
再见!公司的烂系统~ 网友:好想给大神当小弟...
 正文如下:
正文如下:# 1、为什么要拆分?


# 2、拆前准备什么?
2.1、多维度把握业务复杂度

2.2、定义边界,原则:高内聚,低耦合,单一职责!
2.3、确定拆分后的应用目标
2.4、确定当前要拆分应用的架构状态、代码情况、依赖状况,并推演可能的各种异常。
2.5、给自己留个锦囊,“有备无患”。
2.6、放松心情,缓解压力
# 3、实践
3.1、db拆分实践
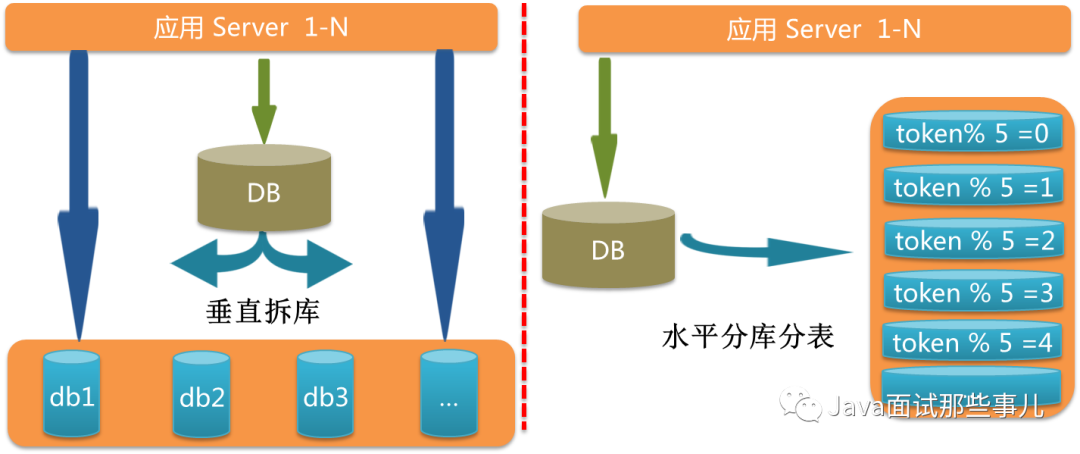
3.1.1、主键id接入全局id发生器

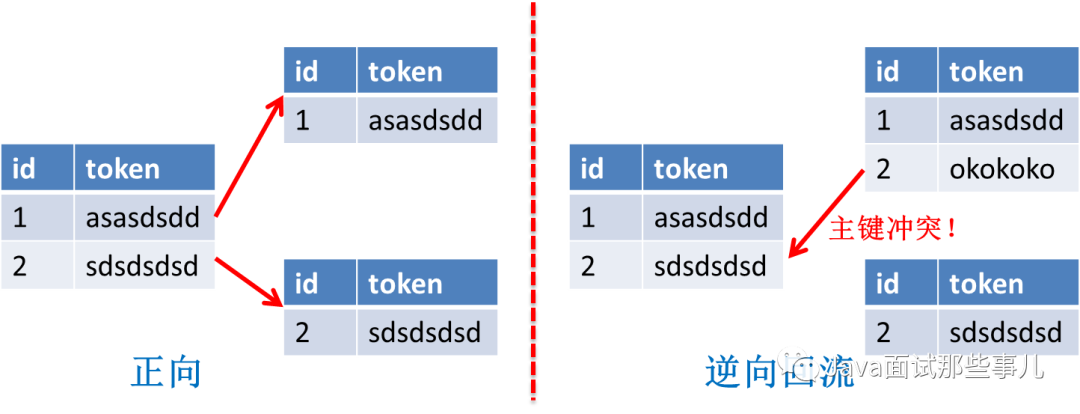
对按主键id排序的sql要提前改造。因为id已经不保证递增,可能会出现乱序场景,这时候可以改造为按gmt_create排序;
报主键冲突问题。这里往往是代码改造不彻底或者改错造成的,比如忘记给某一insert sql的id添加#{},导致继续使用自增,从而造成冲突;

3.1.2、建新表&迁移数据&binlog同步
新表字符集建议是utf8mb4,支持表情符。新表建好后索引不要漏掉,否则可能会导致慢sql!从经验来看索引被漏掉时有发生,建议事先列计划的时候将这些要点记下,后面逐条检查;
