
MySQL模糊查询再也用不着 like+% 了!
前言
倒排索引
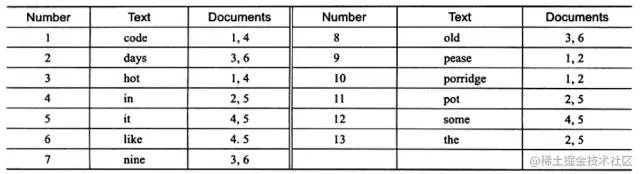

创建全文索引
CREATE TABLE table_name ( id INT UNSIGNED AUTO_INCREMENT NOT NULL PRIMARY KEY, author VARCHAR(200),title VARCHAR(200), content TEXT(500), FULLTEXT full_index_name (col_name) ) ENGINE=InnoDB;
输入查询语句:
SELECT table_id, name, space from INFORMATION_SCHEMA.INNODB_TABLESWHERE name LIKE 'test/%';

2、在已创建的表上创建全文索引语法如下:
CREATE FULLTEXT INDEX full_index_name ON table_name(col_name);使用全文索引
MATCH(col1,col2,...) AGAINST(expr[search_modifier])search_modifier:{IN NATURAL LANGUAGE MODE| IN NATURAL LANGUAGE MODE WITH QUERY EXPANSION| IN BOOLEAN MODE| WITH QUERY EXPANSION}
SELECTcount(*) AS countFROM`fts_articles`WHEREMATCH ( title, body ) AGAINST ( 'MySQL' );
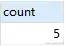
上述语句,查询 title,body 列中包含 'MySQL' 关键字的行数量。上述语句还可以这样写:
SELECTcount(IF(MATCH ( title, body )against ( 'MySQL' ), 1, NULL )) AS countFROM`fts_articles`;
SELECT*,MATCH ( title, body ) against ( 'MySQL' ) AS RelevanceFROMfts_articles;

相关性的计算依据以下四个条件:
SELECT*,MATCH ( title, body ) against ( 'for' ) AS RelevanceFROMfts_articles;

Boolean
select * from fts_test where MATCH(content) AGAINST('+Pease -hot' IN BOOLEAN MODE);Boolean 全文检索支持的类型包括:
+:表示该 word 必须存在
-:表示该 word 必须不存在
(no operator)表示该 word 是可选的,但是如果出现,其相关性会更高
@distance表示查询的多个单词之间的距离是否在 distance 之内,distance 的单位是字节,这种全文检索的查询也称为 Proximity Search,如 MATCH(context) AGAINST('"Pease hot"@30' IN BOOLEAN MODE)语句表示字符串 Pease 和 hot 之间的距离需在30字节内
* :表示以该单词开头的单词,如 lik*,表示可以是 lik,like,likes
" :表示短语
下面是一些demo,看看 Boolean Mode 是如何使用的。
demo1:+ -
SELECT*FROM`fts_articles`WHEREMATCH ( title, body ) AGAINST ( '+MySQL -YourSQL' IN BOOLEAN MODE );
上述语句,查询的是包含 'MySQL' 但不包含 'YourSQL' 的信息
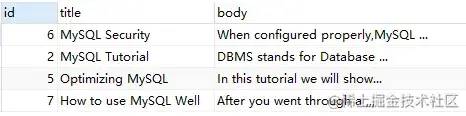
demo2:no operator
SELECT*FROM`fts_articles`WHEREMATCH ( title, body ) AGAINST ( 'MySQL IBM' IN BOOLEAN MODE );
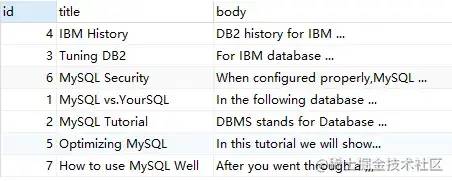
demo3:@
SELECT*FROM`fts_articles`WHEREMATCH ( title, body ) AGAINST ( '"DB2 IBM"@3' IN BOOLEAN MODE );
上述语句,代表 "DB2" ,"IBM"两个词之间的距离在3字节之内
SELECT*FROM`fts_articles`WHEREMATCH ( title, body ) AGAINST ( '+MySQL +(>database <DBMS)' IN BOOLEAN MODE );
上述语句,查询同时包含 'MySQL','database','DBMS' 的行信息,但不包含'DBMS'的行的相关性高于包含'DBMS'的行。

SELECT*FROM`fts_articles`WHEREMATCH ( title, body ) AGAINST ( 'MySQL ~database' IN BOOLEAN MODE );
上述语句,查询包含 'MySQL' 的行,但如果该行同时包含 'database',则降低相关性。

demo6:*
SELECT*FROM`fts_articles`WHEREMATCH ( title, body ) AGAINST ( 'My*' IN BOOLEAN MODE );
上述语句,查询关键字中包含'My'的行信息。
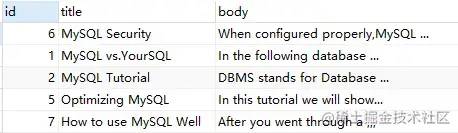
SELECT*FROM`fts_articles`WHEREMATCH ( title, body ) AGAINST ( '"MySQL Security"' IN BOOLEAN MODE );
上述语句,查询包含确切短语 'MySQL Security' 的行信息。

-- 创建索引create FULLTEXT INDEX title_body_index on fts_articles(title,body);
-- 使用 Natural Language 模式查询SELECT*FROM`fts_articles`WHEREMATCH(title,body) AGAINST('database');
使用 Query Expansion 前查询结果如下:
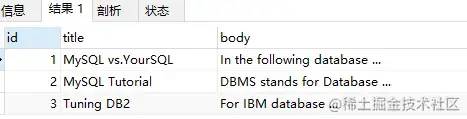
-- 当使用 Query Expansion 模式查询SELECT*FROM`fts_articles`WHEREMATCH(title,body) AGAINST('database' WITH QUERY expansion);

1、直接删除全文索引语法如下:
DROP INDEX full_idx_name ON db_name.table_name;2、使用 alter table 删除全文索引语法如下:
ALTER TABLE db_name.table_name DROP INDEX full_idx_name;