
HTTP协议与HTTPS的加密流程
一、HTTP基础知识
HTTP全称Hyper Text Transfer Protocol,即超文本传输协议。HTTP是一个应用层协议,可视为一个在计算机世界里专门在两点之间传输文字、图片、音频、视频等超文本数据的约定和规范。
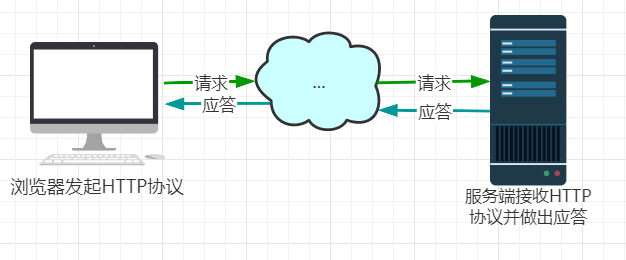
1. HTTP请求流程
我们这里就直接以一个常见的面试题引入啦。
在浏览器中输入 www.baidu.com 后会发生什么?
当一个用户在浏览器里输入 www.baidu.com 这个 URL 时,将会发生很多操作。首先它会请求 DNS 把这个域名解析成对应的 IP 地址,然后根据这个 IP 地址在互联网上找到对应的服务器,向这个服务器发起一个GET 请求,由这个服务器决定返回默认的数据资源给访问用户。在服务器端实际上还有很复杂的逻辑:服务器可能有好多台,到底指定哪台服务器来处理请求,这需要一个负载均衡设备来平均分配所有用户的请求;还有请求的数据是存储在分布式缓存里还是一个静态文件中,或是在数据库里;当数据返回浏览器时,浏览器解析数据发现还有一些静态资源(如 CSS、JS 或者图片)时又会发起另外的 HTTP 请求,而这些请求有可能会在 CDN 上,那么 CDN 服务器又会处理这个用户的请求,大体上一个用户请求会涉及这么多操作。每一个细节都会影响这个请求最终是否会成功。
我们不去涉及其中过多的知识,单说HTTP的请求流程即可,从上面我们知道,HTTP协议是由客户端发起的,由请求和响应构成,是一个标准的客户端服务器模型(C/S),它的具体流程如下:
地址解析。域名系统DNS解析域名得到主机的IP地址;
封装HTTP请求数据包。封装的内容有以上部分结合本机自己的信息;
封装成TCP包,建立TCP连接(TCP的三次握手);
客户机发送请求命令。建立连接后,客户机向服务器发送一个请求;
服务器响应。服务器接到请求后,给予相应的响应信息;
服务器关闭TCP连接。一般Web服务器向浏览器发送了请求数据,它要关闭TCP连接;
客户端解析报文。客户端接收到响应报文后解析HTML代码,并渲染。
2. 常见状态码
HTTP常见的状态码分为五大类,如下表所示:
| 状态码类别 | 具体含义 | 常见状态码 |
|---|---|---|
| 1xx | 提示信息,表示目前是协议处理的中间状态,还需要后续的操作 | |
| 2xx | 成功,报文已经收到并被正确处理 | 200、204、206 |
| 3xx | 重定向,资源位置发生变动,需要客户端重新发送请求 | 301、302、304 |
| 4xx | 客户端错误,请求报文有误,服务器无法处理; | 400、403、404 |
| 5xx | 服务器错误,服务器在处理请求时内部发生了错误。 | 500、501、502、503 |
1xx:
