
详解DPU三大应用场景及架构(上)


DPU数据平面需要一种大规模敏捷异构的计算架构。这一部分的实现也处在“百家争鸣”的阶段,各家的实现方式差别较大,有基于通用处理器核的方式,有基于可编程门阵列FPGA的方式,也有基于异构众核的方式,还有待探索。
下载地址:
网络功能卸载是伴随云计算网络而产生的,主要是对云计算主机上的虚拟交换机的能力做硬件卸载,从而减少主机上消耗在网络上的CPU算力,提高可售卖计算资源。
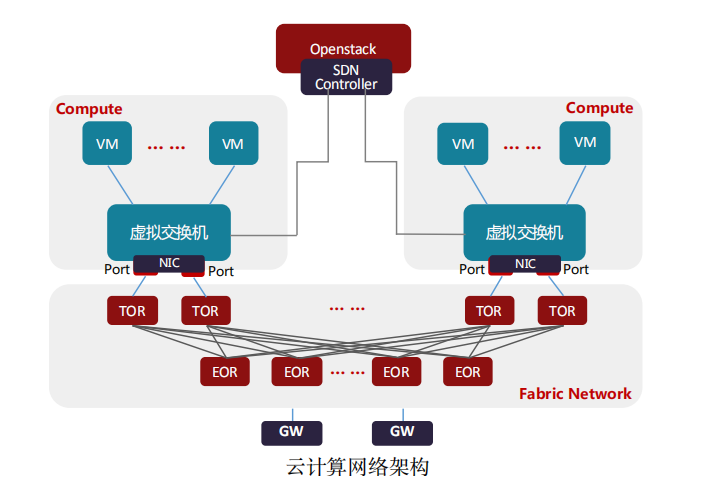
目前除了公有云大厂采用自研云平台,绝大部分私有云厂商都使用开源的OpenStack云平台生态。在OpenStack云平台中,虚拟交换机通常是Open vSwitch,承担着云计算中网络虚拟化的主要工作,负责虚拟机(VM)与同主机 上虚拟机(VM)、虚拟机(VM)与其它主机上虚拟机(VM)、虚拟机(VM)与外部的网络通信。虚拟交换机与网关路由器(GW)通常由同一SDN控制器来管理控制,为租户开通VPC网络以及和外部通信的网络。
主机与主机 间的网络通常是Underlay网络,是由TOR/EOR构建的Spine-Leaf结构的Fabric Network。虚拟机(VM)与虚拟机(VM)通信的网络是Overlay网络,是承载在Underlay网络构建的VxLAN,NVGRE或Geneve隧道之上的。通常VxLAN,NVGRE或Geneve的隧道端点(VTEP)在虚拟交换机和网关路由器(GW) 上。也有部分对网络性能要求比较高的场景,采用SR-IOV替代虚拟交换机,VF直通到虚拟机(VM)内部,这样就要求隧道端点(VTEP)部署在TOR上,TOR与网关路由器(GW)创建隧道,提供Overlay网络服务。虚拟交换机的场景是最通用的应用场景,所以,虚拟交换机的技术迭代也直接影响着虚拟化网络的发展。
行业内主流的Hypervisor主要有Linux系统下的KVM-Qemu,VMWare的ESXi,微软Azure的Hyper-V,以及亚马逊早期用的Xen(现在亚马逊已经转向 KVM-Qemu)。KVM-Qemu有着以Redhat为首在持续推动的更好的开源生态,目前行业内90%以上的云厂商都在用KVM-Qemu作为虚拟化的基础平台。
在KVM-Qemu这个Hypervisor的开源生态里,与网络关系最紧密的标准协议包括virtio和vhost,以及vhost衍生出来的vhost-vdpa。Virtio在KVM-Qemu中定义了一组虚拟化I/O设备,和对应设备的共享内存的通信方法,配合后端协议vhost和vhost-vdpa使用,使虚拟化I/O性能得到提升。
