
使用 Go 从零开始实现 CNI 可还行?

对于很多刚入坑云原生技术栈的同学来说,容器网络与 Kubernetes 网络一直很“神秘”,也是很多人容器技术上升曲线的瓶颈,但它也是我们深入走进云原生世界绕不过的话题。要彻底地搞清楚容器网络与 Kubernetes 网络,需要了解很多底层的网络概念,如 OSI 七层模型、Linux 网络栈、虚拟网络设备以及 iptables 等。
早在去年年初,我就对容器网络涉及到的基础概念做了一些列总结,小伙伴们请按需食用:
Linux 数据包的接收与发送过程[1] Linux 虚拟网络设备[2] 从 container 到 pod[3] 容器网络(一)[4] 容器网络(二)[5] 浅聊 Kubernetes 网络模型[6]
但是,这些总结还是停留在理论层面,如果不动手实践一下,这些知识的价值会大打折扣,而且很多技术只有在实际使用的时候我们才会发现理论和实践之间巨大的“鸿沟”。所以我其实也一直想着如何使用熟悉的语言来练手这些网络知识,但是因为事情太多而一拖再拖,直到上周我在查看一个 CNI Bug 的时候又快速过了一下官方 CNI 规范[7],这才有了使用 Go 语言从零开始实现一个 CNI 插件的契机。我的计划是:
简单回顾一下容器网络模型以及解读 Kubernetes 官方出品的 CNI 规范; 使用 Go 语言编写简单的 CNI 插件来实现 Kubernetes overlay 网络,功能包括 pod IP 地址的管理以及容器网络的配置; 编写 CNI 部署工具并在 Kubernetes 集群里面部署和测试我们的 CNI; 讨论潜在的问题以及未来的解决方案;
Kubernetes 网络模型
不管是容器网络还是 Kubernetes 网络都需要解决以下两个核心问题:
容器/Pod IP 地址的管理 容器/Pod 之间的相互通信
容器/Pod IP 地址的管理包括容器 IP 地址的分配与回收,而容器/Pod 之间的相互通信包括同一主机的容器/Pod 之间和跨主机的容器/Pod 之间通信两种场景。这两个问题也不能完全分开来看,因为不同的解决方案往往要同时考虑以上两点。对于同一主机的容器/Pod 之间的通信来说实现相对容易,实际的挑战在于,不同容器/Pod 完全可能分布在不同的集群节点上,如何实现跨主机节点的通信不是一件容易的事情。
如果不采用 SDN(Software define networking) 方式来修改底层网络设备的配置,主流方案是在主机节点的 underlay 网络平面构建新的 overlay 网络负责传输容器/Pod 之间通信数据。这种网络方案在如何复用原有的 underlay 网络平面也有不同的实现方式:
