
员工流动分析和预测
公司员工,是一家公司成长和发展的关键要素之一。留不住优秀的员工,也就难以打造出卓越的公司。很多公司,比方说,惠普公司,IBM公司等,已经采用数据科学的手段,对内部员工的流动做分析和预测,并且进行提前的干预,以最小化员工流动所带来的的影响。
本文是关于员工流动分析和预测的案例,通过阅读,可以得到:
需要解决什么问题?
描述员工流动的特征或者标签有哪些?
对于采集的数据集如何做准备工作?
如何对整理好的数据做分析和建模?
模型的效果如何评估?
模型的结果如何应用?
一、业务理解,
要解决什么问题?
根据公司员工的数据,分析和挖掘潜在流动的员工白名单,输出给人力资源部门,指导他们进行提前干预和挽留,以减少公司人员流动所带来的的损失和影响。
二、数据理解,
数据的画像问题?
本案例的数据集来自Kaggle平台提供一份公司人员流动数据。这份数据集包括18列,用于记录公司员工的相关信息。目标变量是status记录了两种状态,取值是ACTIVE和TERMINATED。其它列可以从后面代码里面了解。
1、导入Python库
import random
import time as time
from datetime import timedelta
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn import model_selection
from sklearn.preprocessing import MinMaxScaler
from sklearn.preprocessing import StandardScaler
from sklearn.preprocessing import Normalizer
from sklearn.pipeline import Pipeline
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import classification_report
from sklearn.metrics import confusion_matrix
from sklearn.metrics import accuracy_score
from sklearn.exceptions import DataConversionWarning
import warnings
def disable_DataConversionWarning():
warnings.filterwarnings(action='ignore', category=DataConversionWarning)
def disable_FutureWarning():
warnings.filterwarnings(action='ignore', category=FutureWarning)
def enable_All_Warning():
warnings.simplefilter('always')
get_ipython().run_line_magic('matplotlib', 'inline')
2、导入数据集
file = './datasets/MFG10YearTerminationData.csv'
data = pd.read_csv(filepath_or_buffer=file, header=0, sep=',')
print('数据检视:输出数据集前5行...')
data.head(5)
3、元数据理解
print('样本数:', data.shape[0])
print('变量数:', data.shape[1])
print('变量的数据类型:')
print(data.dtypes)
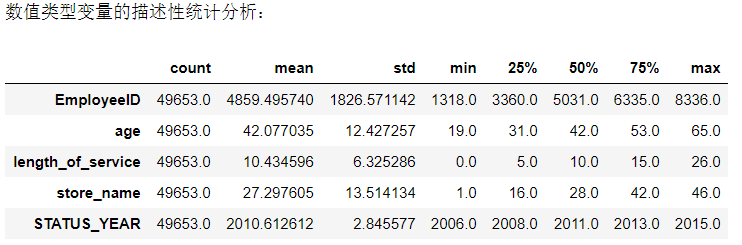
4、数值型变量描述性统计分析
print('数值类型变量的描述性统计分析:')
data.describe().T
三、数据准备,
数据如何整理好?