在虚拟化网络的初期,以打通虚拟机(VM)间和与外部通信能力为主,对功能诉求远高于性能,虚拟交换机OVS(Open vSwitch)的最初版本也是基于操作系统Linux内核转发来实现的。
随着虚拟化网络的发展,虚拟机(VM)业务对网络带宽的要求越来越高,另外,英特尔和Linux基金会推出了DPDK(Data Plane Development Kit)开源项 目,实现了用户空间直接从网卡收发数据报文并进行多核快速处理的开发库,虚拟交换机OVS将数据转发平面通过DPDK支持了用户空间的数据转发,进而实现了转发带宽量级的提升。
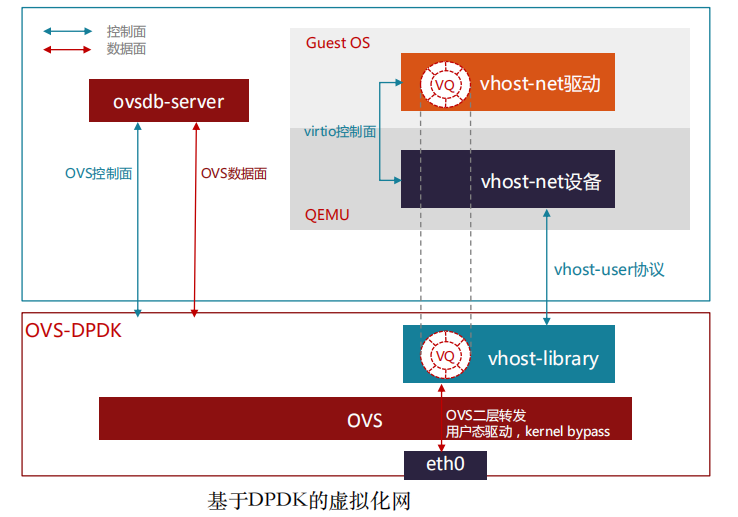
在一些对网络有高性能需求的场景,如NFV业务部署,OVS-DPDK的数据转 发 方 式 , 无 法 满 足 高性能网络的 需 求 , 这 样 就 引 入 的 SR-IOV 透 传(passthrough)到虚拟机(VM)的部署场景。
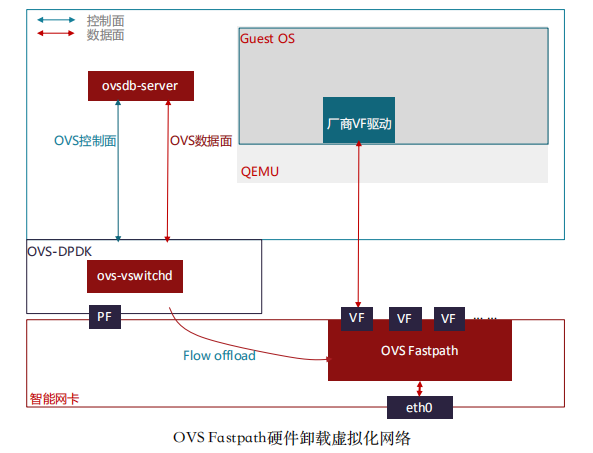
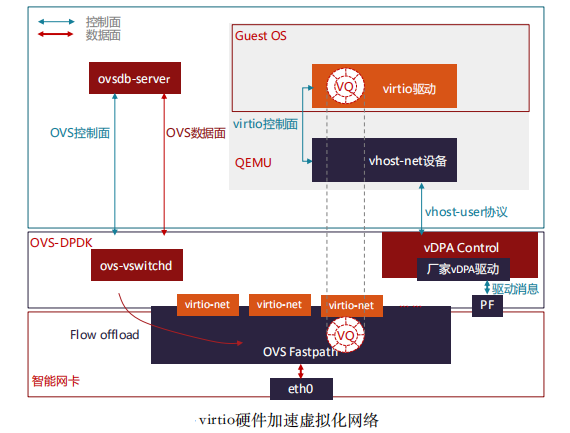
为了解决高性能SRIOV网络的热迁移问题,出现了很多做法和尝试,尚未形成统一的标准。在Redhat提出硬件vDPA架构之前,Mellanox实现了软件vDPA(即VF Relay)。
云原生,从广义上来说,是更好的构建云平台与云应用的一整套新型的设计理念与方法论,而狭义上讲则是以docker容器和Kubernetes(K8S)为支撑的云原生计算基金会(CNCF)技术生态堆栈的新式IT架构。对比虚拟机,容器应用对磁盘的占用空间更小,启动速度更快,直接运行在宿主机内核上,因而无Hypervisor开销,并发支持上百个容器同时在线,接近宿主机上本地进程的性能,资源利用率也更高。以K8S为代表的云原生容器编排系统,提供了统一调度 与弹性扩展的能力,以及标准化组件与服务,支持快速开发与部署。
容器平台包括容器引擎Runtime(如containerd,cri-o等),容器网络接口(CNI,如calico,flannel,contiv,cilium等)和容器存储接口(CSI,如EBS CSI,ceph-csi等)。
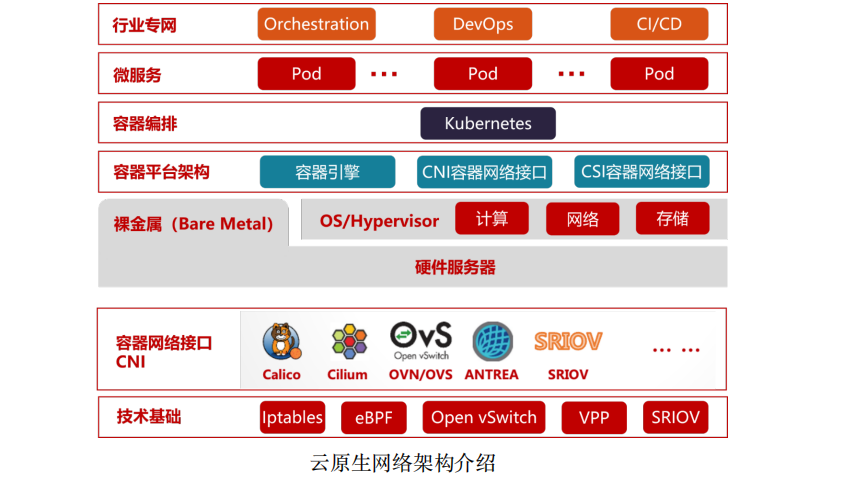
