
超快变形金刚 | 用Res2Net思想和动态kernel-size再设计 ViT,超越MobileViT


为了追求不断提高的准确性,通常会开发大型的网络模型。此类模型需要大量计算资源,因此无法部署在边缘设备上。由于边缘设备在多个应用领域中都有落地,因此构建资源高效的通用网络具有很大的价值。
在这项工作中有效地结合了
CNN和Transformer模型的优势,并提出一种新的高效混合架构EdgeNeXt。特别是在EdgeNeXt中,引入了Split Depth-wise Transpose Attention(SDTA) 编码器,SDTA将输入张量拆分为多个通道组,并利用深度卷积和跨通道维度的Self-Attention来隐式扩大感受野并编码多尺度特征。在分类、检测和分割任务上的广泛实验揭示了所提出方法的优点,
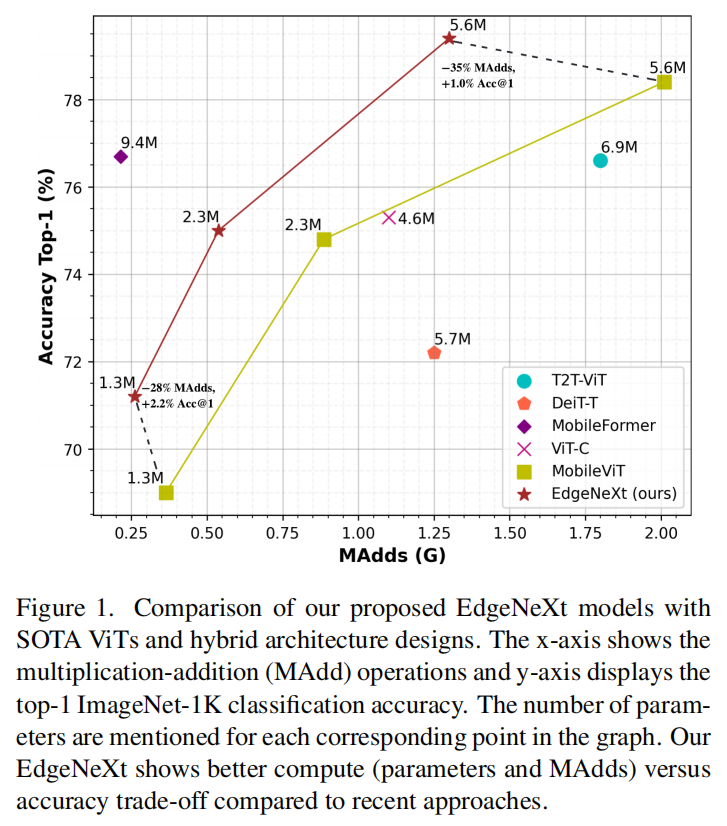
EdgeNeXt在计算要求相对较低的情况下优于最先进的方法。1.3M 参数的EdgeNeXt模型在ImageNet-1K上实现了 71.2% 的 top-1 准确率,以 2.2% 的增益和 28% 的 FLOP 降低超过了MobileViT。此外,5.6M 参数的EdgeNeXt模型在ImageNet-1K上实现了 79.4% 的 top-1 准确率。
1简介
卷积神经网络 (CNN) 和最近推出的vision transformers(ViT) 显著提升了几项主流计算机视觉任务(包括目标识别、检测和分割)的最新技术水平。总的趋势是使网络架构更加深入和复杂,以追求不断提高的准确性。在努力提高准确性的同时,大多数现有的基于 CNN 和 ViT 的架构都忽略了计算效率方面(即模型大小和速度),这对于在移动平台等资源受限设备上运行至关重要。在许多实际应用中,例如机器人和自动驾驶汽车,需要识别过程既准确又在资源受限的移动平台上具有低延迟。
大多数现有方法通常利用精心设计的有效卷积变体来在资源受限的移动平台上实现速度和准确性之间的权衡。除了这些方法之外,很少有现有的工作采用硬件感知神经架构搜索 (NAS) 来为移动设备构建低延迟准确模型。尽管这些轻量级 CNN 易于训练且在编码局部图像细节方面效率很高,但并未明确模拟像素之间的全局交互。
在 ViT 中引入 Self-Attention 使建模这种全局交互成为可能,但是,由于 Self-Attention 计算比较复杂,因此这种全局建模通常以缓慢的推理为代价。这也造成为移动视觉应用设计轻量级 ViT 变体的成为了挑战。
目前大多数现有工作都采用基于 CNN 的设计来开发高效模型。然而,CNN 中的卷积操作继承了2个主要限制:
首先,它仅具有局部感受野,因此无法对全局上下文进行建模;
其次,学习到的权重在推理时是固定的,这使得
CNN无法灵活地适应输入内容。
虽然使用 Transformer 可以缓解这两个问题,但它们通常是计算密集型的。最近很少有工作通过结合 CNN 和 ViT 的优势来研究为移动视觉任务设计轻量级架构。然而,这些方法主要侧重于优化参数并产生更高的MAdds操作,这限制了移动设备上的高速推理。由于注意力块的复杂度相对于输入大小是二次的,因此 MAdds 更高。由于网络架构中有多个注意力块,这变得更加成问题。这里作者认为,在设计有效结合 CNN 和 ViT 互补优势的统一移动架构时,模型大小、参数和 MAdd 都应该相对较小(见图 1)。