将容器的数据包封装到原主机网络(underlay 网络平面)的三层或四层数据包中,然后使用主机网络的三层或者四层协议传输到目标主机,目标主机拆包后再转发给目标容器; 把容器网络加到主机路由表中,把主机网络(underlay 网络平面)设备当作容器网关,通过路由规则转发到指定的主机,实现容器的三层互通;
为了简单起见,我们主要实现方案 2 所描述的网络模型,容器/Pod 之间通信网络数据包流向大致如下图所示:
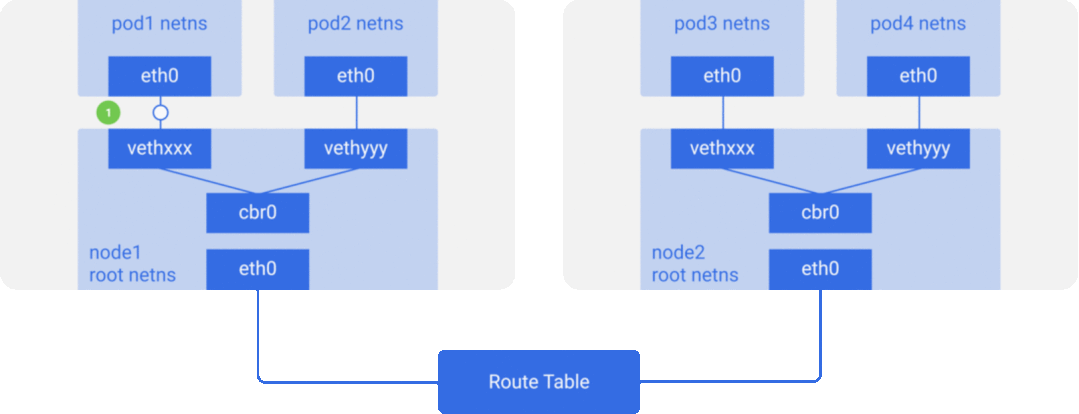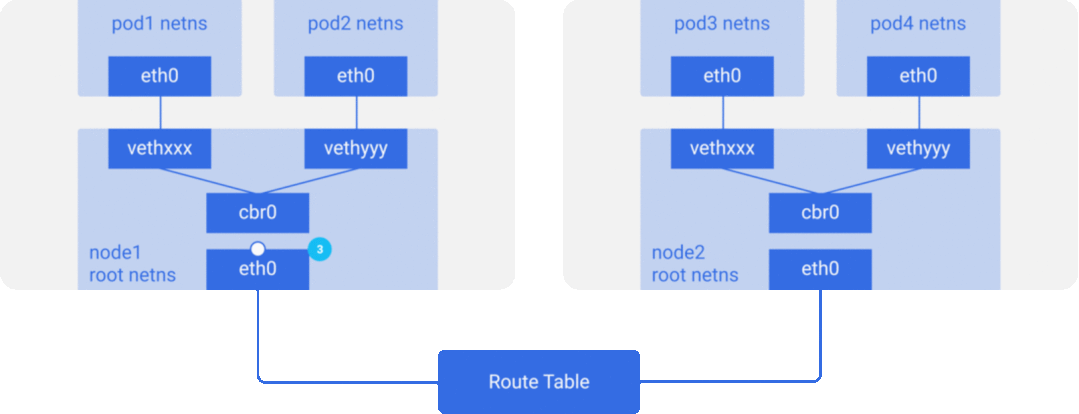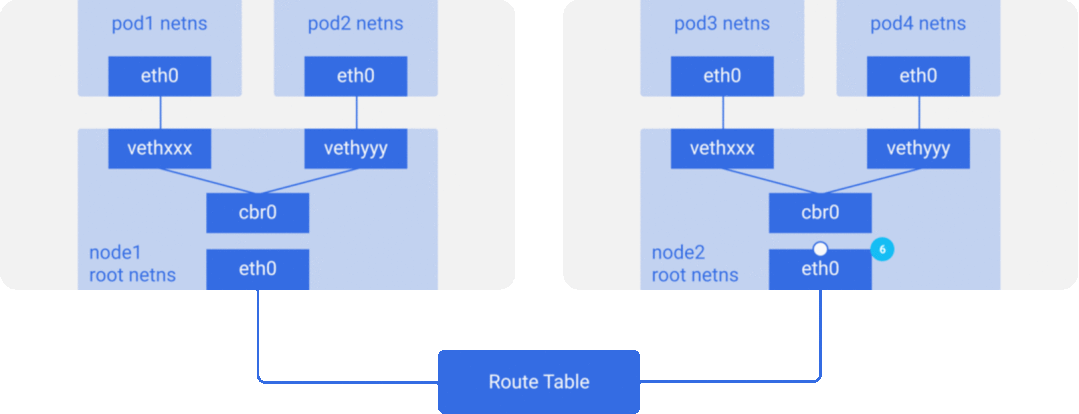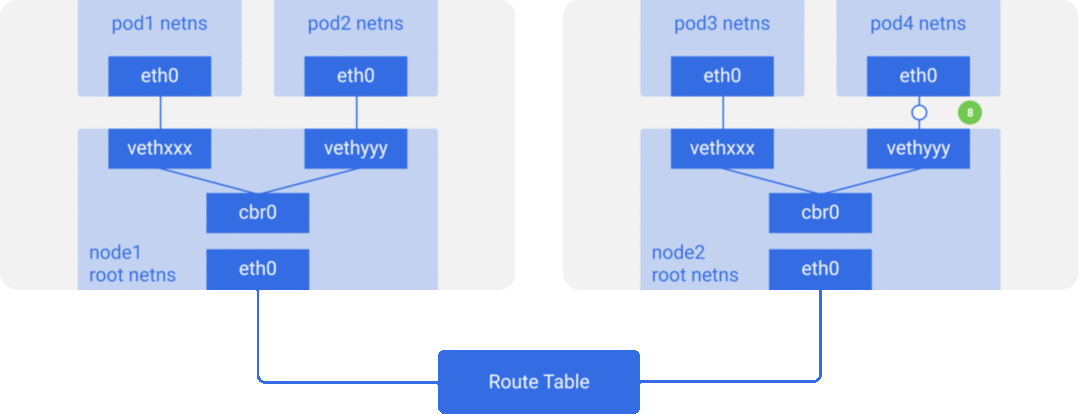
CNI 规范
CNI 规范相对于 CNM(Container Network Model) 对开发者的约束更少、更开放,不依赖于容器运行时,因此也更简单。关于 CNI 规范的详情请查看官方文档[8]。
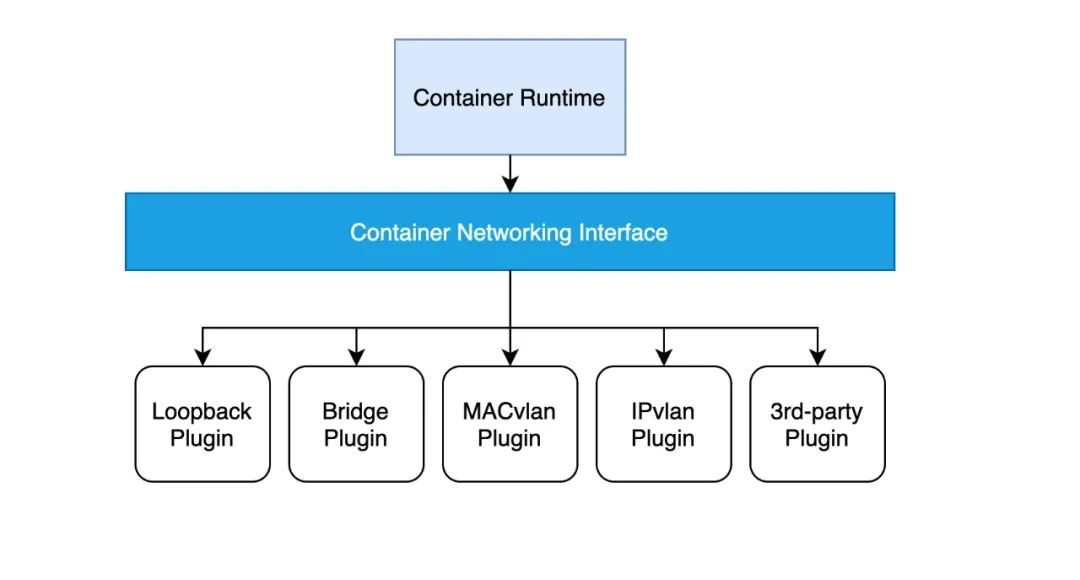
实现一个 CNI 网络插件只需要一个配置文件和一个可执行文件:
配置文件描述插件的版本、名称、描述等基本信息; 可执行文件会被上层的容器管理平台调用,一个 CNI 可执行文件需要实现将容器加入到网络的 ADD 操作以及将容器从网络中删除的 DEL 操作等;
Kubernetes 使用 CNI 网络插件的基本工作流程是:
kubelet 先创建 pause 容器创建对应的网络命名空间; 根据配置调用具体的 CNI 插件,可以配置成 CNI 插件链来进行链式调用; 当 CNI 插件被调用时,它根据环境变量以及命令行参数来获得网络命名空间、容器的网络设备等必要信息,然后执行 ADD 或者其他操作; CNI 插件给 pause 容器配置正确的网络,pod 中其他的容器都是复用 pause 容器的网络;
Note: 如果不清楚什么是 pause 容器,它在 pod 中处于什么样的位置,请查看从 container 到 pod[9]。
kubeadm 搭建 Kubernetes 集群
为了搭建 CNI 的开发测试环境,我们首先需要一个运行着的 Kubernetes 集群。实际上,现在有很多工具可以帮助我们快速创建 Kubernetes 集群,但最简单也是最常用的方式是使用 Kubernetes 官方提供的 kubeadm 快速搭建集群[10]。之所以选择 kubeadm 的另一个原因在于,它允许我们自主选择安装合适的 CNI 组件,因此我们有机会在纯 kubernetes 集群的基础上部署我们开发的 CNI 插件、测试相关的功能是否正常工作。