增量同步。全量迁移完成后可使用binlog增量同步工具来追数据,比如阿里内部使用精卫,其它企业可能有自己的增量系统,或者使用阿里开源的cannal/otter:https://github.com/alibaba/canal?spm=5176.100239.blogcont11356.10.5eNr98
https://github.com/alibaba/otter/wiki/QuickStart?spm=5176.100239.blogcont11356.21.UYMQ17
增量同步起始获取的binlog位点必须在全量迁移之前,否则会丢数据,比如我中午12点整开始全量同步,13点整全量迁移完毕,那么增量同步的binlog的位点一定要选在12点之前。
3.1.3、联表查询sql改造


3.1.4、切库方案设计与实现(两种方案)
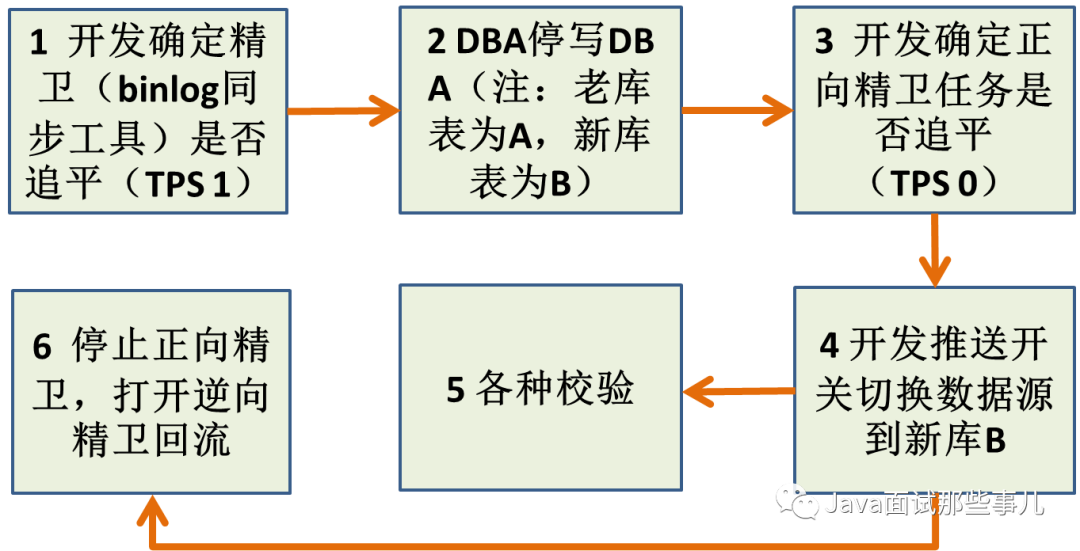
sql联表查询改造不完全;
sql联表查询改错&性能问题;
索引漏加导致性能问题;
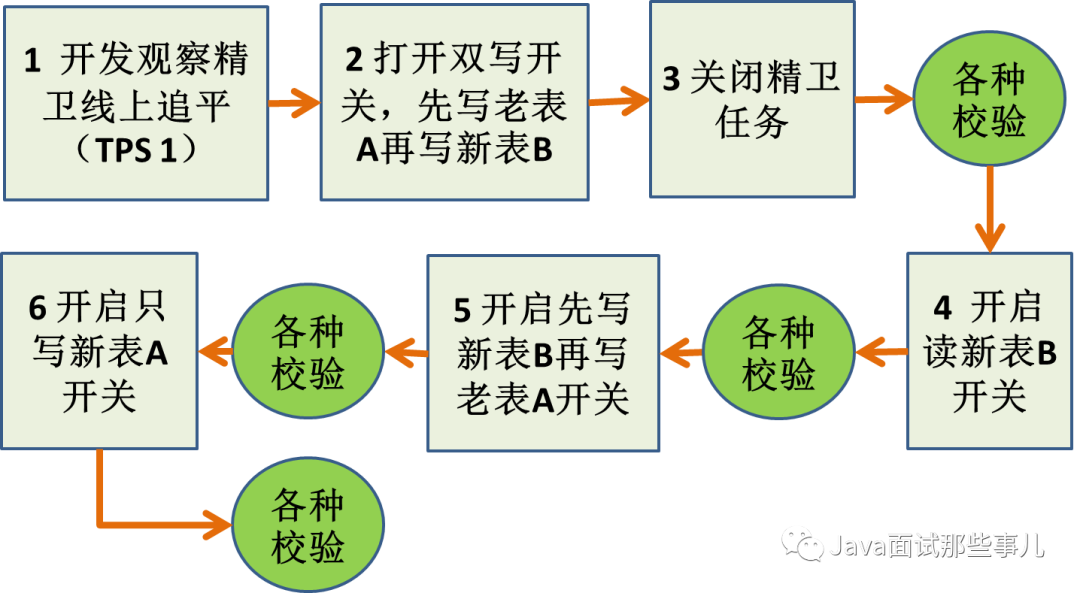
3.1.5、开关要写好