2EdgeNeXt
这项工作的主要目标是开发一种轻量级的混合设计,有效地将 ViT 和 CNN 的优点融合到低功耗边缘设备中。ViT(例如 MobileViT)中的计算开销主要是由于 Self-Attention 操作。与 MobileViT 相比, EdgeNeXt 中的注意力块相对于输入空间维度具有线性复杂度,其中 N 是块数,d 是特征/通道维度。EdgeNeXt中的 Self-Attention 操作适用于跨通道维度而不是空间维度。此外,证明了使用更少的注意力块(MobileViT 中的9个,EdgeNeXt中3个),也可以超过MobileViT的性能。通过这种方式,所提出的框架可以用有限数量的 MAdd 对全局表示进行建模,这是确保在边缘设备上进行低延迟推理的基本标准。为了激发提出的EdgeNeXt,作者还提出了2个理想的特性:
特性1:有效地编码全局信息
Self-Attention 学习全局表示的内在特征对于视觉任务至关重要。为了有效地继承这一优势,使用cross-covariance attention将注意力操作合并到特征通道维度上,而不是在相对较少数量的网络块中合并空间维度。这将原始 Self-Attention操作的复杂度从二次降低到线性,并有效地隐式编码全局信息。
特性2:自适应 kernel sizes
众所周知,大kernel sizes卷积的计算成本很高,因为参数和 FLOP 的数量会随着kernel sizes的增长而二次增加。尽管较大的kernel sizes有助于增加感受野,但在整个网络层次结构中使用如此大的kernel sizes是昂贵且次优的。我们提出了一种自适应kernel sizes机制来降低这种复杂性并捕获网络中不同级别的特征。
受 CNN 层次结构的启发,在早期Stage使用较小的kernel sizes,而在卷积编码器块的后期Stage使用较大的kernel sizes。这种设计选择是最佳的,因为 CNN 的早期Stage通常捕获低级特征,较小的kernel sizes适合此目的。然而,在网络的后期Stage,需要大的卷积核来捕获高级特征。
2.1 整体架构
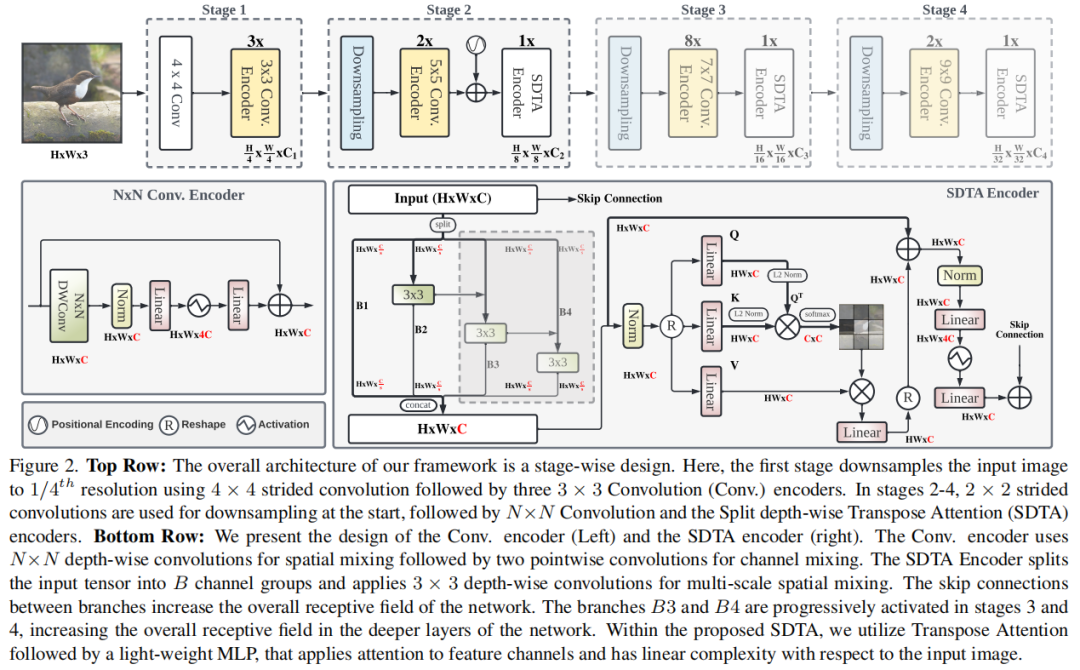
图 2 说明了提议的 EdgeNeXt 架构的概述。主要成分有2个:
自适应 N×N 卷积编码器 SDTA编码器
EdgeNeXt 架构建立在 ConvNeXt 的设计原则之上,并在4个Stage以4个不同的尺度提取分层特征:
第1阶段:尺寸为 H×W×3 的输入图像在网络开始处通过一个 patchify stem 层,使用 4×4 非重叠卷积和层范数实现,这可以得到 H/4×W/4 ×C1 特征图。然后,将输出传递给 3×3 卷积编码器提取局部特征。
第2阶段:从使用 stride=2×2 卷积实现的下采样层开始,该层将空间大小减少一半并增加通道,产生 H/8×W/8×C2 特征图;然后是2个连续的 5×5 卷积编码器。位置编码 (PE) 也仅在第2阶段的 SDTA 块之前添加。作者观察到 PE 对密集预测任务(例如,目标检测和分割)很敏感,并且在所有阶段添加它会增加网络的延迟。因此,只在网络中添加一次以对空间位置信息进行编码。
第3,4阶段:第2阶段输出的特征图进一步传递到第3和第4阶段,分别生成 H/16×W/16×C3 和 H/32×W/32×C4 维特征。
2.2 卷积编码器