如果我们按照官方文档安装了相关依赖,在使用 kubeadm 初始化一个集群 master 节点的时候需要通过参数 --pod-network-cidr 指定集群 pod 网络的 CIDR,这是接下来我们编写 CNI 分配 pod IP 地址的重要参数。事实上,kubeadm 在初始化集群的时候通常会指定一个 16 位网络,然后基于此为每个节点单独划分一个独立的 24 位子网,真正的 pod IP 地址都是来源于节点的 24 位子网。由于节点都在不同的子网中,跨节点通信本质为三层通信,我们就可以通过修改节点路由或者构建 IPIP 隧道来复用节点的原有网络。
接下来,我们使用 kubeadm 初始化一个 master 节点:
sudo kubeadm init --pod-network-cidr=172.18.0.0/16
然后再将另外一个 worker 节点加入到集群中:
sudo kubeadm join 10.11.49.33:6443 --token xxxxxxxxxxxxx --discovery-token-ca-cert-hash sha256:xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
接下来在 master 节点配置 kubectl 连接到上面创建的集群:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
现在我们就可以查看集群节点的状态了:
$ kubectl get node
NAME STATUS ROLES AGE VERSION
k8s-master NotReady control-plane,master 3m21s v1.20.2
k8s-worker NotReady <none> 3m21s v1.20.2
从上面命令的输出可以看到所有节点都处于”NotReady“状态,这种情况是正常的,因为我们还没有安装任何 CNI,因此集群节点上的 kubelet 会检测并报告集群节点的状态为”NotReady“。事实上,如果这个时候去部署一个非“hostNetwork”的 pod,就会处于“pending”的状态,因为集群的调度器不能找到“ready”的节点来运行 pod。但是,对于 kubernetes 系统组件,如 apiserver、scheduler、controllermanager 等因为它们是“hostNetwork”的 pod,所以系统 pod 即使在未安装 CNI 组件的情况下也能正常运行。
