
更快更强,ElasticSearch 8.0.0 正式发布!
点击上方蓝色字体,选择“设为星标”
回复"面试"获取更多惊喜

Hi,我是王知无,一个大数据领域的原创作者。
放心关注我,获取更多行业的一手消息。
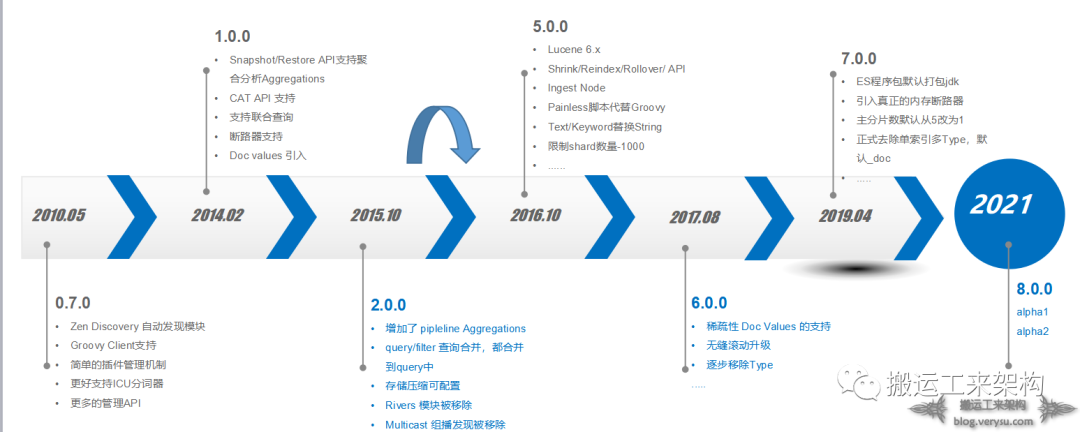
7.x REST API 兼容性
安全功能在默认情况下被启用和配置
已知问题:
如果你在 Linux ARM 或 macOS M1 等 arch64 平台上从归档中安装 Elasticsearch,那么在首次启动节点时,不会自动生成 elastic 用户密码和 Kibana 注册令牌。节点启动后,需要用 bin/elasticsearch-reset-password 工具生成 elastic 密码:
然后,用 bin/elasticsearch-create-enrollment-token 工具为 Kibana 创建一个注册令牌:
更好地保护系统索引
新的 KNN 搜索 API
_score查询。虽然这种方法保证了准确的结果,但它往往导致搜索速度缓慢,而且在大型数据集上不能很好地扩展。作为对较慢的索引和不完美的准确性的交换,新的 KNN 搜索 API 让你在更大的数据集上以更快的速度运行近似的 KNN 搜索。为 keyword、 match_only_text和 text字段节省存储空间
加快 geo_point、geo_shape和范围字段索引速度
PyTorch 模型支持自然语言处理(NLP)
其他变化
删除邻接 matrix 设置 #46327 (issues: #46257 , #46324 ) 删除 MovingAverage 管道聚合 #39328 删除弃用的 _time和_term排序 #39450删除弃用的日期历史间隔 #75000
删除 include_relocations 设置 #47717 (issues: #46079, #47443)
清理分析中的版本化弃用 #41560 (issue: #41164 ) 删除预先配置的 delimited_payload_filter #43686 (issues: #41560, #43684)
除非明确禁用,否则始终添加文件和本机 Realm #69096 (issue: #50892 ) 默认情况下不要在 Policy 中设置 NameID 格式 #44090 (issue: #40353 ) 为 Realm 配置强制设置顺序 #51195 (issue: #37614 )
删除连接超时 #60873 (issue: #60872 ) 删除对延迟状态恢复挂起主控器的支持 #53845 (issue: #51806 )
删除同步刷新 #50882 (issues: #50776 , #50835 ) 删除 cluster.remote.connect 设置 #54175 (issue: #53924)
强制合并应该拒绝设置了 only_expunge_deletes 和 max_num_segments 的请求 #44761 (issue: #43102) 删除每个类型的索引统计 #47203 (issue: #41059 ) 移除 translog 保留设置 #51697 (issue: #50775 )
为 _cat/indices删除废弃的 local 参数 #64868 (issue: #62198)为 _cat/shards删除废弃的 local 参数 #64867 (issue: #62197)
默认 cluster.routing.allocation.enforce_default_tier_preference 为 true #79275 (issues: #76147, #79210)
将 prefer_v2_templates 参数默认值设为 true #55489 (issues: #53101, #55411) 删除弃用的 _upgrade API#64732 (issue: #21337)从 REST 层移除参数 include_type_name 删除索引模板中的 template 字段 #49460 (issue: #21009)
从数据路径中删除 nodes/0 文件夹前缀 删除 bootstrap.system_call_filter 设置 #72848 删除 node.max_local_storage_nodes #42428 (issue: #42426) 删除 Joda 依赖 #79007 删除命名日期/时间格式的驼峰式大小写 #60044
删除 SysV 初始化支持 #51716 删除对 JAVA_HOME 的支持 #69149 需要 Java 17 才能运行 Elasticsearch #79873
https://www.elastic.co/cn/blog/whats-new-elastic-8-0-0
如果这个文章对你有帮助,不要忘记 「在看」 「点赞」 「收藏」 三连啊喂!

2022年全网首发|大数据专家级技能模型与学习指南(胜天半子篇)
Flink CDC我吃定了耶稣也留不住他!| Flink CDC线上问题小盘点
4万字长文 | ClickHouse基础&实践&调优全视角解析
评论