这份数据集有很多变量的取值是文本信息,为了能够使用它做分析和建模。我们需要做编码处理。这里采用了一种简单的处理策略,即基于领域知识把一些类别变量进行标签编码。同时,删除ID列,对目标变量列也进行编码处理。对整理好的数据集,进行可视化分析,以加深对数据进一步认知和理解。
5、类别变量的标签编码
第一步:把所需的对象变量强制转换为类别变量;第二步:对类别变量进行标签编码映射,从而转换为数值变量。
# 第一步:对象转换为类别变量
data["city_name"] = data["city_name"].astype('category')
data["department_name"] = data["department_name"].astype('category')
data["job_title"] = data["job_title"].astype('category')
data["gender_short"] = data["gender_short"].astype('category')
data["termreason_desc"] = data["termreason_desc"].astype('category')
data["termtype_desc"] = data["termtype_desc"].astype('category')
data["BUSINESS_UNIT"] = data["BUSINESS_UNIT"].astype('category')
# 第二步:类别变量做标签编码
data["city_name_NUMERIC"] = data["city_name"].cat.codes
data["department_name_NUMERIC"] = data["department_name"].cat.codes
data["job_title_NUMERIC_NUMERIC"] = data["job_title"].cat.codes
data["gender_short_NUMERIC"] = data["gender_short"].cat.codes
data["termreason_desc_NUMERIC"] = data["termreason_desc"].cat.codes
data["termtype_desc_NUMERIC"] = data["termtype_desc"].cat.codes
data["BUSINESS_UNIT_NUMERIC"] = data["BUSINESS_UNIT"].cat.codes
6、移除ID列和目标变量编码
# 移除ID列
data = data.drop(columns=['EmployeeID'])
# 目标变量类型转换
data['ClasseNumerica'] = np.where(data['STATUS']=='ACTIVE', 1, 0)
data.tail(15)
7、目标变量分布情况
print('-> 目标变量类别的分布情况:')
QtdObservacoes = data.shape[0]
QtdValClasse = data['STATUS'].unique().size
count = 0
print('样本数:', QtdObservacoes)
while count < QtdValClasse:
print(data['STATUS'].unique()[count], ':', (data.groupby('STATUS').size())[count], '(', (((data.groupby('STATUS').size())[count]/ (QtdObservacoes)) * 100), '% )')
count = count + 1

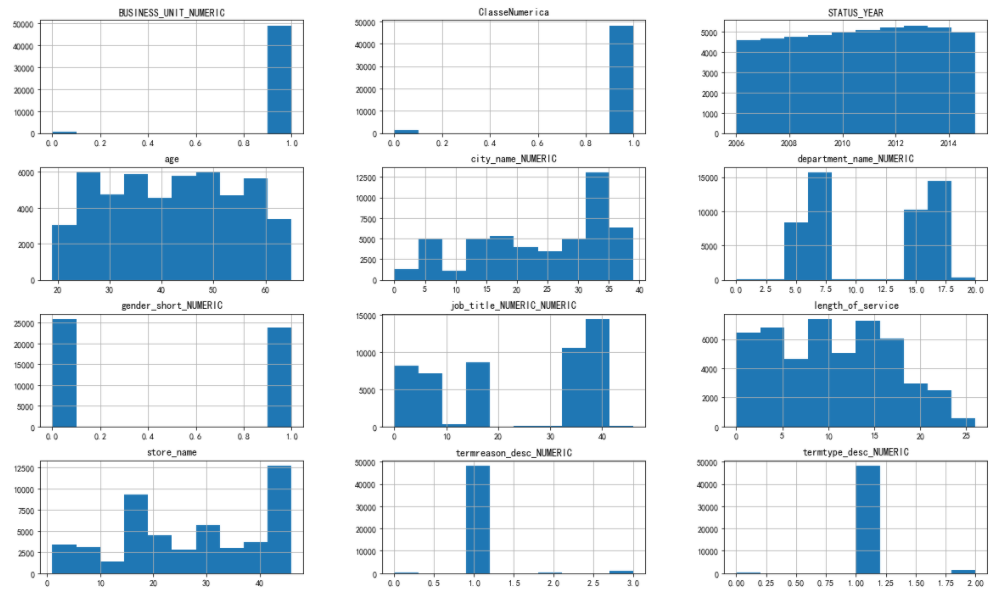
8、数据可视化分析
1)单变量分析
data.hist(sharex=False, sharey=False, figsize=(20,12), grid=True)