CNI 配置文件
现在我们来到关键的部分。一般来说,CNI 插件需要在集群的每个节点上运行,在 CNI 的规范里面,实现一个 CNI 插件首先需要一个 JSON 格式的配置文件,配置文件需要放到每个节点的 /etc/cni/net.d/ 目录,一般命名为 <数字>-<CNI-plugin>.conf,而且配置文件至少需要以下几个必须的字段:
cniVersion: CNI 插件的字符串版本号,要求符合 Semantic Version 2.0 规范[11];name: 字符串形式的网络名;type: 字符串表示的 CNI 插件的可运行文件;
除此之外,我们也可以增加一些自定义的配置字段,用于传递参数给 CNI 插件,这些配置会在运行时传递给 CNI 插件。在我们的例子里面,需要配置每个宿主机网桥的设备名、网络设备的最大传输单元(MTU)以及每个节点分配的 24 位子网地址,因此,我们的 CNI 插件的配置看起来会像下面这样:
{
"cniVersion": "0.1.0",
"name": "minicni",
"type": "minicni",
"bridge": "minicni0",
"mtu": 1500,
"subnet": __NODE_SUBNET__
}
Note: 确保配置文件放到
/etc/cni/net.d/目录,kubelet 默认此目录寻找 CNI 插件配置;并且,插件的配置可以分为多个插件链的形式来运行,但是为了简单起见,在我们的例子中,只配置一个独立的 CNI 插件,因为配置文件的后缀名为.conf。
CNI 插件的核心实现
接下来就开始看怎么实现 CNI 插件来管理 pod IP 地址以及配置容器网络设备。在此之前,我们需要明确的是,CNI 介入的时机是 kubelet 创建 pause 容器创建对应的网络命名空间之后,同时当 CNI 插件被调用的时候,kubelet 会将相关操作命令以及参数通过环境变量的形式传递给它。这些环境变量包括:
CNI_COMMAND: CNI 操作命令,包括 ADD, DEL, CHECK 以及 VERSIONCNI_CONTAINERID: 容器 IDCNI_NETNS: pod 网络命名空间CNI_IFNAME: pod 网络设备名称CNI_PATH: CNI 插件可执行文件的搜索路径CNI_ARGS: 可选的其他参数,形式类似于key1=value1,key2=value2...
