
知识图谱入门必看!
来源:知乎 作者:gaojing
著作权归属原作者,本文仅作学术分享,侵删
知识图谱
知识图谱介绍

各大公司布局知识图谱
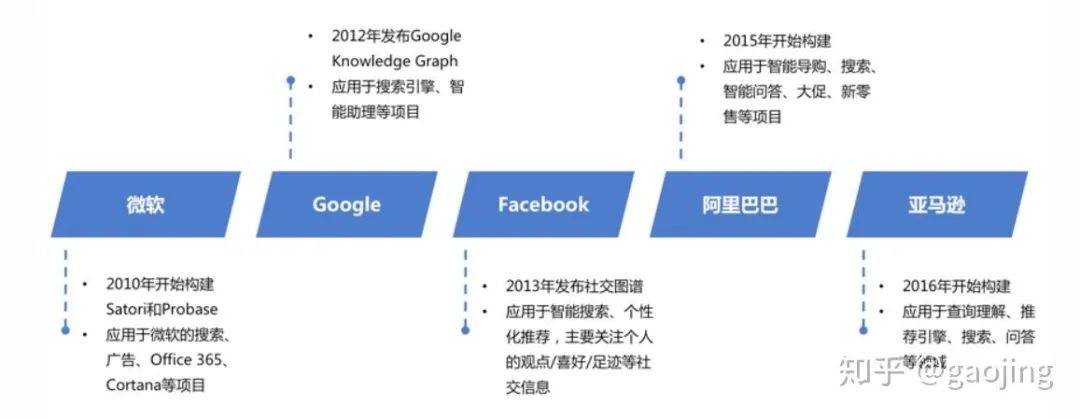
知识图谱应用模式(来之美团的Ai大会报告)

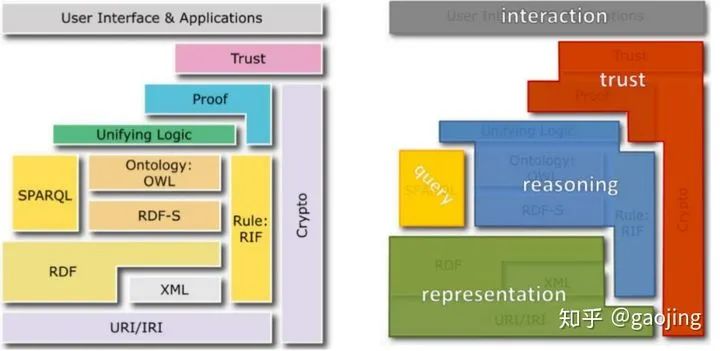
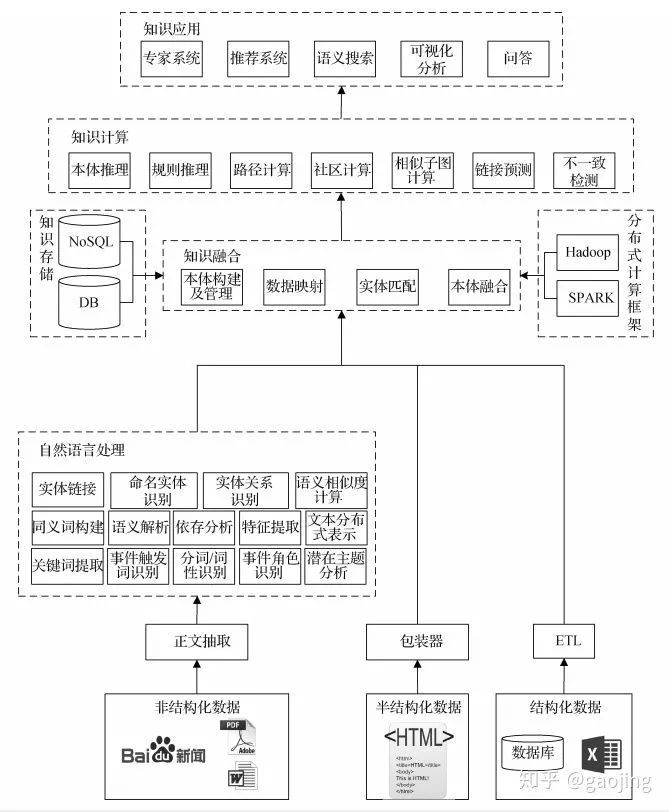
知识图谱技术链
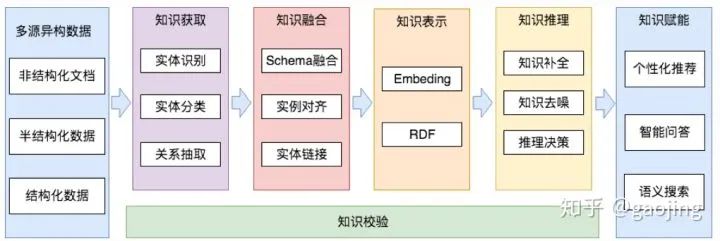
知识图谱赋能


