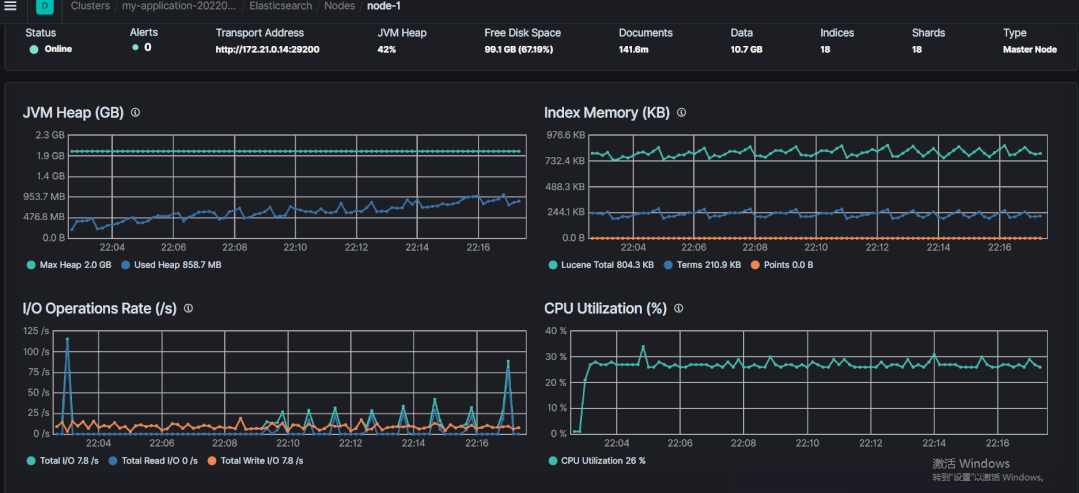
step3:检索前观察 JVM 使用率。
22:03 分左右开始的检索,下图是开始检索前的截图,JVM Heap 使用率 13%左右。
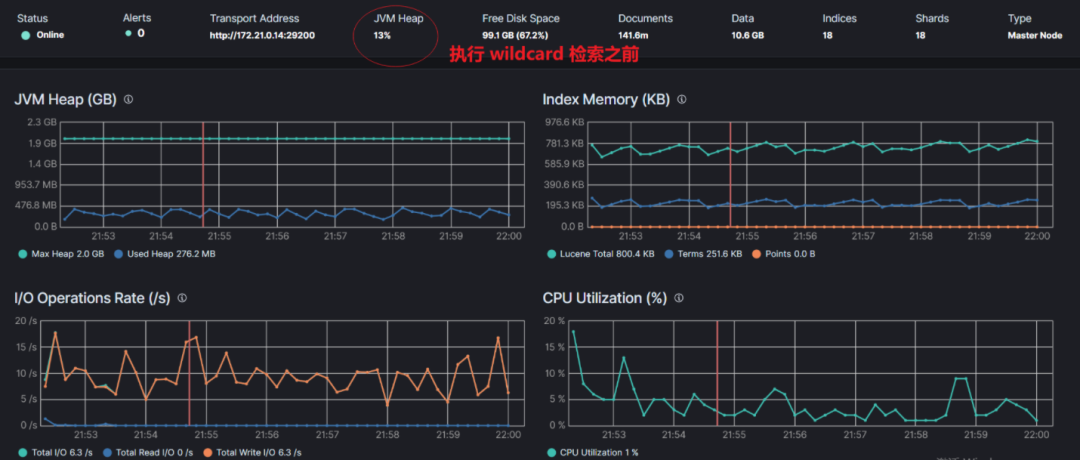
step3:检索前观察 JVM 使用率。
执行 wildcard 前缀查询之后的召回数据前的时间段。
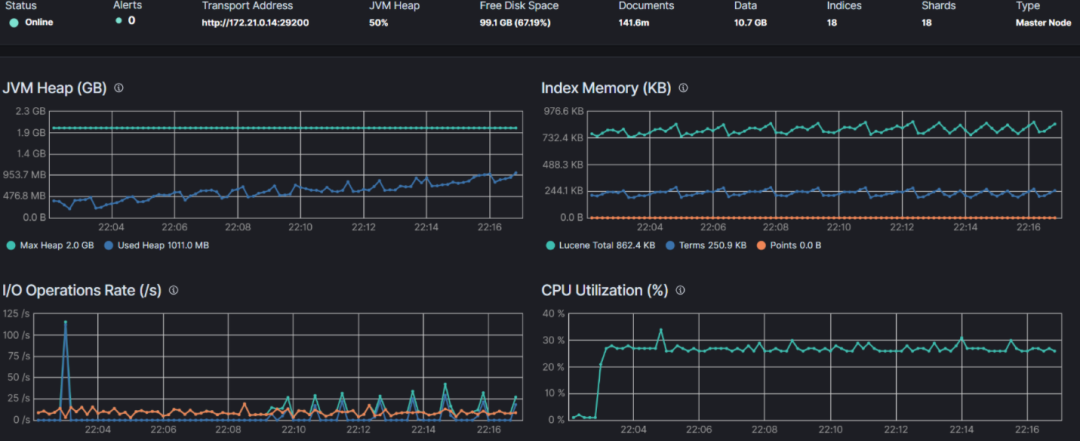
JVM Heap 使用率 50% 左右。
明显看到一段上升的变化曲线。
Step4:部分执行
PS:执行检索过程结果召回前的部分 Gif 动图如下:
4.2 使用命令行查看 JVM 使用率
使用 cat nodes API 来获得每个节点的当前堆内存使用率 heap.percent。
GET _cat/nodes?v=true&h=name,node*,heap*
返回结果如下:
name id node.role heap.current heap.percent heap.max
node-02 WCwv cdfhilmrstw 287mb 28 990.7mb
要获得每个断路器的 JVM 内存使用量,请使用节点统计 node stats API。
GET _nodes/stats/breaker
返回结果如下:
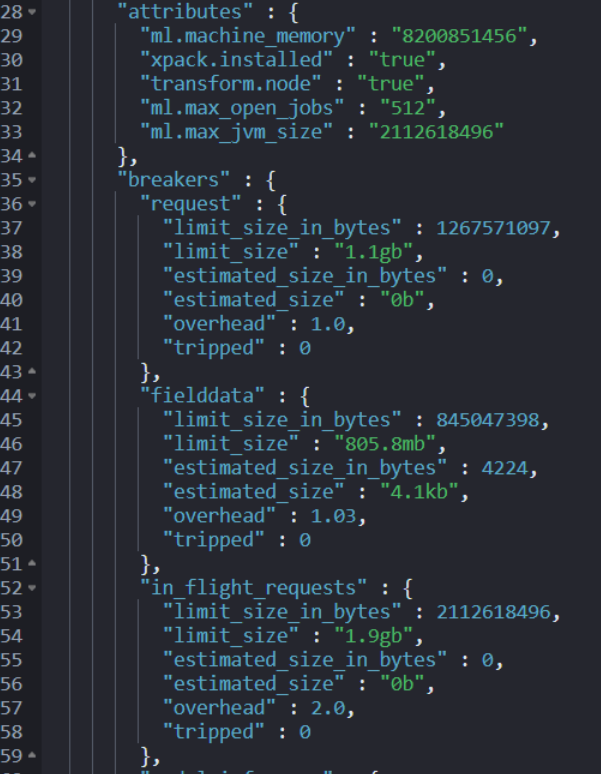
5、如何防止断路器出错?
5.1 降低JVM的内存压力
高的 JVM 内存压力经常导致断路器错误。可能导致 JVM 使用率暴增的原因列举如下:
原因 1:分片大小设置不合理,存在过多小分片。
因为每个分片都会有内存的使用。官方建议分片大小 30GB-50GB之间。
原因 2:复杂的检索或查询操作。
举例:wildcard 查询、设置很大分桶数的聚合操作都是非常“吃”内存的,要避免。
原因 3:存在映射“爆炸”现象