在运行时,kubelet 通过 CNI 配置文件寻找 CNI 可执行文件,然后基于上述几个环境变量来执行相关的操作。CNI 插件必须支持的操作包括:
ADD: 将 pod 加入到 pod 网络中 DEL: 将 pod 从 pod 网络中删除 CHECK: 检查 pod 网络配置正常 VERSION: 返回可选 CNI 插件的版本信息
让我们直接跳到 CNI 插件的入口函数:
func main() {
cmd, cmdArgs, err := args.GetArgsFromEnv()
if err != nil {
fmt.Fprintf(os.Stderr, "getting cmd arguments with error: %v", err)
}
fh := handler.NewFileHandler(IPStore)
switch cmd {
case "ADD":
err = fh.HandleAdd(cmdArgs)
case "DEL":
err = fh.HandleDel(cmdArgs)
case "CHECK":
err = fh.HandleCheck(cmdArgs)
case "VERSION":
err = fh.HandleVersion(cmdArgs)
default:
err = fmt.Errorf("unknown CNI_COMMAND: %s", cmd)
}
if err != nil {
fmt.Fprintf(os.Stderr, "Failed to handle CNI_COMMAND %q: %v", cmd, err)
os.Exit(1)
}
}
可以看到,我们首先调用 GetArgsFromEnv() 函数将 CNI 插件的操作命令以及相关参数通过环境变量读入,同时从标准输入获取 CNI 插件的 JSON 配置,然后基于不同的 CNI 操作命令执行不同的处理函数。
需要注意的是,我们将处理函数的集合实现为一个接口[12],这样就可以很容易的扩展不同的接口实现。在最基础的版本实现中,我们基本文件存储分配的 IP 信息。但是,这种实现方式存在很多问题,例如,文件存储不可靠,读写可能会发生冲突等,在后续的版本中,我们会实现基于 kubernetes 存储的接口实现,将子网信息以及 IP 信息存储到 apiserver 中,从而实现可靠存储。
接下来,我们就看看基于文件的接口实现是怎么处理这些 CNI 操作命令的。
对于 ADD 命令:
从标准输入获取 CNI 插件的配置信息,最重要的是当前宿主机网桥的设备名、网络设备的最大传输单元(MTU)以及当前节点分配的 24 位子网地址; 然后从环境变量中找到对应的 CNI 操作参数,包括 pod 容器网络命名空间以及 pod 网络设备名等; 接下来创建或者更新节点宿主机网桥,从当前节点分配的 24 位子网地址中抽取子网的网关地址,准备分配给节点宿主机网桥; 接着将从文件读取已经分配的 IP 地址列表,遍历 24 位子网地址并从中取出第一个没有被分配的 IP 地址信息,准备分配给 pod 网络设备;pod 网络设备是 veth 设备对,一端在 pod 网络命名空间中,另外一端连接着宿主机上的网桥设备,同时所有的 pod 网络设备将宿主机上的网桥设备当作默认网关; 最终成功后需要将新的 pod IP 写入到文件中。
看起来很简单对吧?其实作为最简单的方式,这种方案可以实现最基础的 ADD 功能:
func (fh *FileHandler) HandleAdd(cmdArgs *args.CmdArgs) error {
cniConfig := args.CNIConfiguration{}
if err := json.Unmarshal(cmdArgs.StdinData, &cniConfig); err != nil {
return err
}
allIPs, err := nettool.GetAllIPs(cniConfig.Subnet)
if err != nil {
return err
}
gwIP := allIPs[0]
// open or create the file that stores all the reserved IPs
f, err := os.OpenFile(fh.IPStore, os.O_RDWR|os.O_CREATE, 0600)
if err != nil {
return fmt.Errorf("failed to open file that stores reserved IPs %v", err)
}
defer f.Close()
// get all the reserved IPs from file
content, err := ioutil.ReadAll(f)
if err != nil {
return err
}
reservedIPs := strings.Split(strings.TrimSpace(string(content)), "\n")
podIP := ""
for _, ip := range allIPs[1:] {
reserved := false
for _, rip := range reservedIPs {
if ip == rip {
reserved = true
break
}
}
if !reserved {
podIP = ip
reservedIPs = append(reservedIPs, podIP)
break
}
}
if podIP == "" {
return fmt.Errorf("no IP available")
}
// Create or update bridge
brName := cniConfig.Bridge
if brName != "" {
// fall back to default bridge name: minicni0
brName = "minicni0"
}
mtu := cniConfig.MTU
if mtu == 0 {
// fall back to default MTU: 1500
mtu = 1500
}
br, err := nettool.CreateOrUpdateBridge(brName, gwIP, mtu)
if err != nil {
return err
}
netns, err := ns.GetNS(cmdArgs.Netns)
if err != nil {
return err
}
if err := nettool.SetupVeth(netns, br, cmdArgs.IfName, podIP, gwIP, mtu); err != nil {
return err
}
// write reserved IPs back into file
if err := ioutil.WriteFile(fh.IPStore, []byte(strings.Join(reservedIPs, "\n")), 0600); err != nil {
return fmt.Errorf("failed to write reserved IPs into file: %v", err)
}
return nil
一个关键的问题是如何选择合适的 Go 语言库函数来操作 Linux 网络设备,如创建网桥设备、网络命名空间以及连接 veth 设备对。在我们的例子中,选择了比较成熟的 netlink[13],实际上,所有基于 iproute2 工具包的命令在 netlink 库中都有对应的 API,例如 ip link add 可以通过调用 AddLink() 函数来实现。