云原生对于网络的需求,既有基础的二三层网络联通,也有四至七层的高级网络功能。二三层的网络主要是实现K8S中的CNI接口,具体如calico,flannel,weave,contiv,cilium等。主要是支持大规模实例,快速弹性伸缩,自 愈合,多集群多活等。四至七层网络功能,主要是服务网格(Service Mesh)。
(2)eBPF的硬件加速
eBPF是一项革命性的技术,可以在Linux内核中运行沙盒程序,而无需重新 编译内核或者加载内核模块。在过去几年,eBPF已经成为解决以前依赖于内核更改或者内核模块的问题的标准方法。对比在Kubernetes上Iptables的转发路径, 使用eBPF会简化其中大部分转发步骤,提高内核的数据转发性能。Cilium是一个基于eBPF实现的开源项目,提供和保护使用Linux容器管理平台部署的应用程序服务之间的网络和API连接,以解决容器工作负载的新可伸缩性,安全性和可见性要求。
RDMA网络功能
(1)RDMA网络功能介绍
面对高性能计算、大数据分析和浪涌型IO高并发、低时延应用,现有TCP/IP软硬件架构和应用高CPU消耗的技术特征根本不能满足应用的需求。这主要体现在处理时延过大——数十微秒,多次内存拷贝、中断处理,上下文切换,复杂的TCP/IP协议处理,以及存储转发模式和丢包导致额外的时延。而RDMA通过网络在两个端点的应用软件之间实现Buffer的直接传递,相比TCP/IP,RDMA无需操作系统和协议栈的介入,能够实现端点间的超低时延、超高吞吐量传输,不需要网络数据的处理和搬移耗费过多的资源,无需OS和CPU的介入。RDMA的本质实际上是一种内存读写技术。
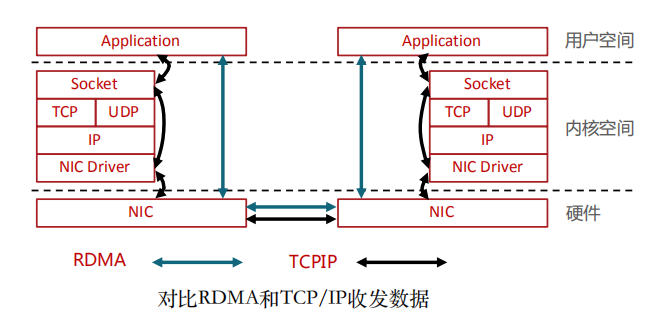
RDMA和TCP/IP网络对比可以看出,RDMA的性能优势主要体现在:
(1)零拷贝——减少数据拷贝次数,由于没有将数据拷贝到内核态并处理数据包头部到过程,传输延迟会显著减少。
(2)Kernel Bypass和协议卸载——不需要内核参与,数据通路中没有繁琐的处理报头逻辑,不仅会使延迟降低,而且也节省了CPU的资源。
(2)RDMA硬件卸载方式
原生RDMA是IBTA(InfiniBand Trade Association)在2000年发布的基于InfiniBand的RDMA规范;基于TCP/IP的RDMA称作iWARP,在2007年形成标准;基于Ethernet的RDMA叫做RoCE,在2010年发布协议,基于增强型以太网并 将传输层换成IB传输层实现;在2014年,IBTA发布了RoCEv2,引入IP解决扩展性问题,可以跨二层组网,引入UDP解决ECMP负载分担等问题。