定义太多的字段或将字段嵌套得太深,会导致使用大量内存的映射“爆炸”。
原因 4:存在大型批量请求
大型的批量索引或多重搜索请求会造成 JVM 的内存压力。
原因 5:节点硬件资源受限
物理内存本身就很小,这种是“硬伤”,为避免后患,需要整个团队知悉并想办法协调解决。
5.2 避免在 text 类型字段上使用 fielddata
读者们还有没有印象,长津湖影评词云效果,就必须得开启 fielddata:true。

本质原因:需要对 text 字段进行聚合操作,默认 text 是做分词操作的,无法实现聚合和排序,只有 fielddata:true 开启后才可以。
但,开启 fielddate:true 会使用大量的 JVM 内存。为了避免这种情况,建议 Elasticsearch 默认在文本字段上禁用 fielddata。
官方建议:如果你已经启用了 fielddata 并触发了 fielddata 断路器,请考虑禁用它并使用关键字字段 keyword 代替。
5.3 清除 fieldata 缓存
如果你已经触发了 fielddata 断路器并且不能禁用 fielddata,需要使用清除缓存 API 来清除 fielddata 缓存。
清理缓存的命令如下:
POST _cache/clear?fielddata=true
更多缓存相关的操作,推荐阅读:
6、小结
提前知道哪些常见问题容易导致熔断器报错,能有效的指导实战工作、避免实战环境出现类似错误。
你的实战环境有没有遇到类似错误,如何解决的呢?欢迎留言交流。
参考
https://www.elastic.co/guide/en/elasticsearch/reference/current/fix-common-cluster-issues.html https://www.elastic.co/guide/en/elasticsearch/reference/current/circuit-breaker.html
推荐
更短时间更快习得更多干货!
已带领88位球友通过 Elastic 官方认证!
