
《Kafka成神之路》- 索引类型
共 2403字,需浏览 5分钟
·
2020-12-05 21:58
点击上方“JavaEdge”,关注公众号
在Kafka的数据路径下:
.index文件,即Kafka中的位移索引文件.timeindex文件,即时间戳索引文件
不同索引类型保存不同的 K.V 对。

1 OffsetIndex - 位移索引

1.1 定义

用于根据位移值快速查找消息所在文件位置。
每当Consumer要从topic分区的某位置开始读消息,Kafka就会用OffsetIndex直接定位物理文件位置,避免从头读取消息的昂贵I/O开销。
OffsetIndex的组成:
K,维护消息的相对偏移
V,维护该消息的日志段文件中该消息第一个字节的物理文件位置
相对偏移
AbstractIndex类中的抽象方法entrySize定义了单个K.V对所用的字节数。
OffsetIndex的entrySize就是8,如OffsetIndex.scala中定义的那样:
相对位移是个Integer,4字节,物理文件位置也是一个Integer,4字节,因此共8字节。
Kafka的消息位移值是一个长整型(Long),应占8字节。在保存OffsetIndex的K.V对时,Kafka做了一些优化。每个OffsetIndex对象在创建时,都已保存了对应日志段对象的起始位移,因此,OffsetIndex无需保存完整8字节位移值。实际上,只需保存与起始位移的差值,该差值整型存储足矣。这种设计就让OffsetIndex每个索引项都节省4字节。
假设某一索引文件保存1000个索引项,使用相对位移值就能节省大约4M。
AbstractIndex定义了relativeOffset方法
将一个Long位移值转换成相对偏移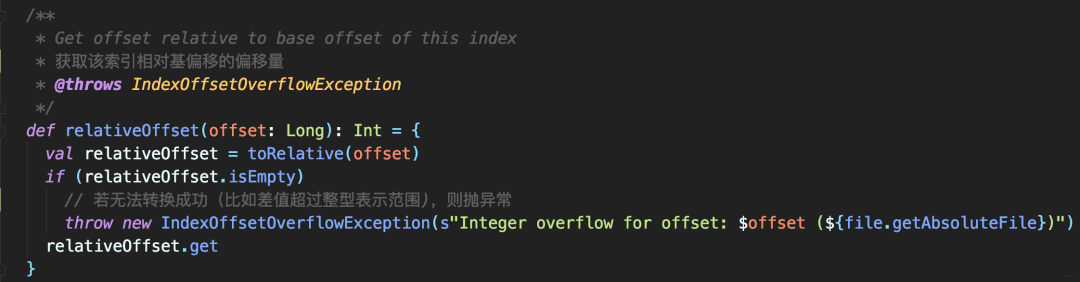
真正的转换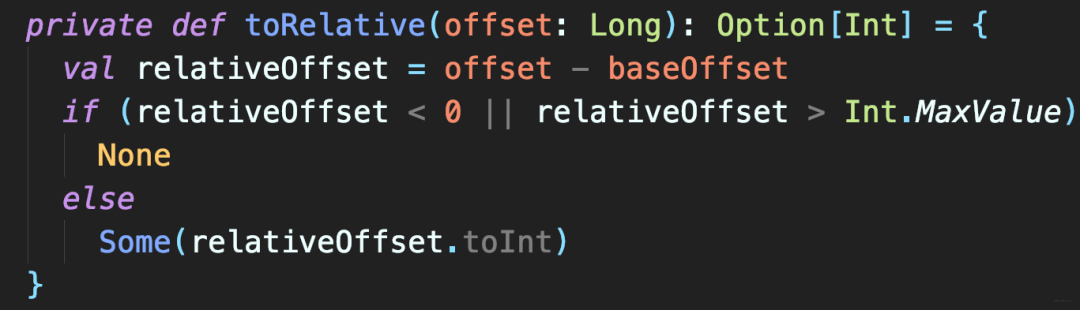
读取OffsetIndex时,还需将相对偏移值还原成之前的完整偏移。
parseEntry:构造OffsetPosition所需的Key和Value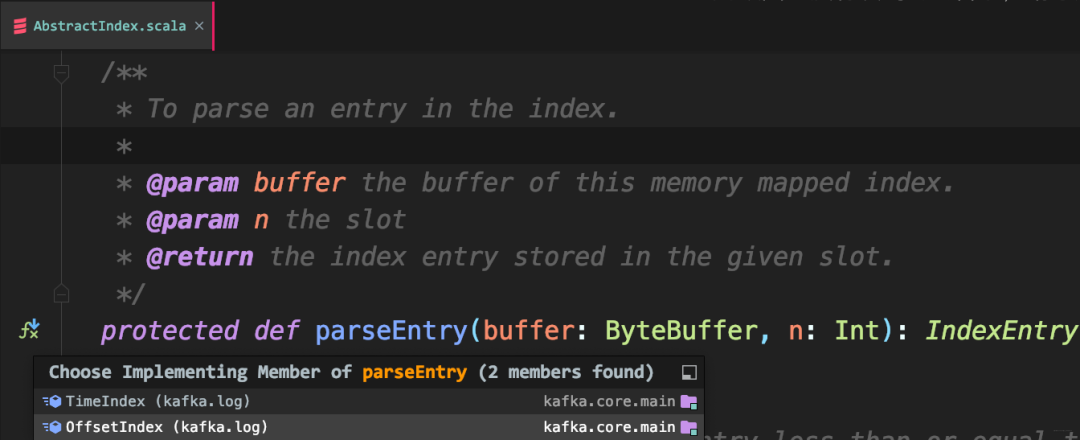