还有一个问题需要格外小心,那就是处理网络命名空间切换、Go 协程与线程调度问题。在 Linux 中,不同的操作系统线程可能会设置不同的网络命名空间,而 Go 语言的协程会基于操作系统线程的负载以及其他信息动态地在不同的操作系统线程之间切换,这样可能会导致 Go 协程在意想不到的情况下切换到不同的网络命名空间中。
比较稳妥的做法是,利用 Go 语言提供的 runtime.LockOSThread() 函数保证特定的 Go 协程绑定到当前的操作系统线程中。
对于 ADD 操作的返回,确保操作成功之后向标准输出中写入 ADD 操作的返回信息:
addCmdResult := &AddCmdResult{
CniVersion: cniConfig.CniVersion,
IPs: &nettool.AllocatedIP{
Version: "IPv4",
Address: podIP,
Gateway: gwIP,
},
}
addCmdResultBytes, err := json.Marshal(addCmdResult)
if err != nil {
return err
}
// kubelet expects json format from stdout if success
fmt.Print(string(addCmdResultBytes))
return nil
其他三个 CNI 操作命令的处理就更简单了。DEL 操作只需要回收分配的 IP 地址,从文件中删除对应的条目,我们不需要处理 pod 网络设备的删除,原因是 kubelet 在删除 pod 网络命名空间之后这些 pod 网络设备也会自动被删除;CHECK 命令检查之前创建的网络设备与配置,暂时是可选的;VERSION 命令以 JSON 形式输出 CNI 版本信息到标准输出。
func (fh *FileHandler) HandleDel(cmdArgs *args.CmdArgs) error {
netns, err := ns.GetNS(cmdArgs.Netns)
if err != nil {
return err
}
ip, err := nettool.GetVethIPInNS(netns, cmdArgs.IfName)
if err != nil {
return err
}
// open or create the file that stores all the reserved IPs
f, err := os.OpenFile(fh.IPStore, os.O_RDWR|os.O_CREATE, 0600)
if err != nil {
return fmt.Errorf("failed to open file that stores reserved IPs %v", err)
}
defer f.Close()
// get all the reserved IPs from file
content, err := ioutil.ReadAll(f)
if err != nil {
return err
}
reservedIPs := strings.Split(strings.TrimSpace(string(content)), "\n")
for i, rip := range reservedIPs {
if rip == ip {
reservedIPs = append(reservedIPs[:i], reservedIPs[i+1:]...)
break
}
}
// write reserved IPs back into file
if err := ioutil.WriteFile(fh.IPStore, []byte(strings.Join(reservedIPs, "\n")), 0600); err != nil {
return fmt.Errorf("failed to write reserved IPs into file: %v", err)
}
return nil
}
func (fh *FileHandler) HandleCheck(cmdArgs *args.CmdArgs) error {
// to br implemented
return nil
}
func (fh *FileHandler) HandleVersion(cmdArgs *args.CmdArgs) error {
versionInfo, err := json.Marshal(fh.VersionInfo)
if err != nil {
return err
}
fmt.Print(string(versionInfo))
return nil
}
CNI 安装工具
CNI 插件需要运行在集群中的每个节点上,而且 CNI 插件配置信息与可运行文件必须在每个节点特殊的目录中,因此,安装 CNI 插件非常适合使用 DaemonSet 并挂载 CNI 插件目录,为了避免安装 CNI 的工具不能被正常调度,我们需要使用 hostNetwork 来使用宿主机的网络。同时,将 CNI 插件配置以 ConfigMap 的形式挂载,这样方便终端用户配置 CNI 插件。更详细的信息请查看安装工具部署文件[14]。
另外需要注意的是,我们在安装 CNI 插件的脚本中获取每个节点划分得到的 24 子网信息、检查是否合法然后写入到 CNI 配置信息中:
##########################################################################################
# Generate the CNI configuration and move to CNI configuration directory
##########################################################################################
# The environment variables used to connect to the kube-apiserver
SERVICE_ACCOUNT_PATH=/var/run/secrets/kubernetes.io/serviceaccount
SERVICEACCOUNT_TOKEN=$(cat $SERVICE_ACCOUNT_PATH/token)
KUBE_CACERT=${KUBE_CACERT:-$SERVICE_ACCOUNT_PATH/ca.crt}
KUBERNETES_SERVICE_PROTOCOL=${KUBERNETES_SERVICE_PROTOCOL-https}
# Check if we're running as a k8s pod.
if [ -f "$SERVICE_ACCOUNT_PATH/token" ];
then
# some variables should be automatically set inside a pod
if [ -z "${KUBERNETES_SERVICE_HOST}" ]; then
exit_with_message "KUBERNETES_SERVICE_HOST not set"
fi
if [ -z "${KUBERNETES_SERVICE_PORT}" ]; then
exit_with_message "KUBERNETES_SERVICE_PORT not set"
fi
fi
# exit if the NODE_NAME environment variable is not set.
if [[ -z "${NODE_NAME}" ]];
then
exit_with_message "NODE_NAME not set."
