
CUDA翻译:How to Access Global Memory Efficiently in CUDA
在先前的两篇博客里,我们展示了如何高效地在Host端和Device端交换数据,在本篇博客我们着重讨论如何高效地访问显存,特别是Global Memory
CUDA设备上有好几种显存,具有各自的作用域,生命周期,缓存机制。这个系列里我们以驻留在设备DRAM的GlobalMemory为例,它将被用于host和device端数据交换,以及核函数的输入输出数据交换。
名字中的global表示他的作用域,他可以在host,device端来访问,修改其内容。GlobalMemory可以使用device关键字在global作用域声明,或者使用cudaMalloc配合指针来动态分配:
__device__ int globalArray[256];
void foo()
{
...
int *myDeviceMemory = 0;
cudaError_t result = cudaMalloc(&myDeviceMemory, 256 * sizeof(int));
...
}
根据设备的compute capability,Global Memory 可能会在片上进行缓存。
在我们深入探讨GlobalMemory访存性能之前,我们需要完善对CUDA执行模型的理解。我们已经讨论了线程是如何被组织进线程块的,这些线程块又被分配给设备上的Multi Processor。在执行过程中,我们又把线程进一步分组为线程束。GPU上的Multi Processor以SIMD的方式给每个线程束执行指令,线程束则是由32个线程组成。
译者注:我觉得这里原文写错了,应该是以SIMT的方式执行指令,欢迎感兴趣的读者讨论
全局内存合并
将线程组成一个线程束不仅跟计算有关,还跟访存有关。设备将Global Memory的加载和存储尽可能合并成较少的内存事务,以最小化DRAM带宽(在Compute Capability<2.0 更老的设备上,事务会在半个线程束内合并)。为了弄清楚CUDA设备架构上发生访存合并的条件,我们分别在
Tesla C870 (compute capability 1.0) Tesla C1060 (compute capability 1.3) Tesla C2050 (compute capability 2.0). 这上面进行测试
我们使用两个不同的Kernel,其中一个是带有offset,导致对数组访问是不对齐的,而另外一个则是跨步长来访问数组:
具体代码参考:https://github.com/NVIDIA-developer-blog/code-samples/blob/master/series/cuda-cpp/coalescing-global/coalescing.cu
template <typename T>
__global__ void offset(T* a, int s)
{
int i = blockDim.x * blockIdx.x + threadIdx.x + s;
a[i] = a[i] + 1;
}
template <typename T>
__global__ void stride(T* a, int s)
{
int i = (blockDim.x * blockIdx.x + threadIdx.x) * s;
a[i] = a[i] + 1;
}
通过设置fp64命令行选项,我们可以让代码在单精度/双精度下运行。每个kernel一共有两个输入,第一个是输入数组,第二个则表示访问数组的stride/offset,我们在一个stride/offset的范围内进行循环调用核函数
不对齐的数据访问
offset kernel的测试结果如下:
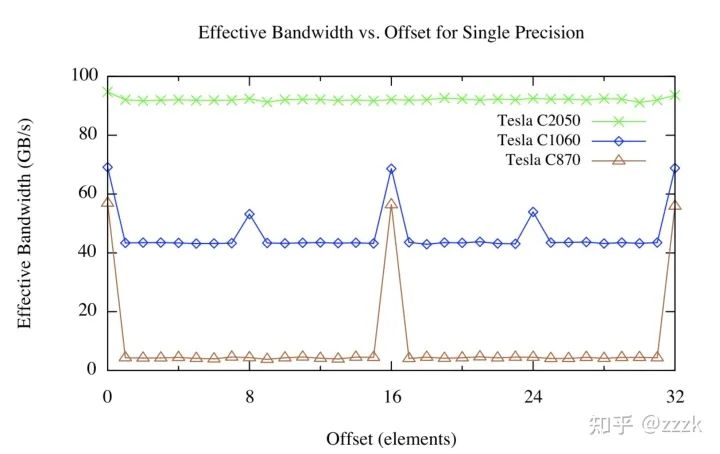