该Block由具有自适应kernel sizes的深度可分离卷积组成。可以通过2个单独的层来定义它:
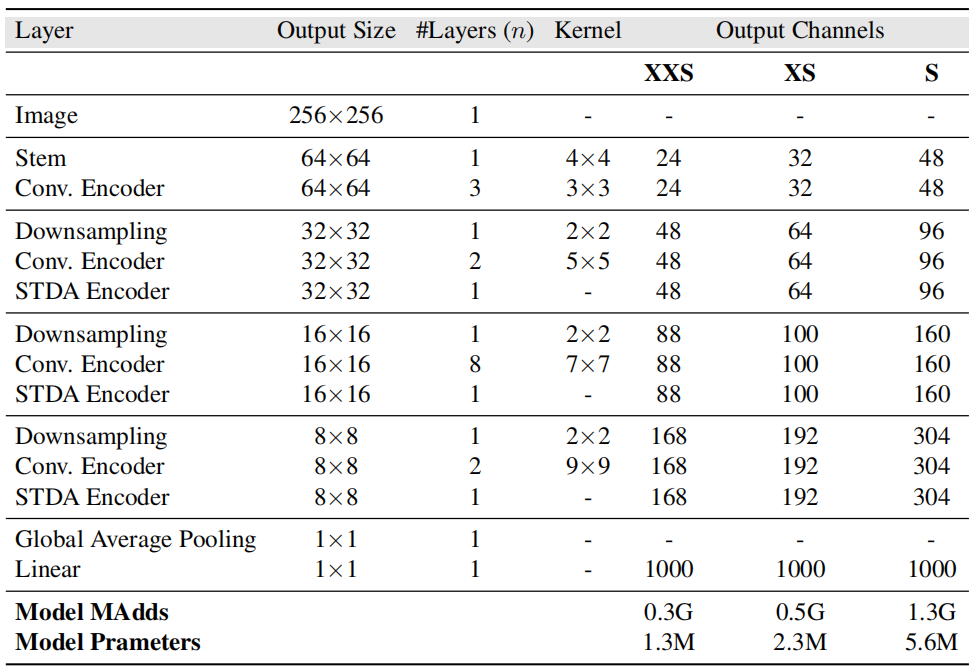
具有自适应 N×N kernel的深度卷积。对于阶段 1、2、3 和 4,分别使用 k = 3、5、7 和 9。
使用2个逐点卷积层来丰富局部表示以及
LN和GELU以进行非线性特征映射。最后,添加一个
Shortcut以使信息在网络层次结构中流动。