plt.show()
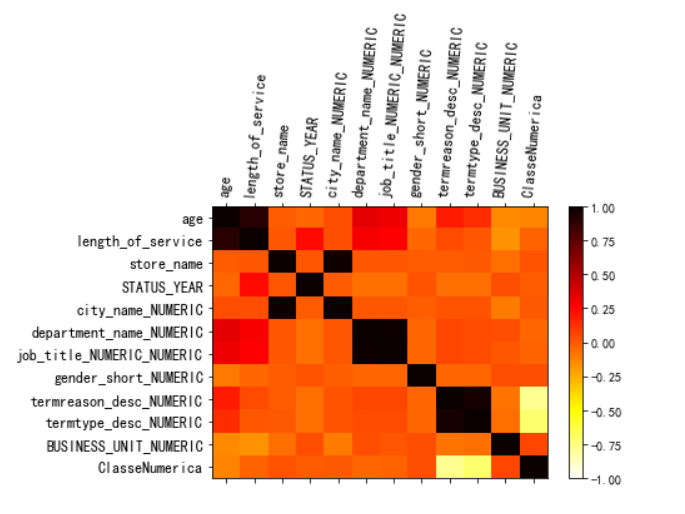
2)数值型变量相关系数矩阵可视化
# 相关系数矩阵
ColunaNumericas = (data._get_numeric_data()).columns.tolist() #获取数值型变量集
QtdTotalElementos = len(ColunaNumericas)
values_corr = data.corr() #生成相关性系数矩阵
# 相关性系数矩阵可视化
fig = plt.figure() # 构建图表
ax = fig.add_subplot(1,1,1)
correlation_matrix = ax.matshow(values_corr
,vmin = -1
,vmax = 1
,interpolation = 'none'
,cmap = 'hot_r' #'hot_r', 'pink_r', 'spring', 'spring_r'
,aspect='auto'
#,alpha = 0.75
,origin = 'upper'
) #matshow -> 把数组或者矩阵绘制为图形
fig.colorbar(correlation_matrix)
ticks = np.arange(0, QtdTotalElementos, 1)
ax.set_xticks(ticks)
ax.set_yticks(ticks)
ax.set_xticklabels(labels=ColunaNumericas, rotation=85, fontsize=12)
ax.set_yticklabels(labels=ColunaNumericas, fontsize=12)
plt.show()
3)观察一些预测预测变量和目标变量的关系
# 可视化一些预测变量和目标变量的关系
ColunaNumericas = ['STATUS_YEAR', 'age', 'length_of_service', 'store_name', 'city_name_NUMERIC']
dataframe = data[ColunaNumericas]
dataframe = dataframe.assign(Classe=data['STATUS']) # 往数据框中添加新列
sns.pairplot(data=dataframe, hue="Classe", kind='scatter', palette="cubehelix")

9、类别不平衡问题的处理
通过类别变量取值分布,发现有类别不平衡问题。处理策略,采用一种欠抽样的方法。具体操作:目标变量为离职的所有数据集+在职数据集随机抽取5000条记录以构成训练集。
ColunaNumericas = (data._get_numeric_data()).columns.tolist()
QtColunasNumericas = len(ColunaNumericas)
df_ALL_TERMINATED = data[data['ClasseNumerica'] == 0]
df_ALL_ACTIVE = data[data['ClasseNumerica'] == 1]
df_ALL_TERMINATED = (df_ALL_TERMINATED[ColunaNumericas])
df_ALL_ACTIVE = (df_ALL_ACTIVE[ColunaNumericas])
preditoras_ALL_TERMINATED = df_ALL_TERMINATED.values[:,:-1]
preditoras_ALL_ACTIVE = df_ALL_ACTIVE.values[:,:-1]
alvo_ALL_TERMINATED = df_ALL_TERMINATED.values[:,-1:QtColunasNumericas]
alvo_ALL_ACTIVE = df_ALL_ACTIVE.values[:,-1:QtColunasNumericas]四、模型构建和评价,
如何创建最佳模型?