分配到设备内存上的数组由CUDA驱动程序对齐到256-byte内存段,设备可以通过32/64/128-byte大小的内存事务来访问Global Memory,这些内存事务和他们的大小对齐。
对于C870这样的Compute Cabability<1.0的设备,任意 半个线程束 内的不对齐访问(或半个线程束不按顺序访问内存的对齐访问),将会把256-byte访问拆分成16个32-byte内存访问事务
译者注:这里为什么是16个32-byte,因为是半个线程束,所以是16。因为没有对齐访问,所以每一次访问一个元素,是要用单独一个最小内存事务来完成,而内存事务最小为32-byte。因此总的就是16x32-byte
在每一次32-byte大小的内存事务中,我们只取了其中的4byte(译者注这里应该是float32情况下)。那么相当于有效带宽为原先的1/8。对应我们上图棕褐色曲线中,offset不为16倍数时对应的带宽大小。
对于C1060这些Compute Cabability为1.2/1.3的设备,不对齐访问带来的问题则比较小。基本上由半个线程束带来的不对齐访问是在其中几个覆盖了所需要的数据的事务中进行。但因为传输了一些不需要的数据,以及不同的半个线程束内数据有所重叠,仍会带来性能损失,但损失相较C870少的多
而在Compute Cabability为2.0的设备,如C205,它在每个MultiProecssor上都有一个linesize为128byte的L1 Cache。设备将尽可能把线程束访问合并到尽可能少的cache line中,从而使跨线程的内存访问对吞吐量影响可忽略不计
跨Stride内存访问
跨Stride访问的Kernel结果如下图所示:
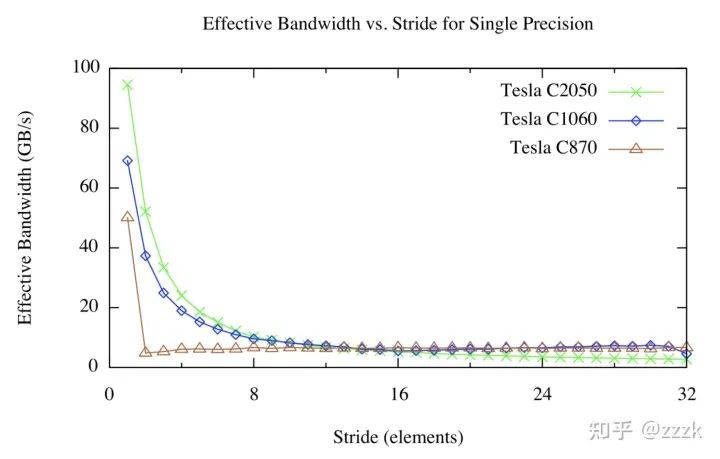
我们有一张完全不一样的数据图。对于比较大的Strides,无论架构版本如何,其有效带宽都很低。这也无需感到惊讶,当线程并发地访问相距较远的内存地址时,硬件就没有机会访问。可以在图中看到C870,当stride〉1后,其有效带宽大幅度降低,这是因为Compute Cabability为1.0/1.1的硬件要求线性,对齐的内存访问以合并 ,所以我们也能在offset kernel那里看到性能降低至1/8。Compute capability 1.2及更高版本的设备可以合并成段对齐的访问(CC 1.2/1.3上的32、64或128字节段,以及CC 2.0及更高版本上的128bytes的cache line),因此这些设备的带宽曲线更加平滑。
当我们访问高维数组的时候,线程通常要索引数组中更高的维度,所以stirded access是不可避免的。我们可以借助shared memory来处理这种情形,shared memory是在一个线程块内被所有线程共享的片上显存。Shared Memory的一个用途就是以合并的方式,从Global Memory取一个二维的分块到Shared Memory中,然后连续的线程经过Shared Memory分块跨Stride访问。与Global Memory不同的是, Shared Memory跨Stride访问并不会有任何惩罚,我们将在下篇博客详细讲解Shared Memory。
总结
在本篇博客中,我们讨论了CUDA Kernel中如何高效访问Global Memory,设备上的Shared Memory访问与Host端数据访问具有相同的特性,数据局部性非常重要。在早期的CUDA设备中中,内存访问对齐与线程间的局部性一样重要,但在最近的设备上,内存访问对齐并不是什么大问题。另一方面,跨Stride访问显存可能会影响性能,使用Shared Memory可以缓解这一问题。
在下一篇文章中,我们将详细探讨Shared Memory,并展示如何使用Shared Memory,以避免在矩阵转置期间进行跨Stride的Global Memory访问。
- The End -
长按二维码关注我们
本公众号专注:
1. 技术分享;
2. 学术交流;
3. 资料共享。
欢迎关注我们,一起成长!