1xx类状态码属于提示信息,是协议处理中的一种中间状态,实际用到的比较少。2xx:
2xx类状态码表示成功处理了客户端需求,也是我们浏览器发起请求时常见的状态:【200 OK】:最常见的成功状态码,表示一切正常。如果是非
HEAD请求,服务器返回的响应头都会有 body 数据;【204 No Content】:也是常见的成功状态码,与 200 OK 基本相同,但响应头没有 body 数据;
【206 Partial Content】:是应用于 HTTP 分块下载或断点续传,表示响应返回的 body 数据并不是资源的全部,而是其中的一部分,也是服务器处理成功的状态;
3xx:
3xx类状态码表示客户端请求的资源发生了变动,需要客户端用新的 URL 重新发送请求获取资源,也就是重定向:注:301 和 302 都会在响应头里使用
Location,指明后续要跳转的 URL,浏览器会自动重定向新的 URL。【301 Moved Permanently】:表示永久重定向,说明请求的资源已经不存在了,需改用新的 URL 再次访问;
【302 Found】:表示临时重定向,说明请求的资源还在,但暂时需要用另一个 URL 来访问;
4xx:
4xx类状态码表示客户端发送的报文有误,服务器无法处理,也就是错误码的含义:【400 Bad Request】:表示客户端请求的报文有错误,但只是个笼统的错误;
【403 Forbidden】:表示服务器禁止访问资源,并不是客户端的请求出错;
【404 Not Found】:表示请求的资源在服务器上不存在或未找到,所以无法提供给客户端。
5xx:
5xx类状态码表示客户端请求报文正确,但是服务器处理时内部发生了错误,属于服务器端的错误码:【500 Internal Server Error】:与400类似,是个笼统通用的错误码,服务器发生了什么错误,我们并不知道;
【501 Not Implement】:表示客户端请求的功能还不支持,类似”即将开业,尽情期待“的意思;
【502 Bad Gatwy】:通常是服务器作为网关或代理时返回的错误码,表示服务器自身工作正常,访问后端服务器发生了错误;
【503 Service Unavailable】:表示服务器当前很忙,暂时无法响应服务器,类似”网络服务正忙,请稍后重试“的意思。
3. 常见字段
首先我们了解一下HTTP的报文结构,大概如下:
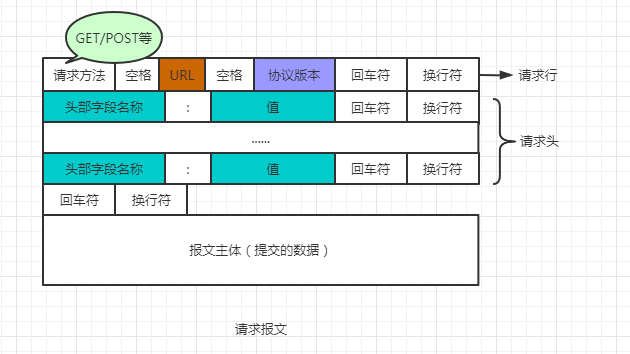
这是常见的请求报文,当然还有响应报文,两者之间并不完全一致,这里只简单提及一下请求报文的格式。
首先是请求方法,常见的请求方法有 GET和POST两种,之后跟着的是URL,即要访问的地址,再后面跟着的就是协议版本,如:HTTP/1.1。
我们主要讲解之后跟着的字段,即请求头,请求头的字段常以key-value的形式,即”属性名:属性值“的形式传递若干数据,服务端据此获取客户端的信息。接下来我们就来了解常见的字段:
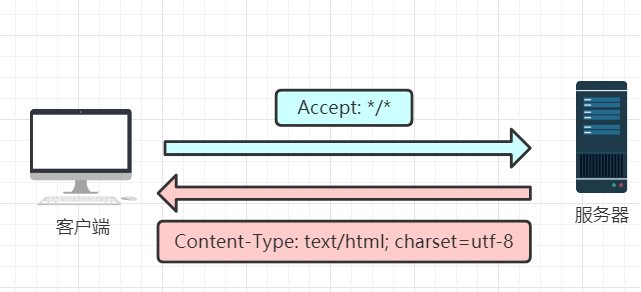
Accept字段与Content-type字段:
Accept字段用于客户端向服务器发送报文时表示自己可接收的响应内容类型,如:Accept:text/plain (文本类型);
类似的字段还有Accept-Charset 表示可接收的字符集;Accept-Encoding表示可接受的响应内容的压缩方式 ;Accept-Language表示可接受的响应内容语言列表;Accept-Datetime表示可接受的按照时间来表示的响应内容版本。
Content-Type字段用于服务器回应时,告诉客户端,本次数据的格式是什么。
类似的字段还有Content-Encoding字段表示数据的压缩方法,表示服务器返回的数据使用什么压缩格式。
Host字段Host字段用于客户端发送请求时,用来指定服务器的域名。例如:
Host:www.baidu.com。这里需要与报文中的请求行的 URL 区分,Host字段与 URL 组成完整的请求URL,例如请求行中的URL为/getPerson,而Host字段为www.baidu.com,那么两者结合起来就是www.baidu.com/getPerson。Connection字段Connection字段最常用于客户端要求服务器使用 TCP 持久连接,以便其他请求复用。
Connection: keep-alive扩展:
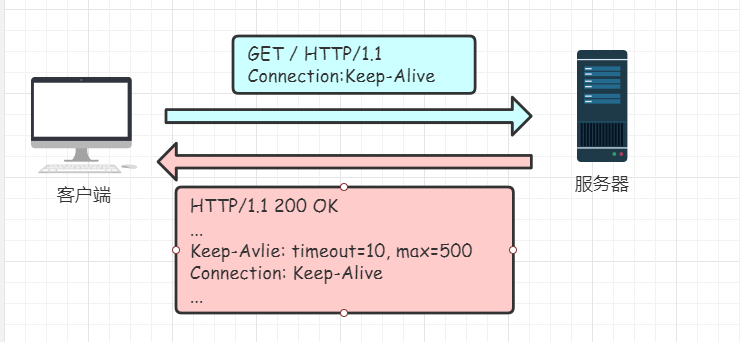
HTTP是无状态的面向连接的协议,无状态并不代表HTTP不能保持TCP连接,HTTP使用的不是UDP(无连接);
HTTP/1.1 版本的默认连接都是持久连接,但为了兼容老版本的 HTTP,需要指定
Connection首部字段的值为Keep-Alive。简单的说,当一个网页打开完成后,客户端和服务器之间用于传输的 HTTP 数据的 TCP 连接不会立刻关闭,如果客户端再次访问这个服务器上的网页,会继续使用这一条已经建立的连接;Keep-Alive不会永久保持连接,它有一个保持时间,可以在不同的服务器软件(如Apache)中设定这个时间。
Content-Length字段服务器在返回数据时,会有
Content-Length字段,表明本次回应的数据长度。例如:Content-Length: 1000,这表明了服务器本次回应的数据长度是1000个字节,后面的字节就属于下一个回应了。
二、 HTTP存在的问题
1. 性能问题
在 HTTP/1.0 中有很大的性能问题,每次发起一个HTTP请求,都需要去建立一次TCP连接,而且还是串行请求,这使得 HTTP 在 TCP 的连接建立上花费了大量的开销。对于这种问题,HTTP/1.1 中提出了长连接的通信方式,也叫持久连接。这种连接的好处在于减少了 TCP 连接的重复建立和断开所造成的额外开销,减轻了服务器端的负载:
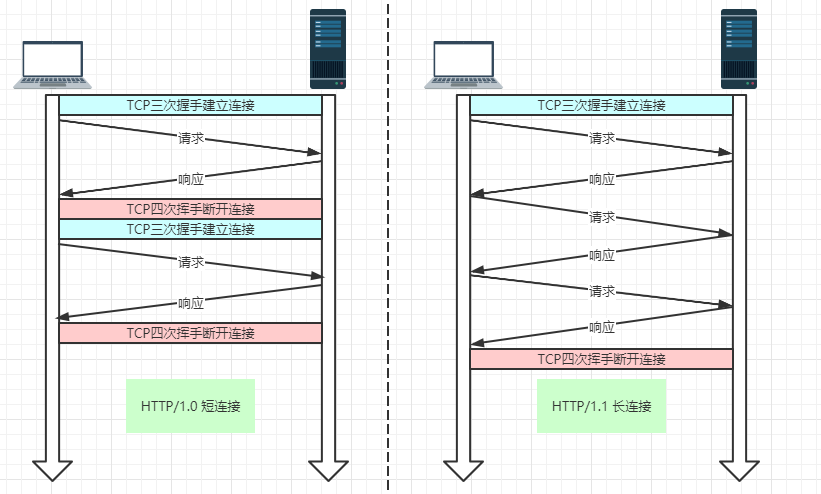
HTTP/1.1 采用了长连接的方式,这使得管道(Pipeline)网络传输成为了可能。即可在同一个 TCP 连接里面,客户端可以发起多个请求,只要第一个请求发出去了,不必等其回来,就可以发第二个请求出去,可以减少整体的响应时间。
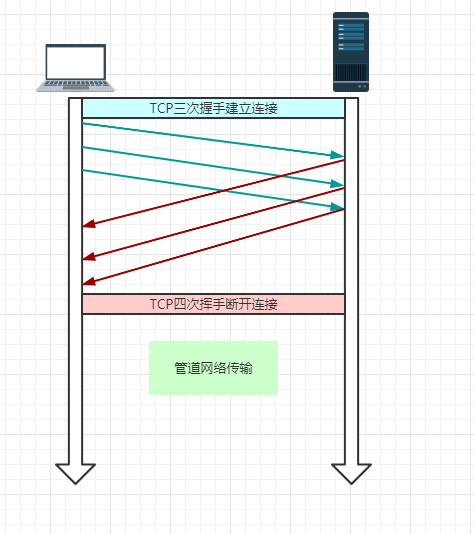
但是服务器还是按照顺序,先回应第一个请求,完成后再回应第二个请求,以此类推。要是前面的请求回应得特别慢,后面就会有许多请求阻塞着,这就是所谓的【队头阻塞】。
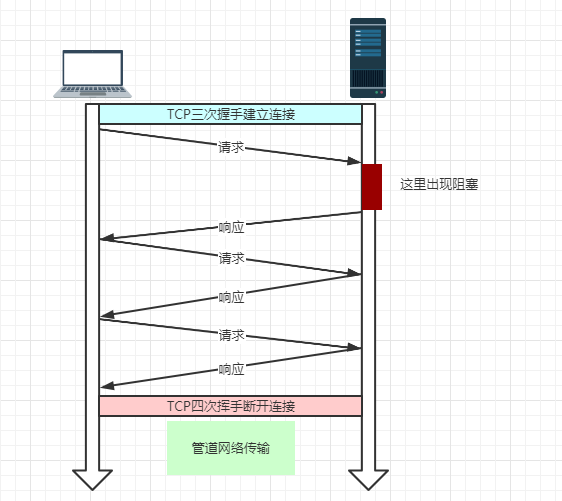
所以 HTTP/1.0 或是 HTTP/1.1 性能都不是很完美,所以后续会有其他加强。
2. 安全问题
HTTP的内容是明文传输的,明文数据会经过中间代理服务器、路由器、WIFI热点、通信服务运行商等多个物理节点,如果信息在传输过程中被劫持,传输的内容久完全暴露了,劫持者还可以篡改传输的信息且不被双方察觉,这就是中间人攻击。
总结一下,HTTP在安全方面有以下三个问题:
使用明文通信,一些重要的内容会被窃听;
不能验证对方身份,可能是伪造的信息;
无法验证报文的完整性,有可能被修改;
三、HTTPS的实现
针对上面我们提到的HTTP的安全问题,HTTPS 在 HTTP 的基础上增加了加密处理、认证机制和完整性保护,我们可以将 HTTPS = HTTP + 加密 + 认证 + 完整性保护;
1. 加密
因为 HTTP 使用明文传输,中间会经过多个物理节点,可能会被劫持窃听,针对这一问题,HTTPS 采用了加密的方式解决。最容易理解的就是对称加密。
1.1 对称加密
对称加密好理解,就是我们拥有一个密钥,它可以用来对一段内容进行加密,同样的,在内容被进行加密后,需要用同一个密钥对加密内容进行解密,才能看到原本的内容,可以看作我们日常生活中的钥匙。
HTTP 可以直接使用对称加密吗?
当然不可以。如果通信双方各自持有同一个密钥,且没有第三方知晓,那么这两方之间的通信安全是可以被保证的(毕竟密钥被破解可能性不大)。问题是”如何使得这个密钥可以让传输的双方知晓,同时不被别人知道“?
假如我们现在浏览器生成一个密钥然后发送到服务端,告诉服务端我们双方用这个密钥来加密传输文件。或者是放过来,由服务器生成密钥然后发送给浏览器。很明显这就不现实,我们知道 HTTP 传输时中间是需要经过许多个中间节点的,在经过中间节点时这个密钥被劫持下来是一件十分容易的事,所以这种方式不可取。由此引入非对称加密。
1.2 非对称加密
非对称加密有两把密钥,通常一把叫做公钥,另外一把叫做私钥。用公钥加密的内容必须用私钥才能解开,同样的,私钥加密的内容需要用公钥才能解开。
HTTP 可以直接使用非对称加密吗?