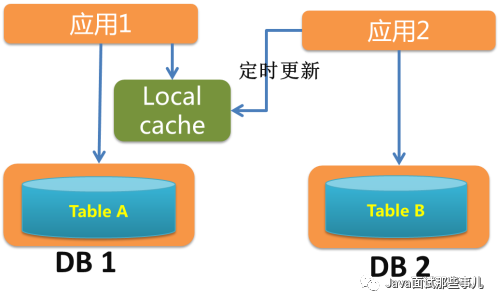
3.2、 拆分后一致性怎么保证?
3.3 应用拆分后稳定性怎么保证?

比如缓存主备、推拉结合、本地缓存……
我们对某一个核心应用的旁支逻辑异步化后,响应时间几乎缩短了1/3,且后面中间件、其它应用等都出现过抖动情况,而核心链路一切正常;
遵循接口最少暴露原则;很多同学搭建完新应用后会随手暴露很多接口,而这些接口由于没人使用而缺乏维护,很容易给以后挖坑。听到过不只一次对话,”你怎么用我这个接口啊,当时随便写的,性能很差的“;
不要让使用方做接口可以做的事情;比如你只暴露一个getMsgById接口,别人如果想批量调用的话,可能就直接for循环rpc调用,如果提供getMsgListByIdList接口就不会出现这种情况了。
避免长时间执行的接口;特别是一些老系统,一个接口背后对应的可能是for循环select DB的场景。
…
按应用优先级进行流控;不仅有总流量限流,还要区分应用,比如核心应用的配额肯定比非核心应用配额高;
业务容量控制。有些时候不仅仅是系统层面的限制,业务层面也需要限制。举个例子,对saas化的一些系统来说,”你这个租户最多1w人使用“。