fi
NODE_RESOURCE_PATH="${KUBERNETES_SERVICE_PROTOCOL}://${KUBERNETES_SERVICE_HOST}:${KUBERNETES_SERVICE_PORT}/api/v1/nodes/${NODE_NAME}"
NODE_SUBNET=$(curl --cacert "${KUBE_CACERT}" --header "Authorization: Bearer ${SERVICEACCOUNT_TOKEN}" -X GET "${NODE_RESOURCE_PATH}" | jq ".spec.podCIDR")
# Check if the node subnet is valid IPv4 CIDR address
IPV4_CIDR_REGEX="(((25[0-5]|2[0-4][0-9]|1?[0-9][0-9]?)\.){3}(25[0-5]|2[0-4][0-9]|1?[0-9][0-9]?))(\/([8-9]|[1-2][0-9]|3[0-2]))([^0-9.]|$)"
if [[ ${NODE_SUBNET} =~ ${IPV4_CIDR_REGEX} ]]
then
echo "${NODE_SUBNET} is a valid IPv4 CIDR address."
else
exit_with_message "${NODE_SUBNET} is not a valid IPv4 CIDR address!"
fi
# exit if the NODE_NAME environment variable is not set.
if [[ -z "${CNI_NETWORK_CONFIG}" ]];
then
exit_with_message "CNI_NETWORK_CONFIG not set."
fi
TMP_CONF='/minicni.conf.tmp'
cat >"${TMP_CONF}" <<EOF
${CNI_NETWORK_CONFIG}
EOF
# Replace the __NODE_SUBNET__
grep "__NODE_SUBNET__" "${TMP_CONF}" && sed -i s~__NODE_SUBNET__~"${NODE_SUBNET}"~g "${TMP_CONF}"
部署测试 CNI
部署
有了前面小节的部署工具,安装部署 CNI 就非常简单了,只需要在可以连接到集群的机器上运行一下命令:
kubectl apply -f deployments/manifests/minicni.yaml
确保 CNI 部署成功:
# kubectl -n kube-system get pod -l app=minicni
NAME READY STATUS RESTARTS AGE
minicni-node-7dlf6 1/1 Running 0 92s
minicni-node-mkxt6 1/1 Running 0 92s
测试
分别在 master 与 worker 节点部署 netshoot[15] 与 httpbin[16]:
# kubectl apply -f test-pods.yaml
pod/httpbin-master created
pod/netshoot-master created
pod/httpbin-worker created
pod/netshoot-worker created
确保所有 pod 都启动并开始运行:
# kubectl get pod -owide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
httpbin-master 1/1 Running 0 2m3s 172.18.0.3 k8s-master <none> <none>
httpbin-worker 1/1 Running 0 2m3s 172.18.1.3 k8s-worker <none> <none>
netshoot-master 1/1 Running 0 2m3s 172.18.0.2 k8s-master <none> <none>
netshoot-worker 1/1 Running 0 2m3s 172.18.1.2 k8s-worker <none> <none>
之后测试以下四种网络通信是否正常:
pod 到宿主机的通信
# kubectl exec -it netshoot-master -- bash
bash-5.1# ping 10.11.82.197
PING 10.11.82.197 (10.11.82.197) 56(84) bytes of data.
64 bytes from 10.11.82.197: icmp_seq=1 ttl=64 time=0.179 ms
64 bytes from 10.11.82.197: icmp_seq=2 ttl=64 time=0.092 ms
^C
--- 10.11.82.197 ping statistics ---
2 packets transmitted, 2 received, 0% packet loss, time 1019ms
rtt min/avg/max/mdev = 0.092/0.135/0.179/0.043 ms
pod 到其他主机的通信
# kubectl exec -it netshoot-master -- bash
bash-5.1# ping 10.11.82.113
PING 10.11.83.113 (10.11.82.113) 56(84) bytes of data.
64 bytes from 10.11.82.113: icmp_seq=1 ttl=63 time=0.313 ms
64 bytes from 10.11.82.113: icmp_seq=2 ttl=63 time=0.359 ms
^C
--- 10.11.82.113 ping statistics ---
2 packets transmitted, 2 received, 0% packet loss, time 1030ms
rtt min/avg/max/mdev = 0.313/0.336/0.359/0.023 ms
同一个节点 pod-to-pod 通信
# kubectl exec -it netshoot-master -- bash
bash-5.1# ping 172.18.0.3
PING 172.18.0.3 (172.18.0.3) 56(84) bytes of data.
