
NVIDIA GPU技术和架构演进(附白皮书)
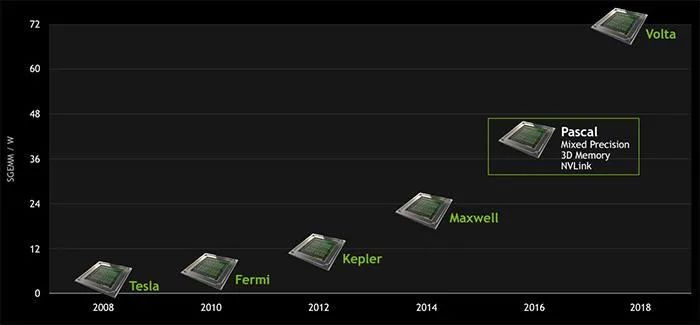

去年,NVIDIA (NV) 发布了Amper新架构的GPU,NVIDIA GPU架构的发展类似Intel的CPU,针对不同场景和技术革新,经历了不同架构的演进。

-
Kepler架构里,FP64单元和FP32单元的比例是1:3或者1:24;K80。 -
Maxwell架构里,这个比例下降到了只有1:32;型号M10/M40。 -
Pascal架构里,这个比例又提高到了1:2(P100)但低端型号里仍然保持为1:32,型号Tesla P40、GTX 1080TI/Titan XP、Quadro GP100/P6000/P5000 -
Votal架构里,FP64单元和FP32单元的比例是1:2;型号有Tesla V100、GeForceTiTan V、Quadro GV100专业卡。 -
Turing架构里,一个SM中拥有64个半精度,64个单精度,8个Tensor core,1个RT core。 -
Ampere架构的设计突破,在8代GPU架构中提供了该公司迄今为止最大的性能飞跃,统一了AI培训和推理,并将性能提高了20倍。A100是通用的工作负载加速器,还用于数据分析,科学计算和云图形。
