
Kaggle Top1% 是如何炼成的!

我是小白,但是对数据科学充满求知欲。
我想要历练自己的数据挖掘和机器学习技能,成为一名真正的数据科(lao)学(si)家(ji)。
我想赢取奖金,成为人生赢家。

Feature 特征变量,也叫自变量,是样本可以观测到的特征,通常是模型的输入。
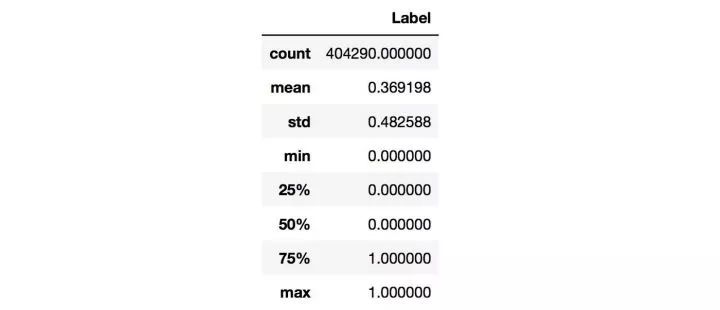
Label 标签,也叫目标变量,需要预测的变量,通常是模型的标签或者输出。
Train Data 训练数据,有标签的数据,由举办方提供。
Test Data 测试数据,标签未知,是比赛用来评估得分的数据,由举办方提供。
Train Set 训练集,从Train Data中分割得到的,用于训练模型(常用于交叉验证)。
Valid Set 验证集,从Train Data中分割得到的,用于验证模型(常用于交叉验证)。
回归问题
分类问题(二分类、多分类、多标签) 多分类只需从多个类别中预测一个类别,而多标签则需要预测出多个类别。
数据应该怎么清洗和处理才是合理的?
根据数据的类型可以挖掘怎样的特征?
数据中的哪些特征会对标签的预测有帮助?
对于数值型变量(Numerical Variable),需要处理离群点,缺失值,异常值等情况。
对于类别型变量(Categorical Variable),可以转化为one-hot编码。
文本数据是较难处理的数据类型,文本中会有垃圾字符,错别字(词),数学公式,不统一单位和日期格式等。我们还需要处理标点符号,分词,去停用词,对于英文文本可能还要词性还原(lemmatize),抽取词干(stem)等等。
对于Numerical Variable,可以通过线性组合、多项式组合来发现新的Feature。
对于文本数据,有一些常规的Feature。比如,文本长度,Embeddings,TF-IDF,LDA,LSI等,你甚至可以用深度学习提取文本特征(隐藏层)。
如果你想对数据有更深入的了解,可以通过思考数据集的构造过程来发现一些magic feature,这些特征有可能会大大提升效果。在Quora这次比赛中,就有人公布了一些magic feature。
通过错误分析也可以发现新的特征(见1.5.2小节)。
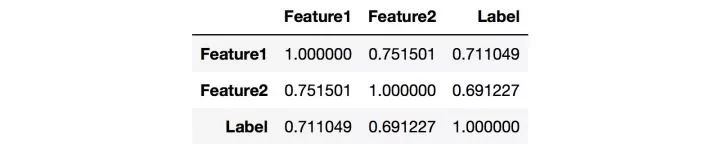
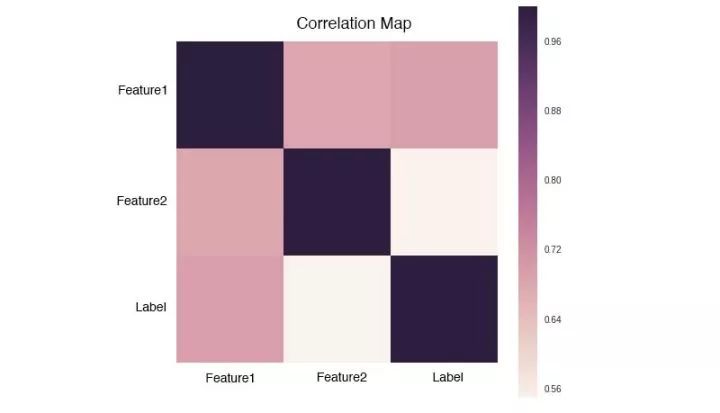
Feature和Label的相关度可以看作是该Feature的重要度,越接近1或-1就越好。
Feature和Feature之间的相关度要低,如果两个Feature的相关度很高,就有可能存在冗余。
KNN
SVM
Linear Model(带惩罚项)
ExtraTree
RandomForest
Gradient Boost Tree
Neural Network
Question1: Which is the best digital marketing institution in banglore?
Question2: Which is the best digital marketing institute in Pune?
根据经验,选出对模型效果影响较大的超参。
按照经验设置超参的搜索空间,比如学习率的搜索空间为[0.001,0.1]。
选择搜索算法,比如Random Search、Grid Search和一些启发式搜索的方法。
验证模型的泛化能力(详见下一小节)。
简单分割
交叉验证

