新baseline来了!"AI球球大作战: Go-Bigger多智能体挑战赛" 等你来战!

2021年11月,全球首届“ AI 球球大作战:Go-Bigger多智能体决策智能挑战赛”已正式开赛。作为面向全球技术开发者和在校学生的科技类竞赛活动,本次比赛旨在推动决策智能相关领域的技术人才培养,打造全球领先、原创、开放的决策AI开源技术生态。
本次比赛由OpenDILab(开源决策智能平台)主办,上海人工智能实验室作为学术指导,商汤科技、巨人网络、上汽集团人工智能实验室联合主办,全球高校人工智能学术联盟、浙江大学上海高等研究院、上海交通大学清源研究院联合协办,OSCHINA、深度强化学习实验室作为支持,PaperWeekly、机器学习算法与自然语言处理作为合作媒体。
比赛共设冠军、亚军各1名,优胜奖4名,共同瓜分15万赛事奖金。预计明年3月封闭天梯测试, 并在4月发布及公示获胜结果。

⭐️ Go-Bigger比赛主页链接:
https://www.datafountain.cn/competitions/549
⭐️ Challenge Repo Github 链接:
https://github.com/opendilab/GoBigger-Challenge-2021
⭐️ DI-engine Repo Github 链接:
https://github.com/opendilab/DI-engine
⭐️ GoBigger Repo Github 链接:
https://github.com/opendilab/GoBigger
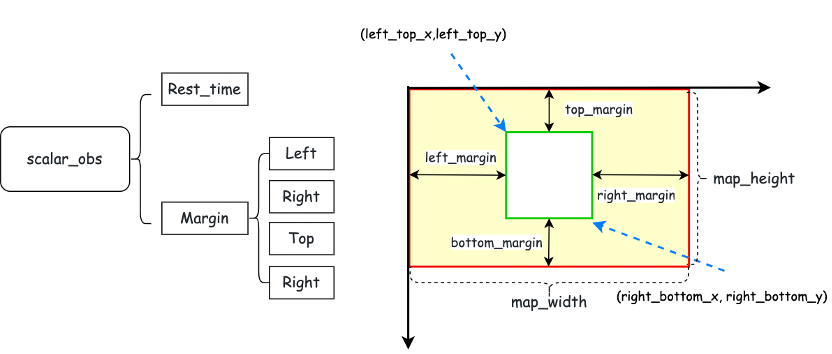
1.对全局信息进行编码
在Pygame中,默认坐标原点为左上角。如下图所示,图中红色矩形为全局视野,绿色矩形为局部视野
全局信息由两部分组成,一部分是时间信息,另一部分是边缘信息
时间信息是对距离比赛结束的剩余时间进行特征抽象
边缘信息是对局部视野与整个地图边缘之间距离的特征抽象

2.对clone球ID信息预处理
对每个clone球team ID进行预处理,clone球所属team的ID始终为0,其他队伍的 id依次为1、2、··· team_num-1
对每个clone球Player ID进行预处理,clone球所属Player的ID始终为0,同一个队伍其他玩家的Player ID依次为1、2 ··· player_num_per_team - 1

3.对food信息进行编码
为方便计算,面积计算采用半径的平方,省去常数项。同时,我们将food和spore都看作为食物球
food map将局部视野进行切分为h*w个小格子,每个小格子的大小为16*16
food map[0,:,:]表示落在每个小格子中food的累积面积
food map[1,:,:]表示落在每个小格子中当前id的clone ball的累积面积
food grid将局部视野进行切分为h*w个小格子,每个小格子的大小为8*8
food grid表示每个小格子中food相对于所属格子的左上角的偏移量以及food的半径
food relation 的维度是[len(clone),7*7+1,3]。其中[:,7*7,3]表示每个clone ball的7*7网格邻域中food的信息,包括偏移量以及网格中food面积平方和。
因为覆盖率很低,在这里做了一个近似,food的位置信息以最后一个为准。[len(clone):,1,3]表示每个clone ball自身的偏移量以及面积。