对于整理好的数据集,首先把数据集划分为训练集和测试集,然后利用交叉验证的思想选择最佳模型,第三,使用最佳模型对训练集做模型构建,第四,利用测试集对模型的性能做评价。
10、训练集和测试集
random.seed(1)
# 训练集
preditoras_5000_INSTANCES_ACTIVE = np.array( random.sample(population = list(preditoras_ALL_ACTIVE), k = 5000))
preditoras_treino = np.concatenate([preditoras_ALL_TERMINATED, preditoras_5000_INSTANCES_ACTIVE])
# 测试集
preditoras_1000_INSTANCES_TERMINATED = np.array( random.sample(population = list(preditoras_ALL_TERMINATED), k = 1000) )
preditoras_40000_INSTANCES_ACTIVE = np.array( random.sample(population = list(preditoras_ALL_ACTIVE), k = 40000) )
preditoras_teste = np.concatenate([preditoras_1000_INSTANCES_TERMINATED, preditoras_40000_INSTANCES_ACTIVE])
# 训练集目标变量
alvo_treino_5000_INSTANCES_ACTIVE = np.array( random.sample(population = list(alvo_ALL_ACTIVE), k = 5000) )
alvo_treino = np.concatenate([alvo_ALL_TERMINATED, alvo_treino_5000_INSTANCES_ACTIVE])
# 测试集目标变量
alvo_1000_INSTANCES_TERMINATED = np.array( random.sample(population = list(alvo_ALL_TERMINATED), k = 1000) )
alvo_40000_INSTANCES_ACTIVE = np.array( random.sample(population = list(alvo_ALL_ACTIVE), k = 40000) )
alvo_teste = np.concatenate([alvo_1000_INSTANCES_TERMINATED, alvo_40000_INSTANCES_ACTIVE])
11、交叉验证做模型的选择
# 交叉验证--模型的选择
# 显示模型的性能分析
disable_DataConversionWarning()
disable_FutureWarning()
# 根据每种算法创建机器学习模型
# 使用accuracy指标做度量,值越大,模型性能越好
modelos = []
modelos.append(('LogisticRegression', LogisticRegression()))
modelos.append(('KNeighborsClassifier', KNeighborsClassifier()))
modelos.append(('DecisionTreeClassifier', DecisionTreeClassifier()))
resultados = []
nomes = []
modelos_nome = []
mensagens = []
tempo = []
n_folds = 10
seed = 7
for nome, modelo in modelos:
# 设置处理开始的时间
start_time = time.time()
# 创建交叉验证 10折交叉验证
k_folds = model_selection.KFold(n_splits = n_folds, random_state = seed)
# 创建模型
result_saida = model_selection.cross_val_score(modelo
,preditoras_treino
,alvo_treino
,cv = k_folds
#,n_jobs = -1
,scoring = 'accuracy'
#,verbose = 5
)
#记录模型名称
modelos_nome.append(nome)
#记录模型结果
resultados.append(result_saida * 100)
#输出最终消息
mensagens.append('模型: %s \n\n性能平均值: %.2f%%\n性能标准差: %.2f%%' % (modelo, (result_saida.mean()*100), (result_saida.std()*100)))
# 执行模型所需要的时间
tempo.append(time.time() - start_time)
qtd_mensagens = len(mensagens)
iterador = 0
print('---> 准确性描述评估 <---')
while qtd_mensagens > iterador:
print('--------------------------------------------------------------------', '\n')
print(mensagens[iterador])
print('运行的时间: %s (HH:MM:SS)' % timedelta(seconds=round(tempo[iterador])))
iterador = iterador + 1
print('--------------------------------------------------------------------')
# 模型准确性可视化比较
fig = plt.figure()
fig.suptitle('分类算法性能比较')
ax = fig.add_subplot(111)
plt.boxplot(resultados)
ax.set_xticklabels(modelos_nome)
plt.show()
enable_All_Warning()
12、最佳模型对训练集重构模型
通过交叉验证,发现决策树模型是最佳模型。我们使用决策树模型对训练数集重构模型。
# 基于模型选择里面最佳模型 决策树模型 构建预测模型
# 警告处理
disable_DataConversionWarning()
disable_FutureWarning()
# 创建管道
pipeline = []
pipeline.append(('Standardize', StandardScaler()))
pipeline.append(('ScaleFit', MinMaxScaler()))
pipeline.append(('Normalizer', Normalizer()))
pipeline.append(('DecisionTreeClassifier', DecisionTreeClassifier()))
pipeline = Pipeline(steps=pipeline)
model = pipeline.fit(preditoras_treino, alvo_treino)
13、模型的性能分析
对构建好的模型,在测试集进行模型的性能分析。可以通过模型准确率,模型混淆矩阵或者模型性能分析报告,了解所构建模型的性能状况。
previsoes = model.predict(preditoras_teste)
# 模型在测试数据集上应用
print('-> 模型的准确率:', str(round((accuracy_score(alvo_teste, previsoes)*100),2)) + '%')
print('\n-> 模型的混淆矩阵:\n', confusion_matrix(alvo_teste, previsoes), '\n')
print('-> 模型分类性能评价报告:\n\n', classification_report(alvo_teste, previsoes))五、模型的应用,
如何指导决策?