NVIDIA GPU架构相关文章:
1、Fermi
 Fermi架构SM
Fermi架构SM
-
2 个 Warp Scheduler/Dispatch Unit -
32 个 CUDA Core(分在两条 lane 上,每条分别是 16 个) -
每个 CUDA Core 里面是 1 个单精浮点单元(FPU)和 1 个整数单元(ALU),可以直接做 FMA 的乘累加 -
每个 cycle 可以跑 16 个双精的 FMA -
16 个 LD/ST Unit -
4 个 SFU
我的理解是做一个双精 FMA 需要用到两个 CUDA Core?所以是 32 / 2 = 16
2、Kepler
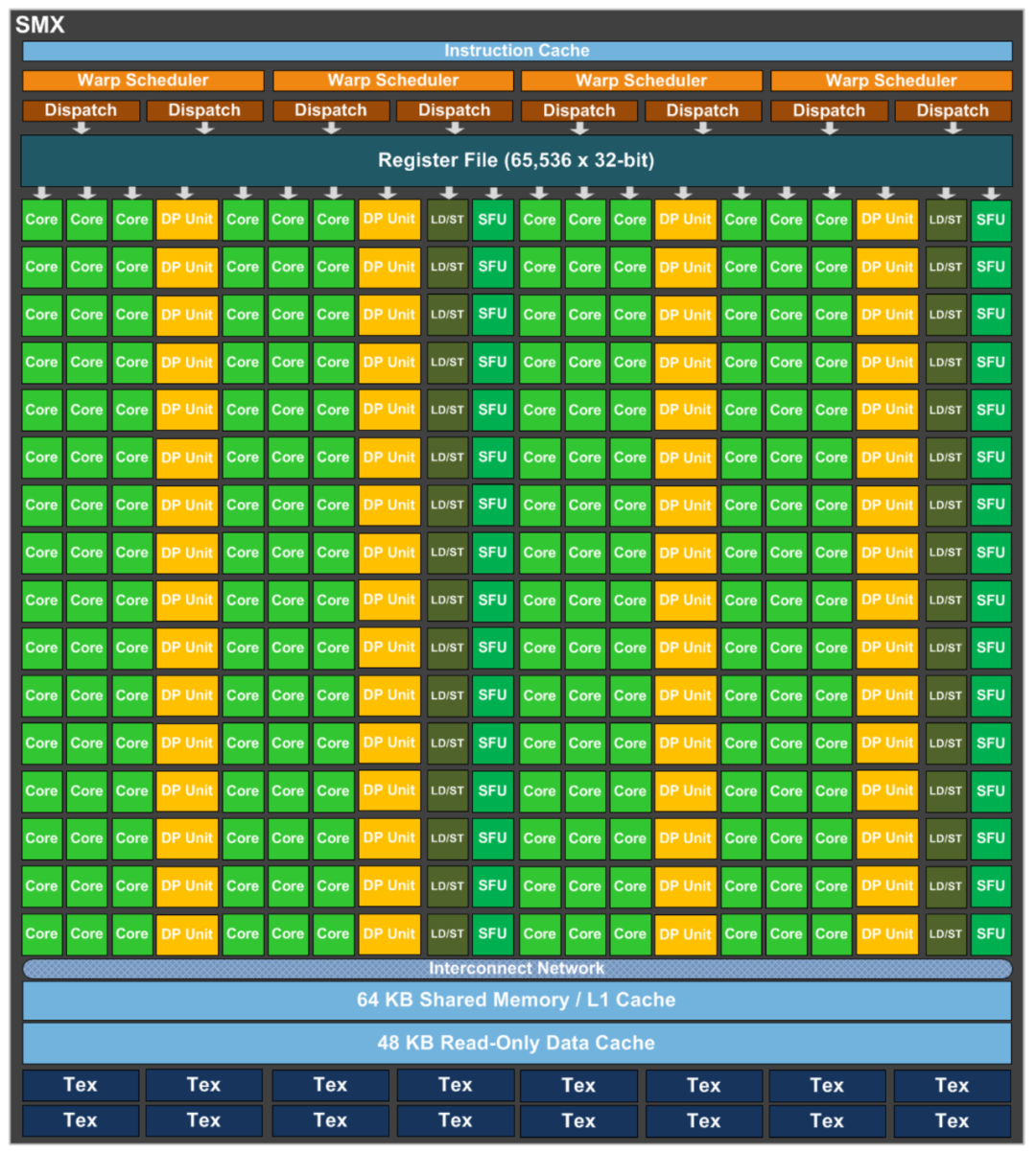
-
4 个 Warp Scheduler,8 个 Dispatch Unit -
CUDA Core 增加到 192 个(4 * 3 * 16,每条 lane 上还是 16 个) -
单独分出来 64 个(4 * 16,每条 lane 上 16 个)双精运算单元。 -
SFU 和 LD/ST Unit 分别也都增加到 32 个
3、Maxwell
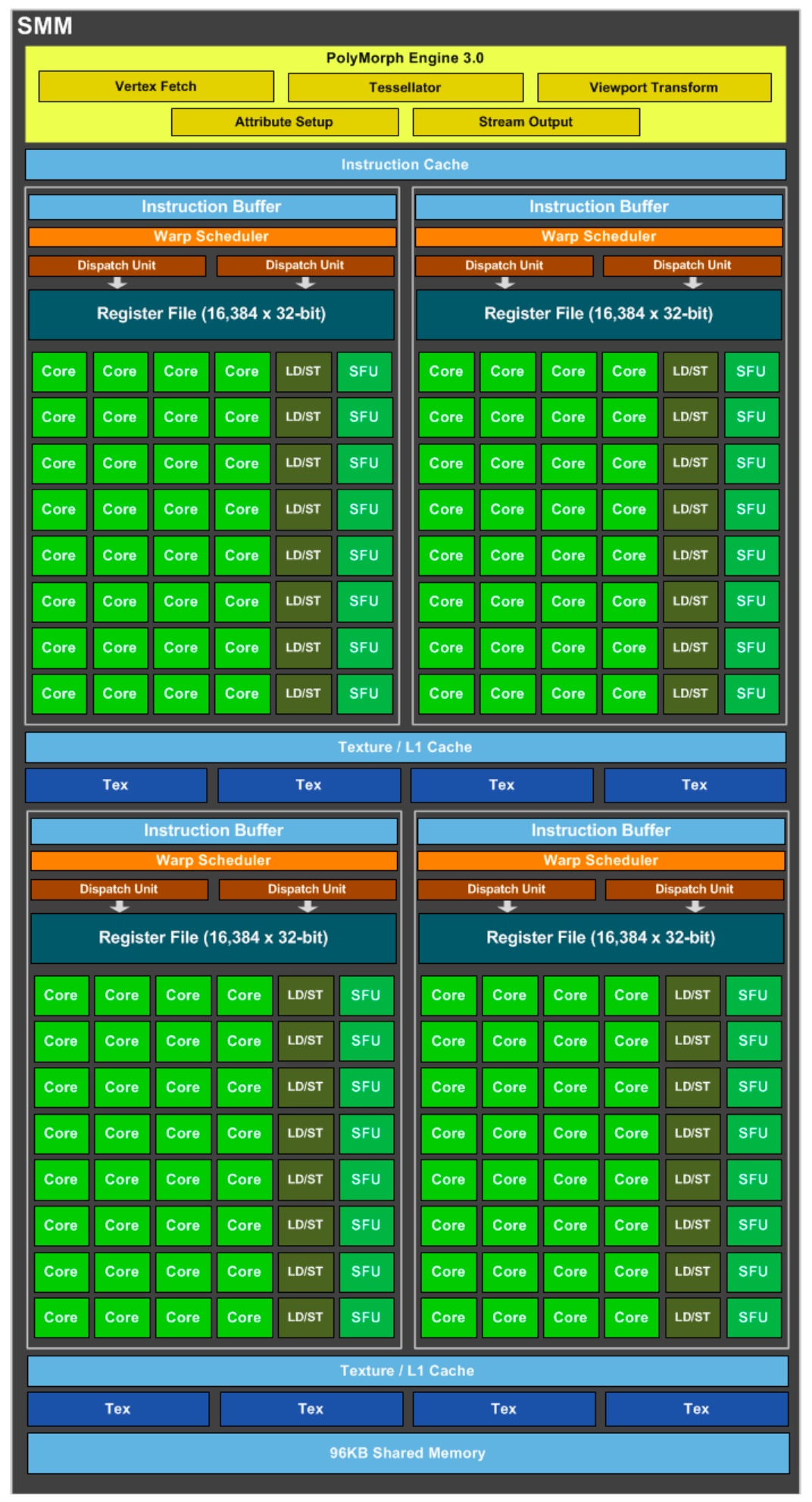
-
4 个 Warp Scheduler,8 个 Dispatch Unit -
128 个 CUDA Core(4 * 32) -
32 个 SFU 和 LD/ST Unit(4 * 8)
-
1 个 Warp Scheduler 和 2 个 Dispatch Unit -
32 个 CUDA Core -
8 个 SFU 和 LD/ST Unit
也许是觉得认为只有少数 HPC 科学计算才用的上的双精单元在这代上不太有必要吧。
4、Pascal
Compute Capability:6.0, 6.1, 6.2;这一代可以说是有了质的飞跃,还是先从 SM 开始:

-
2 个 Warp Scheduler,4 个 Dispatch Unit -
64 个 CUDA Core(2 * 32) -
32 个双精浮点单元(2 * 16,双精回来了) -
16 个 SFU 和 LD/ST Unit(2 * 8)
-
1 个 Warp Scheduler 和 2 个 Dispatch Unit -
32 个 CUDA Core -
多了 16 个 DP Unit -
8 个 SFU 和 LD/ST Unit
单个 Process Block 的流水线增加到 6 条 lane 了?