对clone ball进行编码,包括位置、半径、玩家名称的one-hot编码以及clone ball的速度编码

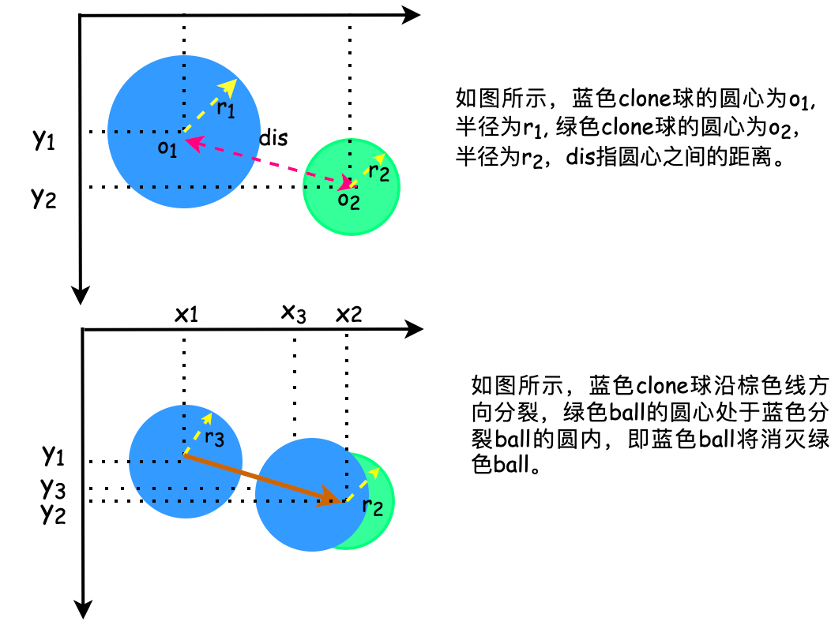
4.对关系进行编码
ball_1 与ball_2 的相对位置大小关系,(x1-x2,y1-y2)
ball_1 与ball_2 的距离,即o1与o2之间的距离dis
ball_1 与ball_2 的吞并是一个球的圆心出现在另一个球中,即发生吞并
ball_1 与ball_2 是否相互吞并,即一个球的圆形边缘与另一个球圆心之间的距离
ball_1 与ball_2 分裂后相互吞并,即分裂后最远的分裂球的圆形边缘与另一个球圆心之间的距离
ball_1 与ball_2 吃与被吃关系,即两球之间的半径大小关系
ball_1 与ball_2 分裂后吃与被吃关系,即分裂后两球之间的半径大小关系
ball_1 与ball_2 各自的半径做映射, 分别为m*n个r1 和m*n个r2, m表示ball_1的数量,n表示ball_2的数量

5.模型设计
网络结构主要采用MLP以及Pooling层
mask的作用,记录padding后的有效信息。需结合代码理解更佳
Baseline中的model设计并不是最好的,选手可以尽情脑洞

6.RL策略
采用最经典的DQN算法+离散动作空间(4*4笛卡尔积)
在OpenDILab中,已经实现了一些必备的DQN组件,比如,经验回放队列(replay buffer),为了平衡探索和利用所用的eps-greedy等等
7.标准对局怎么打
安装必要的依赖库
# Install DI-enginegit clone https://github.com/opendilab/DI-engine.gitcd YOUR_PATH/DI-engine/pip install -e . --user# Install Env Gobiggergit clone https://github.com/opendilab/GoBigger.gitcd YOUR_PATH/GoBigger/pip install -e . --user
开始训练
# Download baselinegit clone https://github.com/opendilab/Gobigger-Explore.gitcd my_submission/entry/python gobigger_vsbot_baseline_main.py
评估并保存视频
cd my_submission/entry/python gobigger_vsbot_baseline_eval.py --ckpt YOUR_CKPT_PATH
8.Tips
采用连续动作空间或者混合动作空间使得智能体操作更加丝滑
设计新的Reward奖励使得智能体变得攻守兼备
采用合适的策略使得智能体学会相互配合以及更高级的动作