针对新的的数据集,按着模型构建前的数据加工逻辑,做好数据处理后,然后利用构建好的模型对新数据集做预测,对预测的结果做应用。
总结
通过员工流动分析和预测这个案例,我们可以了解到数据科学工作的流程,从业务问题入手,然后到数据的理解和准备,模型的构建和评价,以及模型应用和指导决策与行动,以创造价值的系统化过程。我们也可以学习到使用Python语言做数据科学工作的相关技能,包括所使用的Python库,数据画像的手段,变量类型的编码,管道式模型设计方法等。
这个案例还有很多地方值得进一步深入思考和挖掘,感兴趣的朋友可以在此基础上,做进一步的工作。比方说,数据的处理方法,类别不平衡处理,算法的设计,模型性能的提升,特征工程等课题。
附录:案例完整代码(需要数据集的朋友可以添加我的个人微信获取或者从Kaggle平台下载获取)
#!/usr/bin/env python
# coding: utf-8
import random
import time as time
from datetime import timedelta
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn import model_selection
from sklearn.preprocessing import MinMaxScaler
from sklearn.preprocessing import StandardScaler
from sklearn.preprocessing import Normalizer
from sklearn.pipeline import Pipeline
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import classification_report
from sklearn.metrics import confusion_matrix
from sklearn.metrics import accuracy_score
from sklearn.exceptions import DataConversionWarning
import warnings
def disable_DataConversionWarning():
warnings.filterwarnings(action='ignore', category=DataConversionWarning)
def disable_FutureWarning():
warnings.filterwarnings(action='ignore', category=FutureWarning)
def enable_All_Warning():
warnings.simplefilter('always')
get_ipython().run_line_magic('matplotlib', 'inline')
file = './datasets/MFG10YearTerminationData.csv'
data = pd.read_csv(filepath_or_buffer=file, header=0, sep=',')
print('数据检视:输出数据集前5行...')
data.head(5)
print('样本数:', data.shape[0])
print('变量数:', data.shape[1])
data.shape
print('变量的数据类型:')
data.dtypes
print('数值类型变量的描述性统计分析:')
data.describe().T
print('目标变量的取值:', data['STATUS'].unique())
# 类别变量编码
# 第一步:对象转换为类别变量
data["city_name"] = data["city_name"].astype('category')
data["department_name"] = data["department_name"].astype('category')
data["job_title"] = data["job_title"].astype('category')
data["gender_short"] = data["gender_short"].astype('category')
data["termreason_desc"] = data["termreason_desc"].astype('category')
data["termtype_desc"] = data["termtype_desc"].astype('category')
data["BUSINESS_UNIT"] = data["BUSINESS_UNIT"].astype('category')
# 第二步:类别变量做标签编码
data["city_name_NUMERIC"] = data["city_name"].cat.codes
data["department_name_NUMERIC"] = data["department_name"].cat.codes
data["job_title_NUMERIC_NUMERIC"] = data["job_title"].cat.codes
data["gender_short_NUMERIC"] = data["gender_short"].cat.codes
data["termreason_desc_NUMERIC"] = data["termreason_desc"].cat.codes
data["termtype_desc_NUMERIC"] = data["termtype_desc"].cat.codes
data["BUSINESS_UNIT_NUMERIC"] = data["BUSINESS_UNIT"].cat.codes
data.head()
# 移除ID列
data = data.drop(columns=['EmployeeID'])
# 目标变量类型转换
data['ClasseNumerica'] = np.where(data['STATUS']=='ACTIVE', 1, 0)
data.tail(15)
print('-> 目标变量类别的分布情况:')
QtdObservacoes = data.shape[0]
QtdValClasse = data['STATUS'].unique().size
count = 0
print('样本数:', QtdObservacoes)
while count < QtdValClasse:
print(data['STATUS'].unique()[count], ':', (data.groupby('STATUS').size())[count], '(', (((data.groupby('STATUS').size())[count]/ (QtdObservacoes)) * 100), '% )')
count = count + 1
data.groupby('STATUS').size()
# 可视化分析
data.hist(sharex=False, sharey=False, figsize=(20,12), grid=True)
plt.show()
# 相关系数矩阵
ColunaNumericas = (data._get_numeric_data()).columns.tolist() #获取数值型变量集
QtdTotalElementos = len(ColunaNumericas)
values_corr = data.corr() #生成相关性系数矩阵
# 相关性系数矩阵可视化
fig = plt.figure() # 构建图表
ax = fig.add_subplot(1,1,1)
correlation_matrix = ax.matshow(values_corr
,vmin = -1
,vmax = 1
,interpolation = 'none'
,cmap = 'hot_r' #'hot_r', 'pink_r', 'spring', 'spring_r'
,aspect='auto'
#,alpha = 0.75
,origin = 'upper'
) #matshow -> 把数组或者矩阵绘制为图形
fig.colorbar(correlation_matrix)
ticks = np.arange(0, QtdTotalElementos, 1)
ax.set_xticks(ticks)
ax.set_yticks(ticks)
ax.set_xticklabels(labels=ColunaNumericas, rotation=85, fontsize=12)
ax.set_yticklabels(labels=ColunaNumericas, fontsize=12)
plt.show()
# 可视化主要变量和目标变量的关系
ColunaNumericas = ['STATUS_YEAR', 'age', 'length_of_service', 'store_name', 'city_name_NUMERIC']
dataframe = data[ColunaNumericas]
dataframe = dataframe.assign(Classe=data['STATUS']) # 往数据框中添加新列
sns.pairplot(data=dataframe, hue="Classe", kind='scatter', palette="cubehelix")
ColunaNumericas = (data._get_numeric_data()).columns.tolist()
QtColunasNumericas = len(ColunaNumericas)
df_ALL_TERMINATED = data[data['ClasseNumerica'] == 0]
df_ALL_ACTIVE = data[data['ClasseNumerica'] == 1]
df_ALL_TERMINATED = (df_ALL_TERMINATED[ColunaNumericas])
df_ALL_ACTIVE = (df_ALL_ACTIVE[ColunaNumericas])
preditoras_ALL_TERMINATED = df_ALL_TERMINATED.values[:,:-1]
preditoras_ALL_ACTIVE = df_ALL_ACTIVE.values[:,:-1]
alvo_ALL_TERMINATED = df_ALL_TERMINATED.values[:,-1:QtColunasNumericas]
alvo_ALL_ACTIVE = df_ALL_ACTIVE.values[:,-1:QtColunasNumericas]
# 构建训练集和测试集
random.seed(1)
# 训练集
preditoras_5000_INSTANCES_ACTIVE = np.array( random.sample(population = list(preditoras_ALL_ACTIVE), k = 5000))
preditoras_treino = np.concatenate([preditoras_ALL_TERMINATED, preditoras_5000_INSTANCES_ACTIVE])
# 测试集
preditoras_1000_INSTANCES_TERMINATED = np.array( random.sample(population = list(preditoras_ALL_TERMINATED), k = 1000) )
preditoras_40000_INSTANCES_ACTIVE = np.array( random.sample(population = list(preditoras_ALL_ACTIVE), k = 40000) )
preditoras_teste = np.concatenate([preditoras_1000_INSTANCES_TERMINATED, preditoras_40000_INSTANCES_ACTIVE])
# 训练集目标变量
alvo_treino_5000_INSTANCES_ACTIVE = np.array( random.sample(population = list(alvo_ALL_ACTIVE), k = 5000) )
alvo_treino = np.concatenate([alvo_ALL_TERMINATED, alvo_treino_5000_INSTANCES_ACTIVE])
# 测试集目标变量
alvo_1000_INSTANCES_TERMINATED = np.array( random.sample(population = list(alvo_ALL_TERMINATED), k = 1000) )
alvo_40000_INSTANCES_ACTIVE = np.array( random.sample(population = list(alvo_ALL_ACTIVE), k = 40000) )
alvo_teste = np.concatenate([alvo_1000_INSTANCES_TERMINATED, alvo_40000_INSTANCES_ACTIVE])
# 交叉验证--模型的选择
# 显示模型的性能分析
disable_DataConversionWarning()