-
面向 Deep Learning 做了一些专门的定制(CuDNN 等等) -
除了 PCIE 以外,P100 还有 NVLink 版,单机卡间通信带宽逆天了,多机之间也能通过 Infiniband 进一步扩展 NVLink(GPUDirect) 然后 NV 现在已经把 Infiniband 行业的龙头 Mellanox 给收购了…… 说不定那时候就已经有这个想法了呢 -
P100 上把 GDDR5 换成了 HBM2,Global Memory 的带宽涨了一个数量级 -
16nm FinFET 工艺,性能提升一大截,功耗还能控制住不怎么增加 -
Unified Memory,支持把 GPU 的显存和 CPU 的内存统一到一个相同的地址空间,驱动层自己会做好 DtoH 和 HtoD 的内存拷贝,编程模型上更加友好了
5、Volta
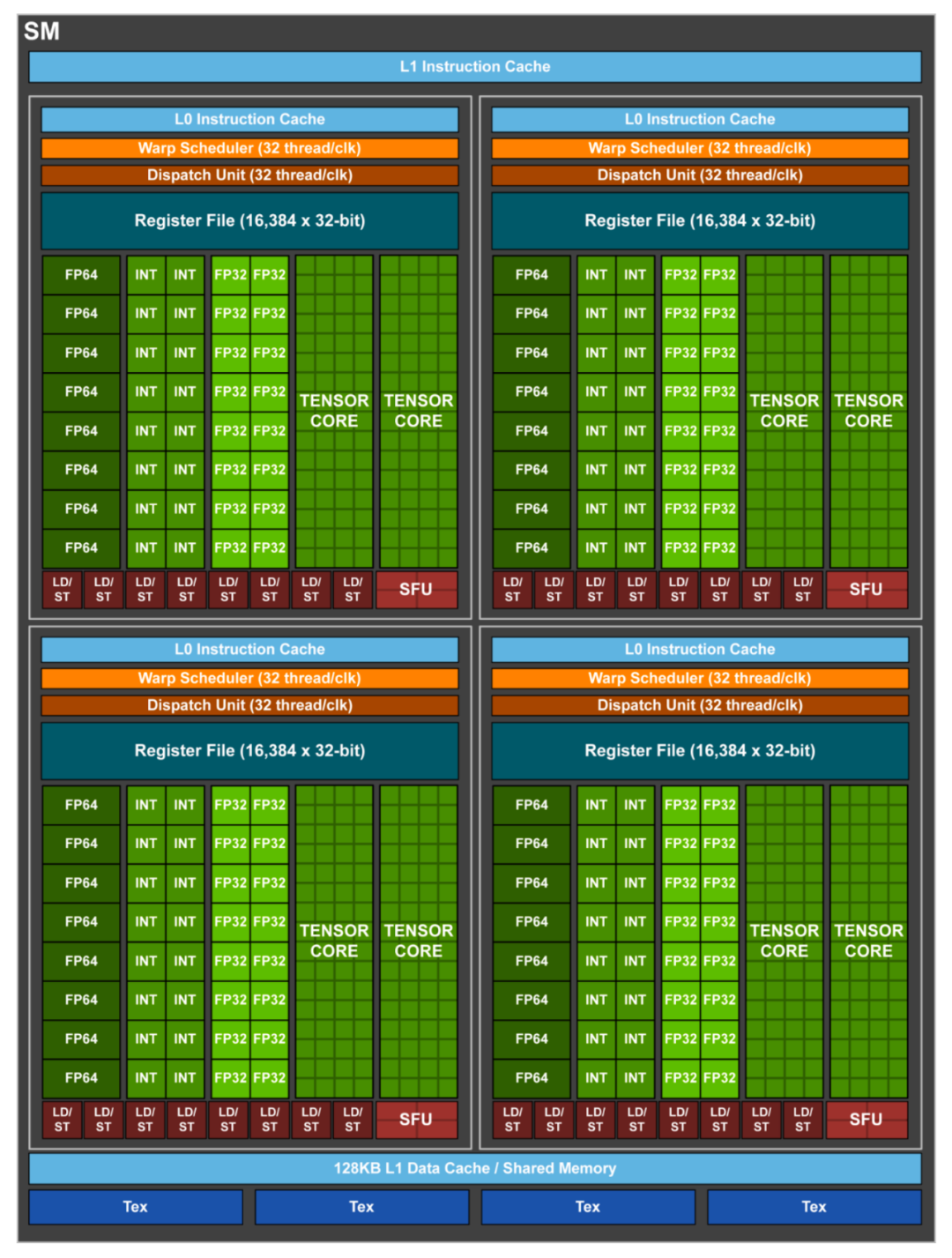
-
4 个 Warp Scheduler,4 个 Dispatch Unit(发现不需要配 2 个 Dispatch 给每个 Scheduler 了?白皮书里面倒是没有对这个的解释) -
64 个 FP32 Core(4 * 16) -
64 个 INT32 Core(4 * 16) -
32 个 FP64 Core(4 * 8) -
8 个 Tensor Core (4 * 2) -
32 个 LD/ST Unit(4 * 8) -
4 个 SFU(发现对特殊计算的需求减少了?)
