
从零开始深度学习Pytorch笔记(9)—— 计算图与自动求导(下)
 前文传送门:从零开始深度学习Pytorch笔记(1)——安装Pytorch从零开始深度学习Pytorch笔记(2)——张量的创建(上)从零开始深度学习Pytorch笔记(3)——张量的创建(下)从零开始深度学习Pytorch笔记(4)——张量的拼接与切分从零开始深度学习Pytorch笔记(5)——张量的索引与变换从零开始深度学习Pytorch笔记(6)——张量的数学运算从零开始深度学习Pytorch笔记(7)—— 使用Pytorch实现线性回归从零开始深度学习Pytorch笔记(8)—— 计算图与自动求导(上)
前文传送门:从零开始深度学习Pytorch笔记(1)——安装Pytorch从零开始深度学习Pytorch笔记(2)——张量的创建(上)从零开始深度学习Pytorch笔记(3)——张量的创建(下)从零开始深度学习Pytorch笔记(4)——张量的拼接与切分从零开始深度学习Pytorch笔记(5)——张量的索引与变换从零开始深度学习Pytorch笔记(6)——张量的数学运算从零开始深度学习Pytorch笔记(7)—— 使用Pytorch实现线性回归从零开始深度学习Pytorch笔记(8)—— 计算图与自动求导(上)
在该系列的上一篇,我们介绍了使用Pytorch的重要知识点:计算图和自动求导。
本篇我们继续学习计算图和自动求导。
首先,我们在上一节的计算图上增加复杂度,例如变成这样的计算图:
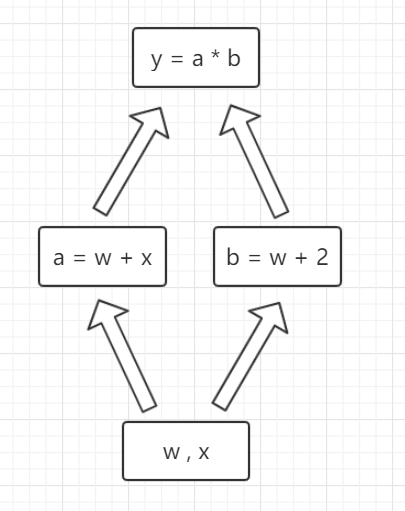
图中为了绘制方便,把张量w和x绘制在一个框中了。
其对应的计算图代码如下:
import torch
w = torch.tensor([1.],requires_grad=True)
x = torch.tensor([2.],requires_grad=True)
a = torch.add(w,x)
b = torch.add(w,2)
y = torch.mul(a,b)
y.backward()#梯度反向传播
print(w.grad)#w的梯度
需要注意的一点是,要使得某个变量支持求导,需要在赋值时使它的元素为浮点数值,如果例如上面代码中的 w 和 x 张量,如果我们定义时赋值的元素不是浮点数而是整数,如下代码:
#不用浮点数
import torch
w = torch.tensor([1],requires_grad=True)
x = torch.tensor([2],requires_grad=True)
a = torch.add(w,x)
b = torch.add(w,2)
y = torch.mul(a,b)
y.backward()#梯度反向传播
print(w.grad)#w的梯度
运行后会发现:

抛出的异常大概意思是:只有元素类型是浮点数的张量才能支持梯度计算。
所以这点大家要注意!
我们接着来聊聊一个新的概念,叫做叶子节点。
在pytorch的tensor类中,有个叫做 is_leaf 的属性,可以称之为叶子节点,如果计算图中某个节点的 is_leaf 属性取值为 True,则为叶子节点。如果取值是False,则不是叶子节点。
一般将用户自己创建的变量叫做叶子节点,而由叶子节点计算得到的变量叫做非叶子节点,调用非叶子节点的backward方法,就会沿着非叶子节点一直回溯到叶子节点结束。
我们还是执行一次反向传播:
import torch
w = torch.tensor([1.],requires_grad=True)
x = torch.tensor([2.],requires_grad=True)
a = torch.add(w,x)
b = torch.add(w,2)
y = torch.mul(a,b)
y.backward()#梯度反向传播
然后查看各个节点是否叶子节点:
#查看叶子节点
print(w.is_leaf,x.is_leaf,a.is_leaf,b.is_leaf,y.is_leaf)
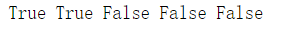
我们发现,其中只有我们赋值的 w 和 x 是叶子节点,而 a、b、y 是由 w 和 x 计算得到的。
我们查看一次 backward 后,每个节点的梯度值:
#查看梯度
print(w.grad,x.grad,a.grad,b.grad,y.grad)#只有叶子结点梯度存在于内存中
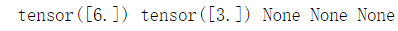
发现只有叶子节点的梯度值不为None,这是因为非叶子节点的梯度值并没有被保存在内存中。
所以叶子节点是该节点是否能保存梯度的前提。
欢迎关注公众号学习之后的深度学习连载部分~
 喜欢记得点在看哦,证明你来看过~
喜欢记得点在看哦,证明你来看过~