还是不可以。鉴于非对称加密的性质,我们可能会有这种思路:服务器先把公钥直接明文传输给浏览器,之后浏览器向服务器传数据前都先用这个公钥加密好再传输,这条数据似乎可以保障了,因为只有服务器端的相应私钥能解开这条数据。但是这样还是有问题,密钥还是可以被劫持的。
如果服务器用它的的私钥加密数据传给浏览器,那么浏览器用公钥可以解密它,而这个公钥是一开始通过明文传输给浏览器的,如果这个公钥被谁劫持到的话,他也能用该公钥解密服务器传来的信息了。所以这种方式的实现还是会有问题,似乎只能保证由浏览器传输数据时的安全性(其实还有漏洞)。
1.3 改良版非对称加密
通过一组公钥、私钥已经能保证单个方向传输的安全性,那用两组公钥私钥是不是就能保证双向传输都安全了,以下面流程为例:
某网站拥有用于非对称加密的公钥 A、私钥 A‘,浏览器拥有用于非对称加密的公钥 B、私钥 B’ ;
浏览器向网站服务器发起请求,服务器把公钥 A 明文传输给浏览器;
浏览器将公钥 B 明文传输给服务器;
之后浏览器向服务器传输的所有东西都用公钥 A 加密,服务器收到后用私钥 A’ 解密。由于只有服务器拥有这个私钥 A’ 可以解密,所以能保证这条数据的安全;
服务器向浏览器传输的所有东西都用公钥 B 加密,浏览器收到后用私钥 B’ 解密。同上也可以保证这条数据的安全。
这种实现方式理论上确实可行,抛开这里面仍有的漏洞不谈(下文再述),HTTPS 的加密却没有使用这种方案,为什么?
最主要的原因是非对称加密算法非常耗时,特别是加密解密一些较大数据的时候有些力不从心。相比之下,对称加密就要快很多,那能不能同时运用对称加密与非对称加密的性质来实现对 HTTP 的加密呢?
1.4 混合加密
既然非对称加密耗时,那么就用“对称加密 + 非对称加密”结合的形式来实现对 HTTP 的加密,而且还得尽量减少非堆成加密的次数 ,这样是否能实现呢?
这种方式是可以实现的,而且非对称加密、解密各只需要用一次即可。请看以下过程:
某网站拥有非对称加密的公钥 A、私钥 A‘ ;
浏览器向网站服务器发起请求,服务器把公钥 A 明文传输给浏览器;
浏览器随机生成一个用以对称加密的密钥 X,用公钥 A 加密后传给服务器;
服务器端拿到加密的密钥后,用公钥 A 解密得到密钥 X;
这样双方就都拥有密钥 X 了,且别人无法知道它,之后双方所有数据都用密钥 X 进行加密解密。
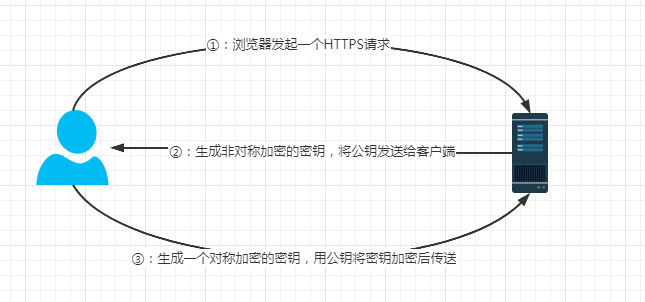
HTTPS 基本上就是采用了这种方案了,当然这种方法还是有漏洞,我们接着往下讲。
2. 认证
2.1 中间人攻击
根据上面的混合加密过程,中间人确实无法拥有浏览器生成的对称密钥 X,这个密钥本身就被公钥 A 给加密了,只有服务器才能通过私钥 A‘ 对其进行解密。然而在这个过程中中间人完全不需要获取到密钥 A’ 就能进行攻击了。如下流程所示:
某网站拥有用于非对称加密的公钥A、私钥A’ ;
浏览器向网站服务器发起请求,服务器把公钥 A 明文给传输浏览器;
中间人劫持到公钥A,保存下来,把数据包中的公钥A替换成自己伪造的公钥B(它当然也拥有公钥B对应的私钥B’);
浏览器随机生成一个用于对称加密的密钥X,用公钥B(浏览器不知道公钥被替换了)加密后传给服务器;
中间人劫持后用私钥 B’ 解密得到密钥 X,再用公钥 A 将 X 加密后传给服务器;
服务器拿到后用私钥A’解密得到密钥X。
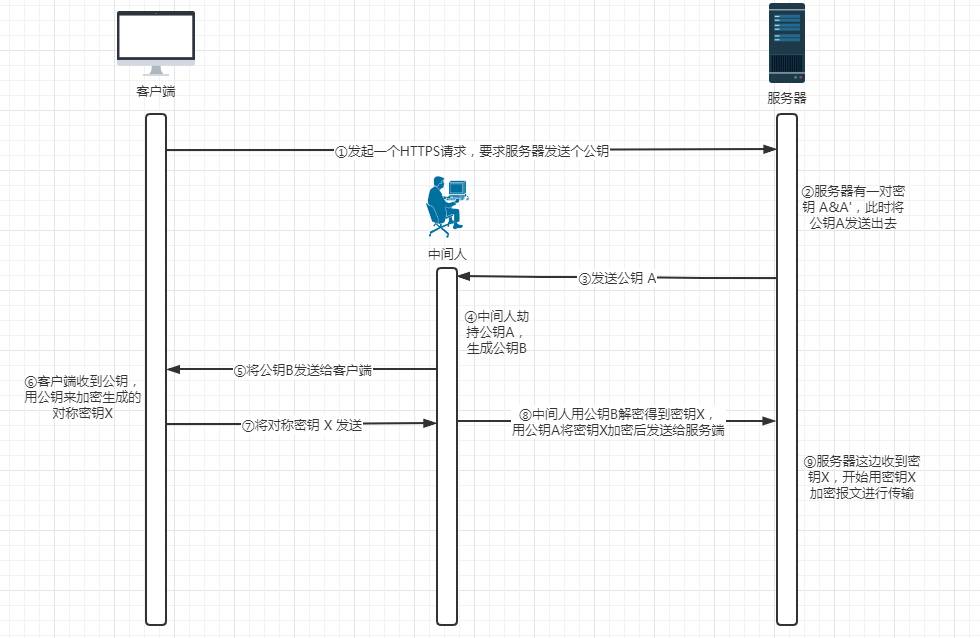
这样在双方都不会发生异常的情况下,中间人得到了密钥 X,这其中的根本原因就是浏览器无法确认自己收到的公钥是不是网站的。那么接下来就是要解决这一问题。
2.2 数字证书
如何证明浏览器收到的公钥一定是该网站的公钥?这里就需要有一个公信机构给网站颁发一个“身份证”了。网站在使用 HTTPS 前,需要向“CA机构”申请颁发一份数字证书,数字证书里有证书持有者、证书持有者的公钥等信息,服务器把证书传输给浏览器,浏览器从证书里取公钥就行了,证书就如同身份证一样,可以证明“该公钥对应该网站”。
然而到这里还是有一个问题,如何保证证书在传输的过程不会被篡改,身份证本身有防伪的技术,那么如何保证证书的防伪呢?
2.3 数字签名
如何保证证书不被篡改?
我们把证书内容生成一份“签名”,比对证书内容和签名是否一致就能察觉是否被修改,这种技术就称为数字签名;
数字签名的制作过程?
CA 拥有非对称加密的私钥和公钥;
CA 对证书明文信息进行 Hash;
对 Hash 后的值用私钥加密,得到数字签名S;
将明文和数字签名共同组成数字证书,这样一份证书就可以颁发给网站了。
浏览器得到证书后如何验证这份证书的真实性?
拿到服务器发送过来的证书,得到明文T,数字签名S;
用CA机构的公钥对 S 解密(由于是浏览器信任的机构,所以浏览器保有CA的公钥),得到S‘;
浏览器用证书说明的 Hash 算法对明文 T 进行 Hash 得到 T’;
比较 S‘ 是否等于 T’,等于则代表证书可信。

浏览器如何得到权威机构的公钥?
上面提到,如何要对服务器发过来的证书进行解密,那么就需要到CA的公钥,因为其被CA的私钥给加密了。那么浏览器是如何拥有CA的公钥呢?
实际上权威机构的公钥并不需要传输,因为权威机构会和主流的浏览器或操作系统合作,将他们的公钥内置在浏览器或操作系统环境中。客户端收到证书之后,只需要从证书中找到权威机构的信息,并从本地环境中找到权威机构的公钥,就能正确解密A公钥。当然实际情况要比这个复杂得多,这里简单介绍就行。
中间人有可能篡改证书吗?