-
1 个 Warp Scheduler,1 个 Dispatch Unit -
16 个 FP32 Core -
16 个 INT32 Core -
8 个 FP64 Core -
2 个 Tensor Core -
8 个 LD/ST Unit -
1 个 SFU
Tensor Core:最重大的改动不用说也知道是 Tensor Core 了。
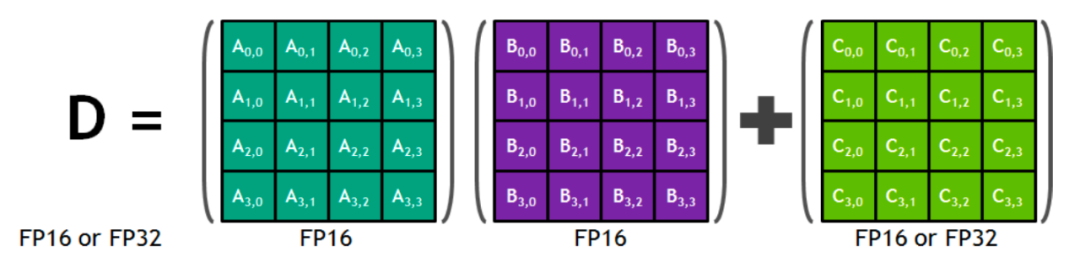
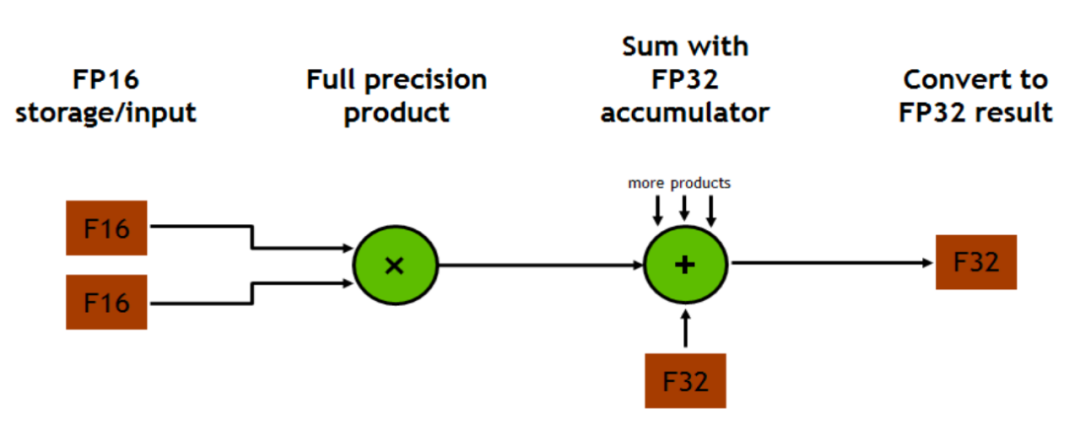
所以 FP16 in -> FP16 out 和 FP16 in -> FP32 out 哪一个性能更好呢…
我没有测过,但是猜测可能默认结果是 FP32 out 更快?反而是输出 FP16 需要从 FP32 再转一次?