该方法返回OffsetPosition类型。因为该类的俩方法分别返回索引项的K、V。
physical
写索引项 - append
通过Long位移值和Integer物理文件位置参数,然后向mmap写入相对位移值、物理文件位置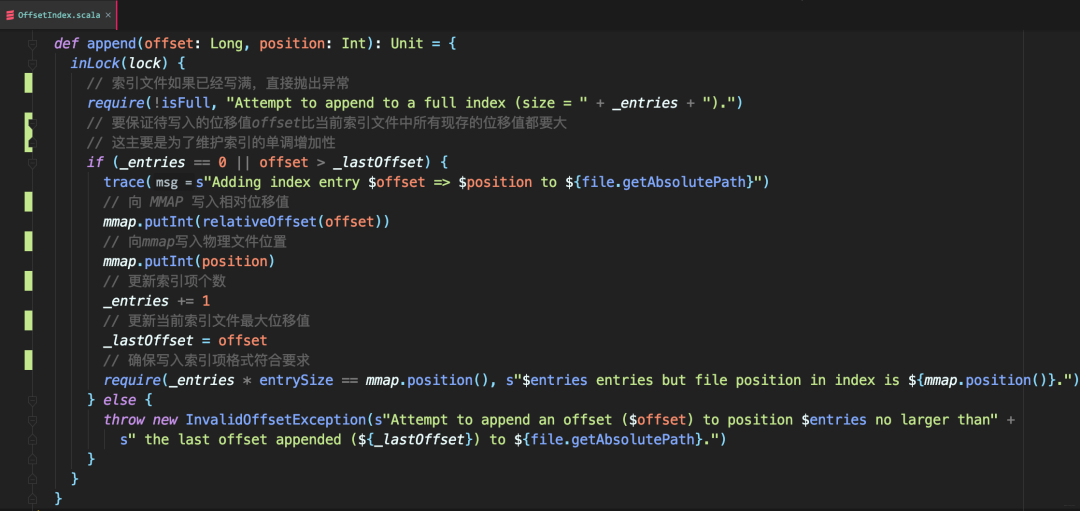
Truncation 截断
将索引文件内容直接裁剪掉部分。比如,OffsetIndex索引文件中当前保存100个索引项,现在只想保留最开始40个索引项。
truncateToEntries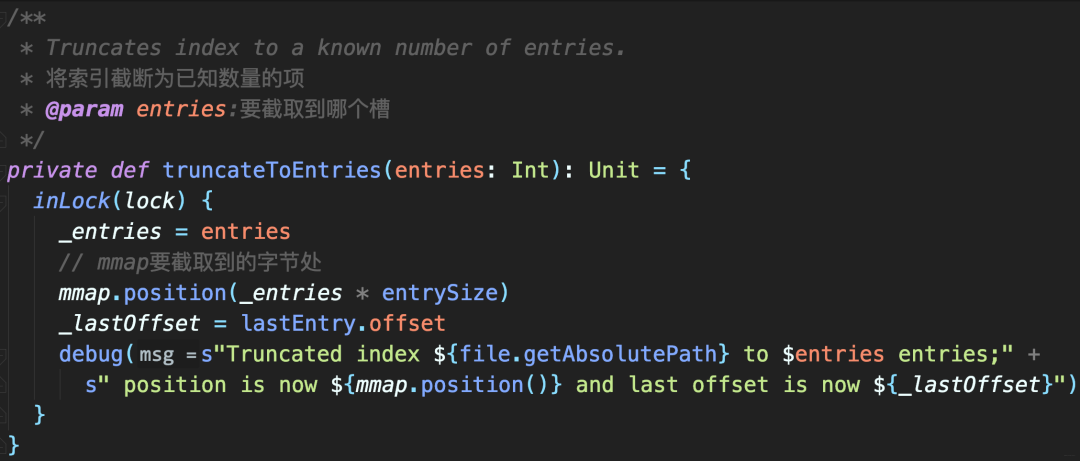
使用OffsetIndex
OffsetIndex被用来快速定位消息所在的物理文件位置,那么必然需定义一个方法执行对应的查询逻辑。这个方法就是lookup。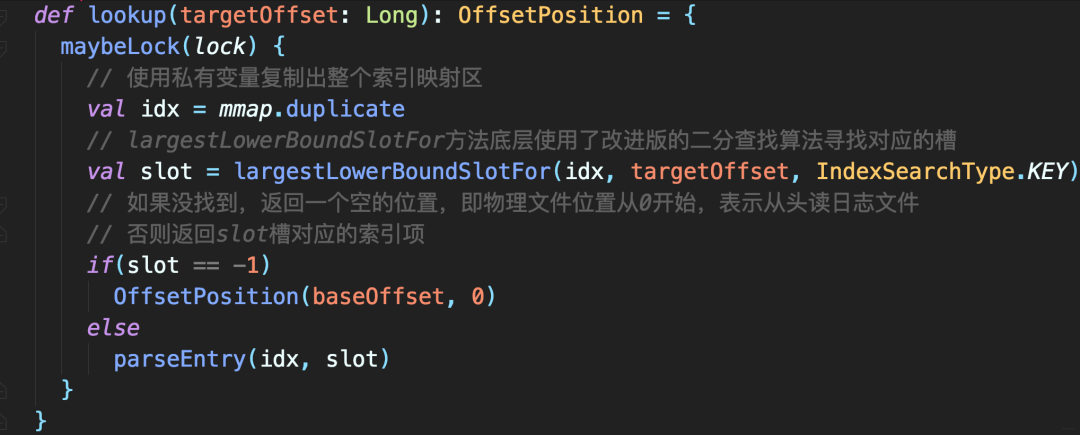