例:例如我们改造时候发现一年前留下的坑,去掉后整个集群cpu使用率下降1/3
说实话,线上出现问题,如果没有预案,再怎么处理都会超时。曾经遇到过一次DB故障导致脏数据问题,最终只能硬着头皮写代码来清理脏数据,但是时间很长,只能眼睁睁看着故障不断升级。经历过这个事情后,我们马上设想出现脏数据的各种场景,然后上线了三个清理脏数据的job,以防其它不可预知的产生脏数据的故障场景,以后只要遇到出现脏数据的故障,直接触发这三个清理job,先恢复再排查。
应用的cpu、内存、网络、磁盘心中有数
正则匹配耗cpu
耗性能的job优化、降级、下线(循环调用rpc或sql)
慢sql优化、降级、限流
tair/redis、db调用量要可预测
例:tair、db
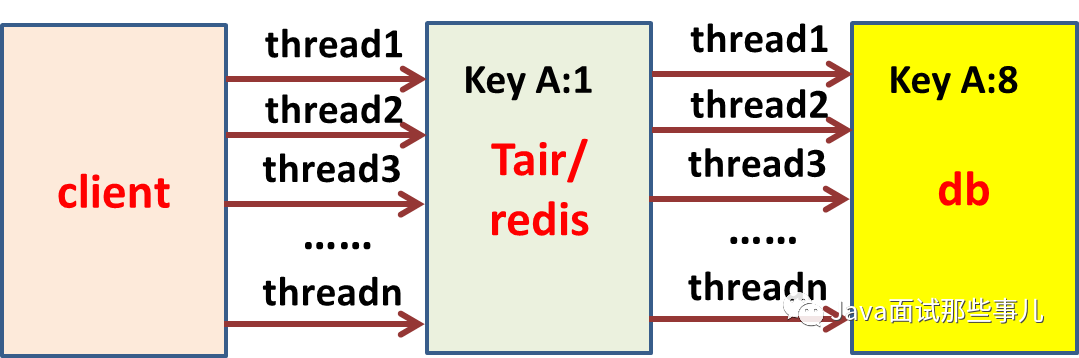
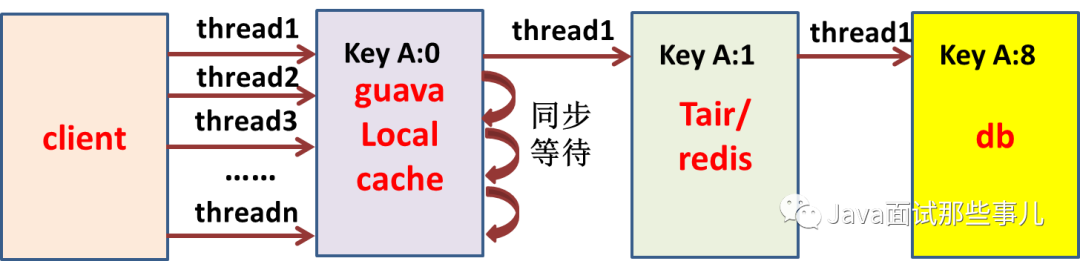
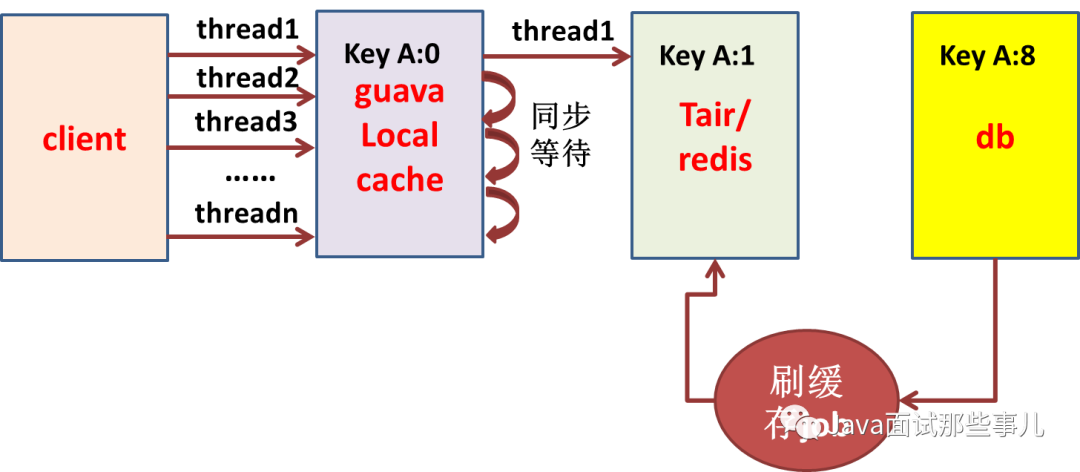
# 4、总结
- EOF -
回复关键字“简明python ”,立即获取入门必备书籍《简明python教程》电子版
回复关键字“爬虫”,立即获取爬虫学习资料
python入门与进阶 每天与你一起成长 推荐阅读