-
第一个参数 Use 是这个 fragment 在 FMA 运算里面的角色,可选项有:matrix_a、matrix_b和 accumulator,含义就是字面意思,也没什么需要再解释的了。 -
m,n,k,T 是这一个 warp 里面要处理的的 FMA 子矩阵的形状以及数据类型,不同的 Capability 能够支持的组合还不太一样,比如最基础的就是 a、b 都是 __half,accumulator 是 float,然后 m、n、k 都是 16。
m、n、k 的组合不是任意的,能支持的种类跟 Capability 直接相关,比如 V100 和后来出的 T4 能够支持的就不一样,具体可以在 Programming Guide 里面查。 -
最后这个 Layout 可选项有两个 row_major 和 col_major,代表这个 fragment 在内存里面实际存储的行列主序情况。
看起来确实相当麻烦,不过想想可能好像也还好,本来如果要写出性能很好的 CUDA 代码来,每个 warp 要算多少东西也是需要精细考虑清楚的。
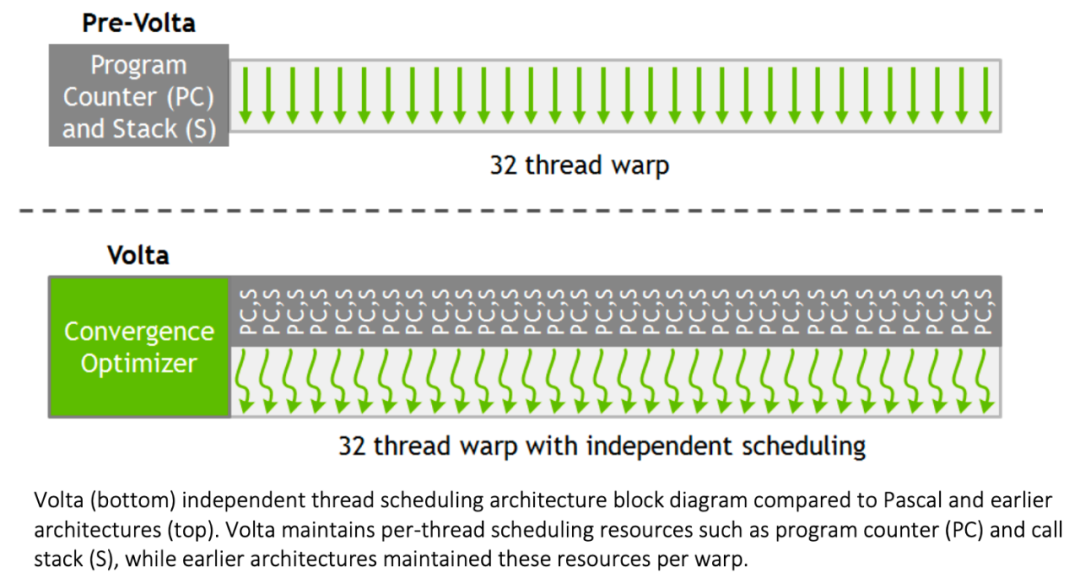
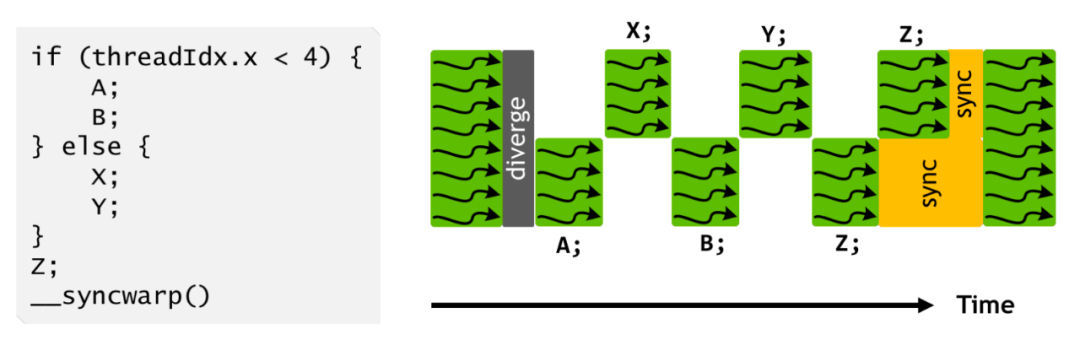
可能也是因为这样所以 1 个 Dispatch Unit 配 1 个 Warp Scheduler 了?因为线程指令的实现事实上更加复杂了。
所以其实最后还是同时只能执行一个分支里面的一部分,这个 upgrade 我暂时还没有想到具体的应用场景会有多常出现(上面这个带锁双向链表我觉得写在 CUDA 里面就很不常见啊…),以及会具体有多少性能收益,说不定还是原本的那种简单的设计更直接更高效一些呢。(期待一下未来的硬件里面会不会把这个恢复回去……)
以前 CUDA 编程原则里面不要写分支的那条在新架构下我觉得还是适用的,不写分支就不会有这么多额外的麻烦要考虑了。