该方法返回的,是不大于给定位移值targetOffset的最大位移值,以及对应的物理文件位置。你大致可以把这个方法,理解为位移值的FLOOR函数。
2 TimeIndex - 时间戳索引
2.1 定义
用于根据时间戳快速查找特定消息的位移值。
TimeIndex保存<时间戳,相对位移值>对:
时间戳需长整型存储
相对偏移值使用Integer存储
因此,TimeIndex单个索引项需要占12字节。
存储同数量索引项,TimeIndex比OffsetIndex占更多磁盘空间。
2.2 写索引
maybeAppend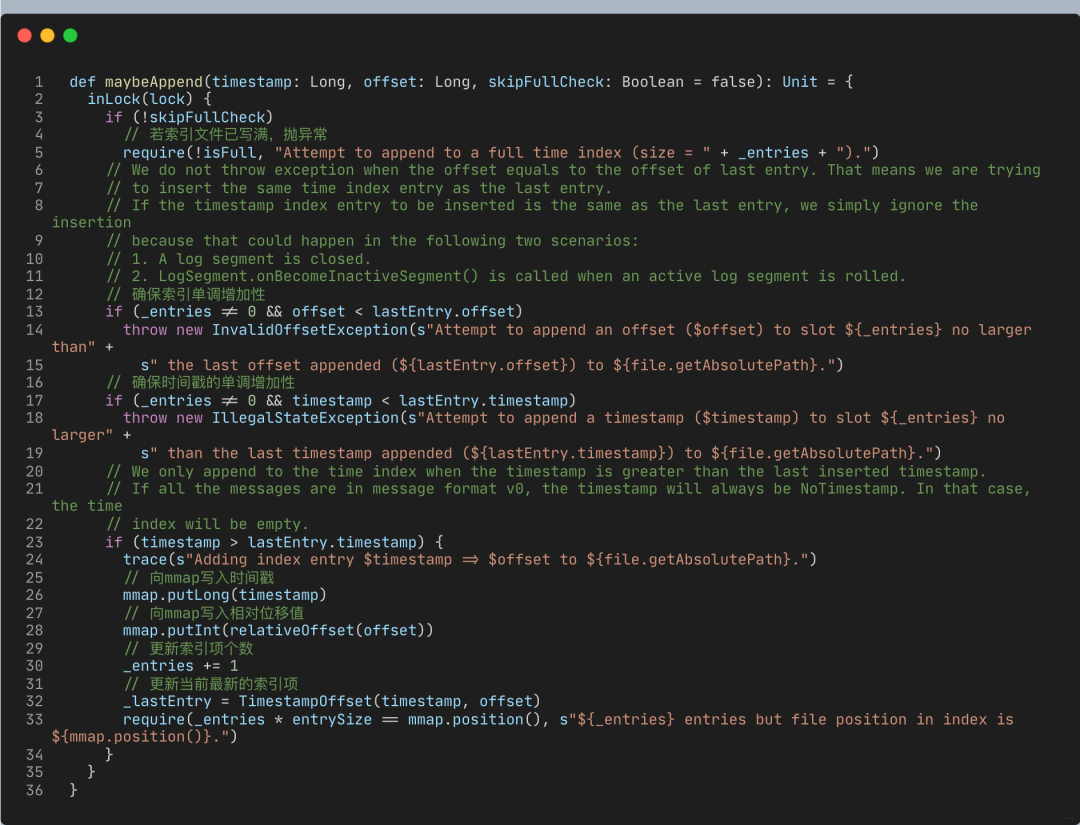
向TimeIndex写索引的主体逻辑,是向mmap分别写入时间戳和相对偏移值。
除校验偏移值的单调增加性之外,TimeIndex还会确保顺序写入的时间戳也单调增加。