disable_FutureWarning()
# 根据每种算法创建机器学习模型
modelos = []
modelos.append(('LogisticRegression', LogisticRegression()))
modelos.append(('KNeighborsClassifier', KNeighborsClassifier()))
modelos.append(('DecisionTreeClassifier', DecisionTreeClassifier()))
resultados = []
nomes = []
modelos_nome = []
mensagens = []
tempo = []
n_folds = 10
seed = 7
for nome, modelo in modelos:
# 设置处理开始的时间
start_time = time.time()
# 创建交叉验证 10折交叉验证
k_folds = model_selection.KFold(n_splits = n_folds, random_state = seed)
# 创建模型
result_saida = model_selection.cross_val_score(modelo
,preditoras_treino
,alvo_treino
,cv = k_folds
#,n_jobs = -1
,scoring = 'accuracy'
#,verbose = 5
)
#记录模型名称
modelos_nome.append(nome)
#记录模型结果
resultados.append(result_saida * 100)
#输出最终消息
mensagens.append('模型: %s \n\n性能平均值: %.2f%%\n性能标准差: %.2f%%' % (modelo, (result_saida.mean()*100), (result_saida.std()*100)))
# 执行模型所需要的时间
tempo.append(time.time() - start_time)
qtd_mensagens = len(mensagens)
iterador = 0
print('---> 准确性描述评估 <---')
while qtd_mensagens > iterador:
print('--------------------------------------------------------------------', '\n')
print(mensagens[iterador])
print('运行的时间: %s (HH:MM:SS)' % timedelta(seconds=round(tempo[iterador])))
iterador = iterador + 1
print('--------------------------------------------------------------------')
# 模型准确性可视化比较
fig = plt.figure()
fig.suptitle('分类算法性能比较')
ax = fig.add_subplot(111)
plt.boxplot(resultados)
ax.set_xticklabels(modelos_nome)
plt.show()
enable_All_Warning()
# 基于模型选择里面最佳模型 决策树模型 构建预测模型
# 警告处理
disable_DataConversionWarning()
disable_FutureWarning()
# 创建管道
pipeline = []
pipeline.append(('Standardize', StandardScaler()))
pipeline.append(('ScaleFit', MinMaxScaler()))
pipeline.append(('Normalizer', Normalizer()))
pipeline.append(('DecisionTreeClassifier', DecisionTreeClassifier()))
pipeline = Pipeline(steps=pipeline)
model = pipeline.fit(preditoras_treino, alvo_treino)
previsoes = model.predict(preditoras_teste)
# 模型在测试数据集上应用
print('-> 模型的准确率:', str(round((accuracy_score(alvo_teste, previsoes)*100),2)) + '%')
print('\n-> 模型的混淆矩阵:\n', confusion_matrix(alvo_teste, previsoes), '\n')
print('-> 模型分类性能评价报告:\n\n', classification_report(alvo_teste, previsoes))
参考资料:
1、案例的数据集-来自Kaggle平台
(https://www.kaggle.com/HRAnalyticRepository/employee-attrition-data/)
2、 pandas库类别变量的数据处理-类别编码
(https://pandas.pydata.org/pandasdocs/stable/user_guide/categorical.html)
3、Numpy库where函数
https://docs.scipy.org/doc/numpy-1.15.1/reference/generated/numpy.where.html
4、StandardScaler/MinMaxScaler/Normalizer之间的区别
(https://blog.csdn.net/u010471284/article/details/97627441)
5、sklearn: 管道与特征联合
(https://tsinghua-gongjing.github.io/posts/sklearn_pipeline.html)
6、cross_val_score的 scoring参数值解析
https://blog.csdn.net/qq_32590631/article/details/82831613
7、https://github.com/daniellj/DataScience
公众号推荐
数据思践
数据思践公众号记录和分享数据人思考和践行的内容与故事。
Python语言群
诚邀您加入
《数据科学与人工智能》公众号推荐朋友们学习和使用Python语言,需要加入Python语言群的,请扫码加我个人微信,备注【姓名-Python群】,我诚邀你入群,大家学习和分享。