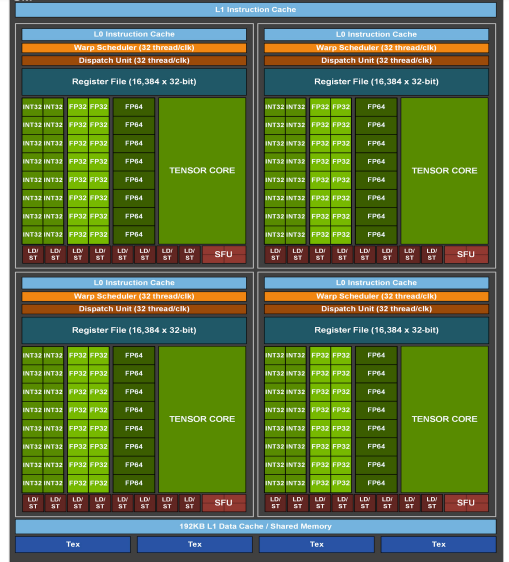
6、Turing
Compute Capability:7.5;TU102 GPU包含6个图像处理集群(GPC)、36个纹理处理集群(TPC)和72个流式多元处理器(SM)。
-
64个CUDA核心 -
8个Tensor核心 -
1个256KB寄存器堆 -
4个纹理单元以及96KB的L1或共享内存
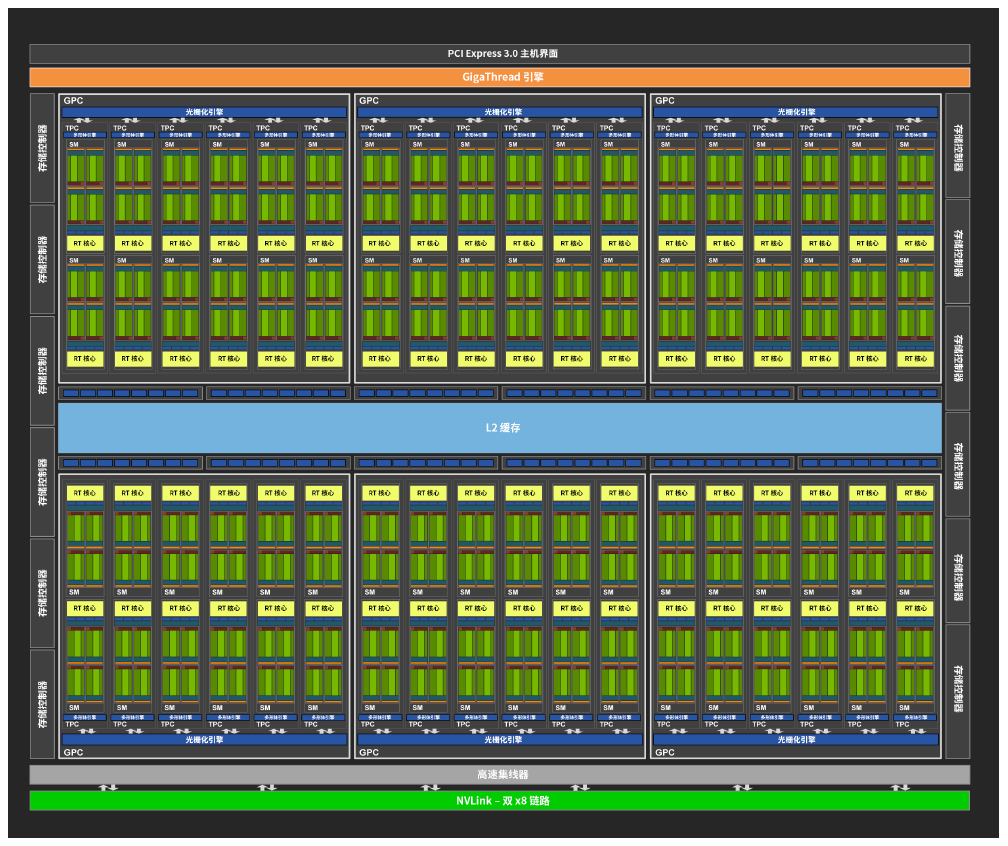
7、Ampere
Compute Capability:8.0;NVIDIA A100在AI训练(半/单精度操作,FP16/32)和推理(8位整数操作,INT8)方面,GPU比Volta GPU强大20倍。在高性能计算(双精度运算,FP64)方面,NVIDIA表示GPU的速度将提高2.5倍。
-
8 GPCs, -
8 TPCs/GPC, 2 SMs/TPC, 16 SMs/GPC, 128 SMs per full GPU -
64 FP32 CUDA Cores/SM, 8192 FP32 CUDA Cores per full GPU -
4第三代Tensor Cores/SM, 512第三代Tensor Cores per full GPU -
6 HBM2 stacks, 12 512bit 内存控制器
-
7 GPCs, 7 or 8 TPCs/GPC -
2 SMs/TPC, up to 16 SMs/GPC, 108 SMs -
64 FP32 CUDA Cores/SM, 6912 FP32 CUDA Cores -
4第三代Tensor Cores/SM, 432第三代Tensor Cores -
5 HBM2 stacks,10 512bit 内存控制器
-
NVIDIA Ampere架构 — A100的核心是NVIDIA Ampere GPU架构,其中包含超过540亿个晶体管,使其成为世界上最大的7纳米处理器。 -