64 bytes from 172.18.0.3: icmp_seq=1 ttl=64 time=0.260 ms
64 bytes from 172.18.0.3: icmp_seq=2 ttl=64 time=0.094 ms
^C
--- 172.18.0.3 ping statistics ---
2 packets transmitted, 2 received, 0% packet loss, time 1018ms
rtt min/avg/max/mdev = 0.094/0.177/0.260/0.083 ms
跨一个节点 pod-to-pod 通信
# kubectl exec -it netshoot-master -- bash
bash-5.1# ping 172.18.1.3
PING 172.18.1.3 (172.18.1.3) 56(84) bytes of data.
64 bytes from 172.18.1.3: icmp_seq=1 ttl=62 time=0.531 ms
64 bytes from 172.18.1.3: icmp_seq=2 ttl=62 time=0.462 ms
^C
--- 172.18.1.3 ping statistics ---
2 packets transmitted, 2 received, 0% packet loss, time 1001ms
rtt min/avg/max/mdev = 0.462/0.496/0.531/0.034 ms
潜在问题与未来展望
默认情况下,同一台主机上的 pod-to-pod 网络包默认会被 Linux 内核丢弃,原因是 Linux 默认会把非 default 网络命名空间的网络包看作是外部数据包,关于这个问题的具体细节,请查看 stackoverflow 上的讨论[17]。目前,我们需要在每个集群结点上使用以下命令手动添加以下 iptables 规则来让 pod-to-pod 网络数据包顺利转发:
iptables -t filter -A FORWARD -s <POD_CIDR> -j ACCEPT
iptables -t filter -A FORWARD -d <POD_CIDR> -j ACCEPT
对于跨节点的 pod-to-pod 网络包,需要像 👉Calico 那样添加宿主机的路由表,保证发往各个节点上的 pod 流量经过节点的转发。目前这些路由表需要手动添加:
ip route add 172.18.1.0/24 via 10.11.82.197 dev ens4 # run on master
ip route add 172.18.0.0/24 via 10.11.82.113 dev ens4 # run on worker
Note: 上面命令中的
172.18.1.0/24是 worker 节点的 24 位子网地址,10.11.82.197是 worker 节点的 IP 地址;与之对应的,172.18.0.0/24是 master 节点的 24 位子网地址,10.11.82.113是 worker 节点的 IP 地址。
另外,之前也提到了,使用文件存储分配 IP 地址信息不可靠,容易产生冲突,比较可靠的做法是使用 kube-apiserver 存储这些信息,并且从 CNI 插件直接连接 kube-apiserver,这样,对于动态扩展集群节点信息、动态增加节点路由也可以很好的处理。
脚注
Linux 数据包的接收与发送过程: /posts/networking-1-pkg-snd-rcv/
[2]Linux 虚拟网络设备: /posts/networking-2-virtual-devices/
[3]从 container 到 pod: /posts/from-container-to-pod/
[4]容器网络(一): /posts/networking-4-docker-sigle-host/
[5]容器网络(二): /posts/networking-5-docker-multi-hosts/
[6]浅聊 Kubernetes 网络模型: /posts/networking-6-k8s-summary/
[7]官方 CNI 规范: https://github.com/containernetworking/cni/blob/master/SPEC.md
[8]官方文档: https://github.com/containernetworking/cni/blob/master/SPEC.md
[9]从 container 到 pod: /posts/from-container-to-pod/
[10]kubeadm 快速搭建集群: https://kubernetes.io/docs/setup/production-environment/tools/kubeadm/create-cluster-kubeadm/
[11]Semantic Version 2.0 规范: https://semver.org/
[12]接口: https://github.com/morvencao/minicni/blob/master/pkg/handler/handler.go
[13]netlink: https://github.com/vishvananda/netlink
[14]安装工具部署文件: https://github.com/morvencao/minicni/blob/master/deployments/manifests/minicni.yaml
[15]netshoot: https://github.com/nicolaka/netshoot
[16]httpbin: https://github.com/postmanlabs/httpbin
[17]stackoverflow 上的讨论: https://serverfault.com/questions/162366/iptables-bridge-and-forward-chain
原文链接:https://morven.life/posts/write_your_own_cni_with_golang/


你可能还喜欢
点击下方图片即可阅读


云原生是一种信仰 🤘
关注公众号
后台回复◉k8s◉获取史上最方便快捷的 Kubernetes 高可用部署工具,只需一条命令,连 ssh 都不需要!


点击 "阅读原文" 获取更好的阅读体验!
发现朋友圈变“安静”了吗?