上面我们提到,权威机构的公钥是可能在浏览器或操作系统中的,那么中间人劫持到证书后是可以解密得到原文的。相应的,他也可以去篡改证书的原文,但是由于他没有 CA 机构的私钥,无法相应地篡改签名。所以浏览器收到证书后会发现原文和解密后的值不一致,说明证书已经被篡改,证书不可信了,所以中间人不可能去篡改证书了。
四、HTTPS的请求流程
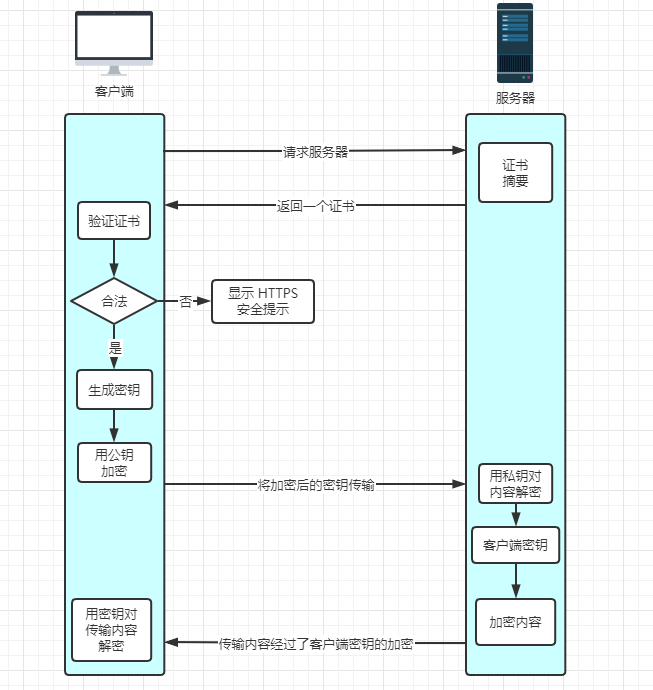
客户端向服务器发起 HTTPS 请求,连接到服务器的 443 端口;
服务器端有一个密钥对,即公钥和私钥,是用来进行非对称加密使用的,服务器端保存着私钥,不能将其泄露,公钥可以发送给任何人;
服务器将自己的公钥包含在权威机构发布的证书中发送给客户端;
客户端收到服务器端的证书之后,会对证书进行检查,验证其合法性,如果发现发现证书有问题,那么HTTPS传输就无法继续。严格的说,这里应该是验证服务器发送的数字证书的合法性,关于客户端如何验证数字证书的合法性。如果公钥合格,那么客户端会生成一个随机值,这个随机值就是用于进行对称加密的密钥,我们将该密钥称之为
client key,即客户端密钥,这样在概念上和服务器端的密钥容易进行区分。然后用服务器的公钥对客户端密钥进行非对称加密,这样客户端密钥就变成密文了,至此,HTTPS中的第一次HTTP请求结束;客户端会发起 HTTPS 中的第二个 HTTP 请求,将被公钥所加密之后的客户端密钥发送给服务器;
服务器接收到客户端发来的密文之后,会用自己的私钥对其进行非对称解密,解密之后的明文就是客户端密钥,然后用客户端密钥对数据进行对称加密,这样数据就变成了密文。
然后服务器用对称加密的密钥(即客户端密钥)对报文进行加密,并将加密后的报文发送给客户端;
客户端收到服务器发送来的密文,用客户端密钥对其进行对称解密,得到服务器发送的数据。这样 HTTPS 中的第二个 HTTP 请求结束,整个 HTTPS 传输完成。
文章内容绝大数来源网络,我只是个搬运工,若有哪里出错,请评论区指出。

腾讯、阿里、滴滴后台面试题汇总总结 — (含答案)
面试:史上最全多线程面试题 !
最新阿里内推Java后端面试题
JVM难学?那是因为你没认真看完这篇文章

关注作者微信公众号 —《JAVA烂猪皮》
了解更多java后端架构知识以及最新面试宝典

看完本文记得给作者点赞+在看哦~~~大家的支持,是作者源源不断出文的动力
作者: 周二鸭
出处:https://www.cnblogs.com/jojop/p/14111938.html