基于TF32的第三代张量核(Tensor Core): Tensor核心的应用使得GPU更加灵活,更快,更易于使用。TF32包括针对AI的扩展,无需进行任何代码更改即可使FP32精度的AI性能提高20倍。此外, TensorCore 现在支持FP64,相比上一代,HPC应用程序可提供多达2.5倍的计算量。 -
多实例(Multi-Instance)GPU — MIG是一项新技术功能,可将单个A100GPU划分为多达七个独立的GPU,因此它可以为不同大小的作业提供不同程度的计算,从而提供最佳利用率。 -
第三代NVIDIA NVLink —使GPU之间的高速连接速度加倍,可在服务器中提供有效的性能扩展。 -
结构稀疏性—这项新的效率技术利用了AI数学固有的稀疏特性来使性能提高一倍。
NVIDIA GPU架构白皮书系列,下载链接:NVIDIA GPU架构白皮书
《NVIDIA A100 Tensor Core GPU技术白皮书》
《NVIDIA Kepler GK110-GK210架构白皮书》
《NVIDIA Kepler GK110-GK210架构白皮书》
《NVIDIA Kepler GK110架构白皮书》
《NVIDIA Tesla P100技术白皮书》
《NVIDIA Tesla V100 GPU架构白皮书》
《英伟达Turing GPU 架构白皮书》
转载申明:转载本号文章请注明作者和来源,本号发布文章若存在版权等问题,请留言联系处理,谢谢。
推荐阅读
更多架构相关技术知识总结请参考“架构师全店铺技术资料打包”相关电子书(35本技术资料打包汇总详情可通过“阅读原文”获取)。
全店内容持续更新,现下单“全店铺技术资料打包(全)”,后续可享全店内容更新“免费”赠阅,价格仅收188元(原总价290元)。
温馨提示:
扫描二维码关注公众号,点击阅读原文链接获取“架构师技术全店资料打包汇总(全)”电子书资料详情。