这个Block类似于 ConvNeXt Block,但kernel sizes是动态的,并且根据阶段而变化。如上表所示卷积中的自适应kernel sizes与静态kernel sizes相比,编码器性能更好。卷积编码器可以表示如下:

其中 表示形状为 H×W×C 的输入特征图,LinearG 是一个点卷积层,后面是 GELU,Dw 是 k×k深度卷积,LN 是一个归一化层, 表示 卷积编码器的输出特征图。
2.3 SDTA编码器

SDTA 编码器中有2个主要组件:
第一: 通过编码输入图像中的各种空间级别来学习自适应多尺度特征表示 第二: 隐式编码全局图像表示
编码器的第1部分受到 Res2Net 的启发,采用多尺度处理方法,将分层表示开发成单个块。这使得输出特征表示的空间感受野更加灵活和自适应。与 Res2Net 不同, SDTA 编码器中的第1个块不使用 1×1 逐点卷积层来确保具有有限数量的参数和 MAdd 的轻量级网络。此外,使用每个阶段的自适应子集数量来实现有效和灵活的特征编码。在 STDA 编码器中,我们将输入张量 H×W×C 分成 s 个子集,每个子集用 表示,并且与 C/s 个通道具有相同的空间大小,其中 和 C 是通道数。每个特征图子集(第1个子集除外)都传递给 3×3 深度卷积,记为 ,输出记为 。
此外, 的输出,用 表示,被添加到特征子集 中,然后输入到 。子集 s 的数量基于阶段数 t 是自适应的,其中 。可以这样写:

如图 4 中的 SDTA 编码器所示,每个深度操作 接收来自所有先前分割 的特征图输出。
如前所述,Transformer 自注意力层的开销对于边缘设备上的视觉任务是不可行的,因为它是以更高的 MAdd 和延迟为代价的。为了缓解这个问题并有效地编码全局上下文,在 SDTA 编码器中使用转置查询和关键注意力特征图。通过跨通道维度而不是空间维度应用 MSA 的点积运算,该操作具有线性复杂性,这允许计算跨通道的交叉协方差以生成具有关于全局表示的隐式知识的注意力特征图。
给定形状为 H×W×C 的归一化张量 Y,使用3个线性层计算Q、K和V投影,得到 、和 ,尺寸为HW×C,其中、 和分别是Q、K和V 的投影权重。然后,在计算交叉协方差注意力之前,将L2范数应用于Q和K,因为它可以稳定训练。作者这里没有在 和 之间沿空间维度应用点积,即 (HW×C)·(C×HW),而是在和K之间的通道维度上应用点积,即 (C×HW)·(HW×C),产生C×C softmax 缩放的注意力得分矩阵。为了得到最终的注意力图,将分数乘以V并将它们相加。转置的注意力操作可以表示如下:

其中 X 是输入, 是输出特征张量。之后,使用2个 1×1 逐点卷积层、LN 和 GELU 激活来生成非线性特征。
pytorch实现如下“
class XCA(nn.Module):
def __init__(self, dim, num_heads=8, qkv_bias=False, attn_drop=0., proj_drop=0.):
super().__init__()
self.num_heads = num_heads
self.temperature = nn.Parameter(torch.ones(num_heads, 1, 1))
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
def forward(self, x):
B, N, C = x.shape
qkv = self.qkv(x).reshape(B, N, 3, self.num_heads, C // self.num_heads)
qkv = qkv.permute(2, 0, 3, 1, 4)
q, k, v = qkv[0], qkv[1], qkv[2] # make torchscript happy (cannot use tensor as tuple)
q = q.transpose(-2, -1)
k = k.transpose(-2, -1)
v = v.transpose(-2, -1)
q = torch.nn.functional.normalize(q, dim=-1)
k = torch.nn.functional.normalize(k, dim=-1)
attn = (q @ k.transpose(-2, -1)) * self.temperature
# -------------------
attn = attn.softmax(dim=-1)
attn = self.attn_drop(attn)
x = (attn @ v).permute(0, 3, 1, 2).reshape(B, N, C)
# ------------------
x = self.proj(x)
x = self.proj_drop(x)
return x
@torch.jit.ignore
def no_weight_decay(self):
return {'temperature'}
class SDTAEncoder(nn.Module):
def __init__(self, dim, drop_path=0., layer_scale_init_value=1e-6, expan_ratio=4,
use_pos_emb=True, num_heads=8, qkv_bias=True, attn_drop=0., drop=0., scales=1):
super().__init__()
width = max(int(math.ceil(dim / scales)), int(math.floor(dim // scales)))
self.width = width
if scales == 1:
self.nums = 1
else:
self.nums = scales - 1
convs = []
for i in range(self.nums):
convs.append(nn.Conv2d(width, width, kernel_size=3, padding=1, groups=width))
self.convs = nn.ModuleList(convs)
self.pos_embd = None
if use_pos_emb:
self.pos_embd = PositionalEncodingFourier(dim=dim)
self.norm_xca = LayerNorm(dim, eps=1e-6)
self.gamma_xca = nn.Parameter(layer_scale_init_value * torch.ones(dim),
requires_grad=True) if layer_scale_init_value > 0 else None
self.xca = XCA(dim, num_heads=num_heads, qkv_bias=qkv_bias, attn_drop=attn_drop, proj_drop=drop)
self.norm = LayerNorm(dim, eps=1e-6)
self.pwconv1 = nn.Linear(dim, expan_ratio * dim) # pointwise/1x1 convs, implemented with linear layers
self.act = nn.GELU() # TODO: MobileViT is using 'swish'
self.pwconv2 = nn.Linear(expan_ratio * dim, dim)
self.gamma = nn.Parameter(layer_scale_init_value * torch.ones((dim)),
requires_grad=True) if layer_scale_init_value > 0 else None
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
def forward(self, x):
input = x
spx = torch.split(x, self.width, 1)
for i in range(self.nums):
if i == 0:
sp = spx[i]
else:
sp = sp + spx[i]
sp = self.convs[i](sp)
if i == 0:
out = sp
else:
out = torch.cat((out, sp), 1)
x = torch.cat((out, spx[self.nums]), 1)
# XCA
B, C, H, W = x.shape
x = x.reshape(B, C, H * W).permute(0, 2, 1)
if self.pos_embd:
pos_encoding = self.pos_embd(B, H, W).reshape(B, -1, x.shape[1]).permute(0, 2, 1)
x = x + pos_encoding
x = x + self.drop_path(self.gamma_xca * self.xca(self.norm_xca(x)))
x = x.reshape(B, H, W, C)
# Inverted Bottleneck
x = self.norm(x)
x = self.pwconv1(x)
x = self.act(x)
x = self.pwconv2(x)
if self.gamma is not None:
x = self.gamma * x
x = x.permute(0, 3, 1, 2) # (N, H, W, C) -> (N, C, H, W)
x = input + self.drop_path(x)
return x
3实现
3.1 图像分类

3.2 目标检测

3.3 语义分割
3.4 消融实验

4参考阅读
[1].EdgeNeXt: Efficiently Amalgamated CNN-Transformer Architecture for Mobile Vision Applications
5推荐阅读
Shunted Self-Attention | 源于 PvT又高于PvT,解决小目标问题的ViT方法
改进Yolov5 | 用 GSConv+Slim Neck 一步步把 Yolov5 提升到极致!!!
大道至简 | 设计 ViT 到底怎么配置Self-Attention才是最合理的?
长按扫描下方二维码添加小助手。
可以一起讨论遇到的问题
声明:转载请说明出处
扫描下方二维码关注【集智书童】公众号,获取更多实践项目源码和论文解读,非常期待你我的相遇,让我们以梦为马,砥砺前行!