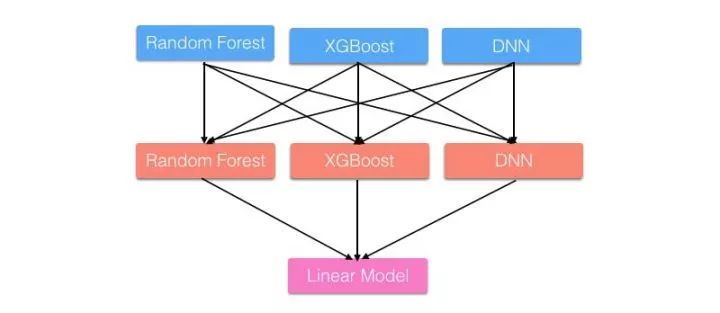
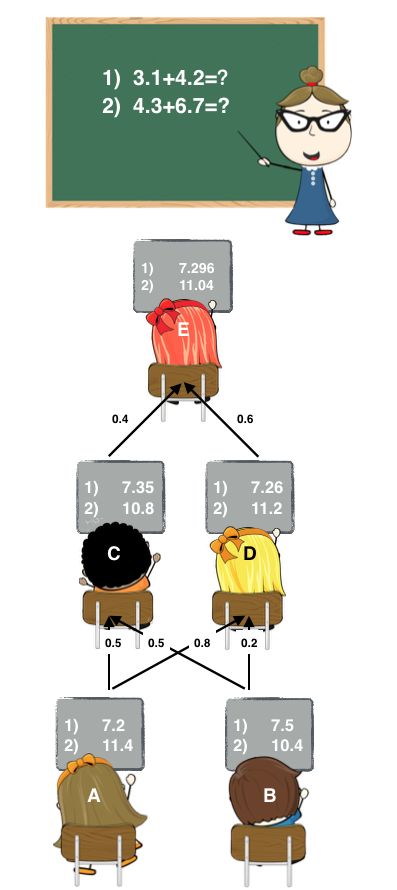
Stage1: A和B各自写出了答案。
Stage2: C和D偷看了A和B的答案,C认为A和B一样聪明,D认为A比B聪明一点。他们各自结合了A和B的答案后,给出了自己的答案。
Stage3: E偷看了C和D的答案,E认为D比C聪明,随后E也给出自己的答案作为最终答案。

Text Mining Feature,比如句子长度;两个句子的文本相似度,如N-gram的编辑距离,Jaccard距离等;两个句子共同的名词,动词,疑问词等。
Embedding Feature,预训练好的词向量相加求出句子向量,然后求两个句子向量的距离,比如余弦相似度、欧式距离等等。
Vector Space Feature,用TF-IDF矩阵来表示句子,求相似度。
Magic Feature,是Forum上一些选手通过思考数据集构造过程而发现的Feature,这种Feature往往与Label有强相关性,可以大大提高预测效果。
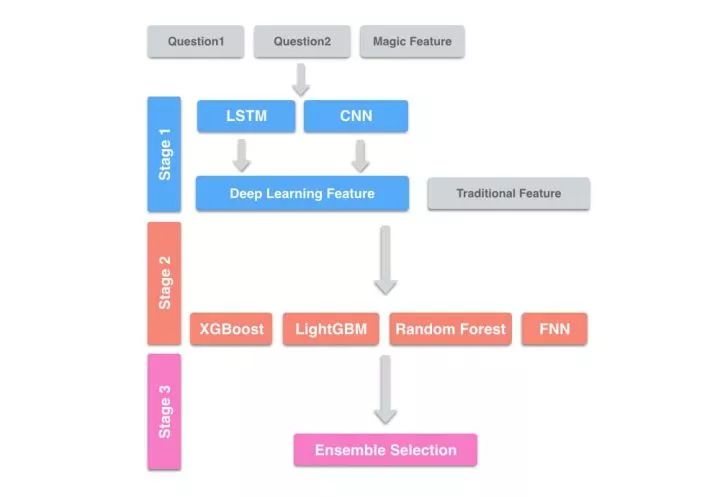
Stage1: 将两个问句与Magic Feature输入Deep Learning中,将其输出作为下一层的特征(这里的Deep Learning相当于特征抽取器)。我们一共训练了几十个Deep Learning Model。
Stage2: 将Deep Learning特征与手工抽取的几百个传统特征拼在一起,作为输入。在这一层,我们训练各种模型,有成百上千个。
Stage3: 上一层的输出进行Ensemble Selection。
对于一些数据的Pattern,在Train Data中出现的频数不足以让深度学习学到对应的特征,所以我们需要通过手工提取这些特征。
由于Deep Learning对样本做了独立同分布假设(iid),一般只能学习到每个样本的特征,而学习到数据的全局特征,比如TF-IDF这一类需要统计全局词频才能获取的特征,因此也需要手工提取这些特征。
Embedding Feature
Text Mining Feature
Structural Feature(他们自己挖掘的Magic Feature)
Stage1: 使用了Deep Learning,XGBoost,LightGBM,ExtraTree,Random Forest,KNN等300个模型。
Stage2: 用了手工特征和第一层的预测和深度学习模型的隐藏层,并且训练了150个模型。
Stage3: 使用了分别是带有L1和L2的两种线性模型。
Stage4: 将第三层的结果加权平均。
Numpy | 必用的科学计算基础包,底层由C实现,计算速度快。
Pandas | 提供了高性能、易用的数据结构及数据分析工具。
NLTK | 自然语言工具包,集成了很多自然语言相关的算法和资源。
Stanford CoreNLP | Stanford的自然语言工具包,可以通过NLTK调用。
Gensim | 主题模型工具包,可用于训练词向量,读取预训练好的词向量。
scikit-learn | 机器学习Python包 ,包含了大部分的机器学习算法。
XGBoost/LightGBM | Gradient Boosting 算法的两种实现框架。
PyTorch/TensorFlow/Keras | 常用的深度学习框架。
StackNet | 准备好特征之后,可以直接使用的Stacking工具包。
Hyperopt | 通用的优化框架,可用于调参。

长按或扫描下方二维码,后台回复:加群,可申请入群。一定要备注:入群+地点+学习/公司。例如:入群+上海+复旦。
感谢你的分享,点赞,在看三连 