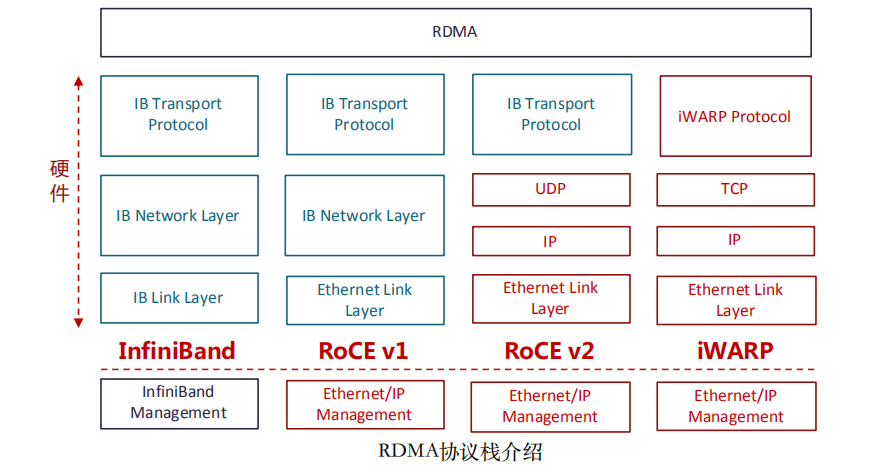
InfiniBand是一种专为RDMA设计的网络,从硬件级别保证可靠传输。全球HPC高算系统TOP500大效能的超级计算机中有相当多套系统在使用InfiniBand Architecture(IBA)。最早做InfiniBand的厂商是IBM和HP,现在主要是NVIDIA的Mellanox。InfiniBand从L2到L4都需要自己的专有硬件,成本非常高。
iWARP直接将RDMA实现在TCP上,优点就是成本最低,只需要采购支出 iWARP的NIC即可以使用RDMA,缺点是性能不好,因为TCP协议栈本身过于重量级,即使按照iWARP厂商的通用做法将TCP卸载到硬件上实现,也很难超越 IB和RoCE的性能。
RoCE(RDMA over Converged Ethernet)是一个允许在以太网上执行RDMA的网络协议。由于底层使用的以太网帧头,所以支持在以太网基础设施上使用 RDMA。不过需要数据中心交换机DCB技术保证无丢包。相比IB交换机时延,交换机时延要稍高一些。由于只能应用于二层网络,不能跨越IP网段使用,市场应用场景相对受限。
RoCEv2协议构筑于UDP/IPv4或UDP/IPv6协议之上。由于基于IP层,所以可以被路由,将RoCE从以太网广播域扩展到IP可路由。由于UDP数据包不具有保序的特征,所以对于同一条数据流,即相同五元组的数据包要求不得改变顺序。另外,RoCEv2还要利用IP ECN等拥塞控制机制,来保障网络传输无损。RoCEv2也是目前主要的RDMA网络技术,以NVIDIA的Mellanox和Intel为代表的厂商,均支持RoCEv2的硬件卸载能力。
下载地址:
本号资料全部上传至知识星球,更多内容请登录智能计算芯知识(知识星球)星球下载全部资料。
免责申明:本号聚焦相关技术分享,内容观点不代表本号立场,可追溯内容均注明来源,发布文章若存在版权等问题,请留言联系删除,谢谢。
电子书<服务器基础知识全解(终极版)>更新完毕,知识点深度讲解,提供182页完整版下载。
获取方式:点击“阅读原文”即可查看PPT可编辑版本和PDF阅读版本详情。
温馨提示:
请搜索“AI_Architect”或“扫码”关注公众号实时掌握深度技术分享,点击“阅读原文”获取更多原创技术干货。