不单调增加会咋样?

向TimeIndex索引文件中写入一个过期时间戳和位移,就会导致消费端程序混乱。因为,当消费者端程序根据时间戳信息去过滤待读取消息时,它读到了这个过期时间戳并拿到错误位移值,于是返回错误数据。
3 总结及 FAQ
虽然OffsetIndex和TimeIndex是不同类型索引,但Kafka内部把二者结合使用。通常先使用TimeIndex寻找满足时间戳要求的消息位移值,然后再利用OffsetIndex定位该位移值所在的物理文件位置。因此,它们其实是协作关系。
二者的 broker 端参数都是log.index.size.max.bytes
为什么要一起使用,消费者不是根据Offset找到对于位置值开始消费就好吗?而且结合使用性能也应该降低?
没错。不过一般情况下消费者并不是直接能够定位目标offset,相反地它是通过时间戳先找到目标offset。
不要对索引文件做任何修改!擅自重命名索引文件可能导致Broker崩溃无法启动的场景。虽然Kafka能重建索引,但随意删除索引文件真的很危险!
建立分区初始化的时候,log-segment的位移索引和时间索引文件将近有10M的数据?
里面为空,只是预分配了10MB的空间
kafka记录消费者的消费offset是对消费者组,还是对单个消费者?比如一个消费者组中新加入一个消费者,分区重新分配,那新加入的消费者是从哪里开始消费?
针对消费者组,或者说针对每个group id。保存的是
Kafka没有提供延时消息机制,只能自己实现的哈。
往期推荐

目前交流群已有 800+人,旨在促进技术交流,可关注公众号添加笔者微信邀请进群
喜欢文章,点个“在看、点赞、分享”素质三连支持一下~