知识图谱技术模块
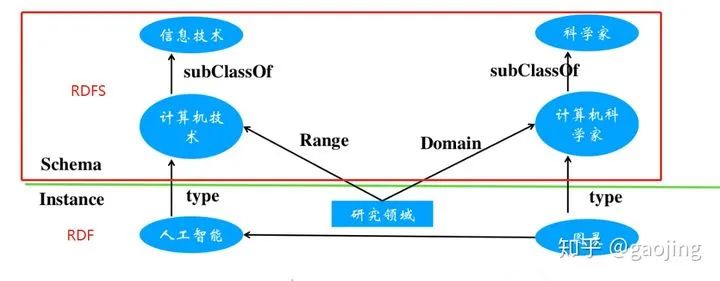
知识表示
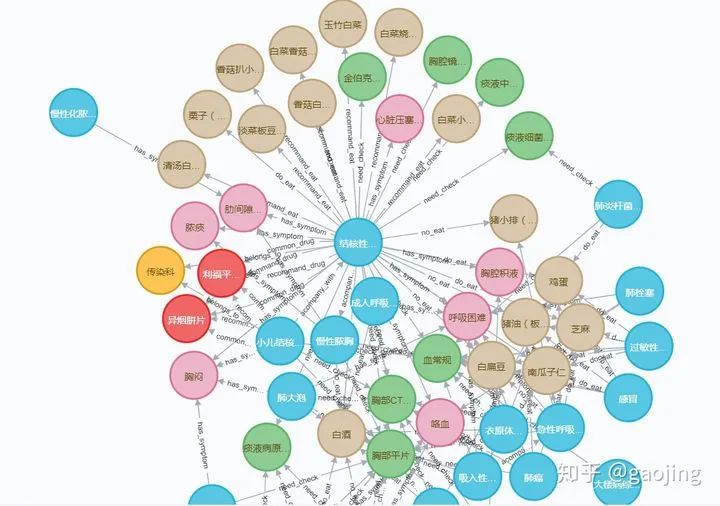
基于连续向量的知识表示

两种方法对比

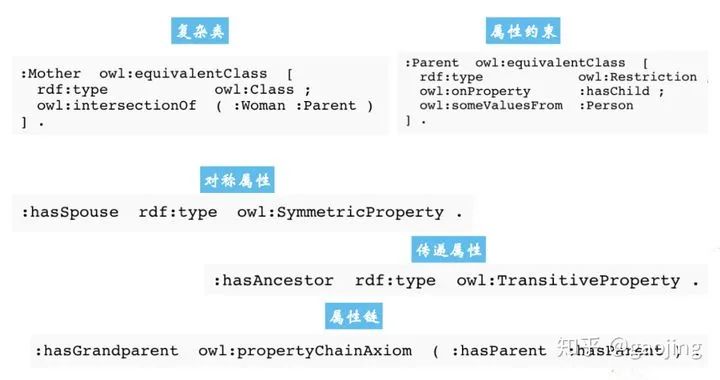
知识抽取

主要处理流程
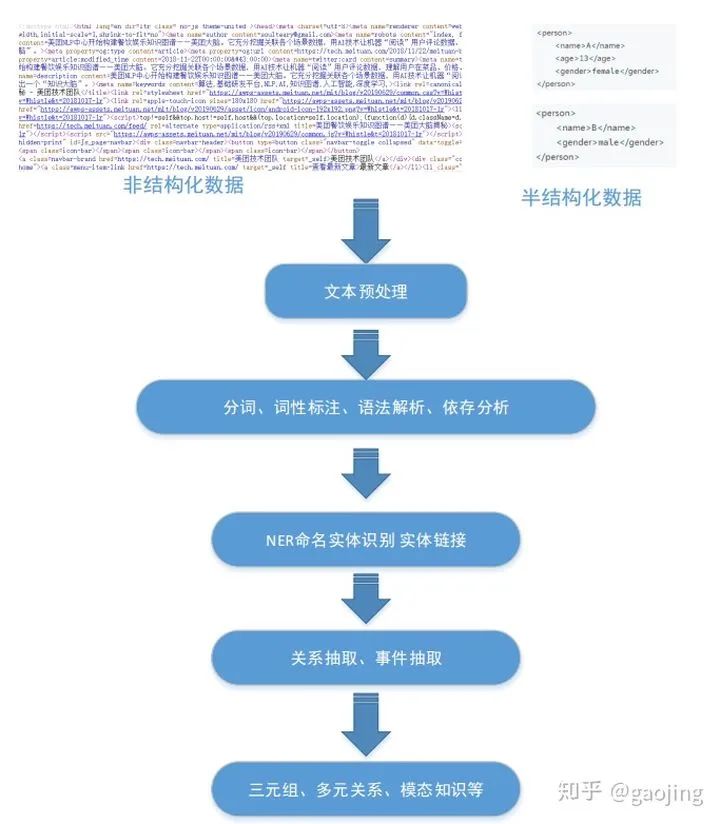
实体抽取(NER命名实体识别)

实体链接
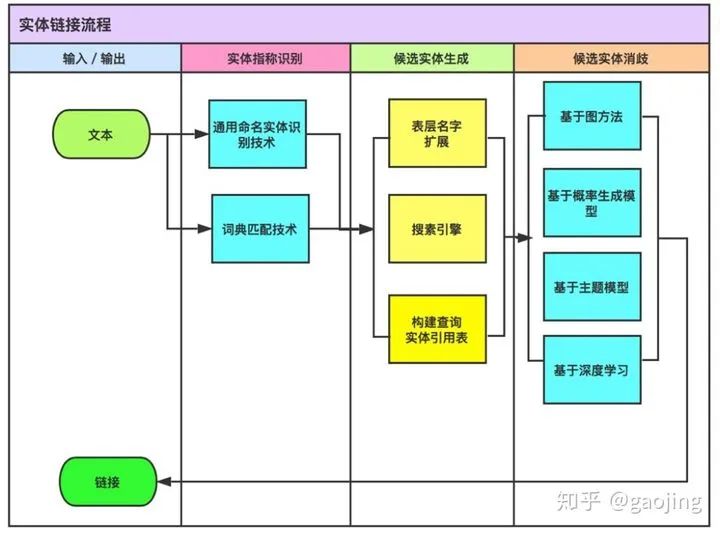
实体关系抽取

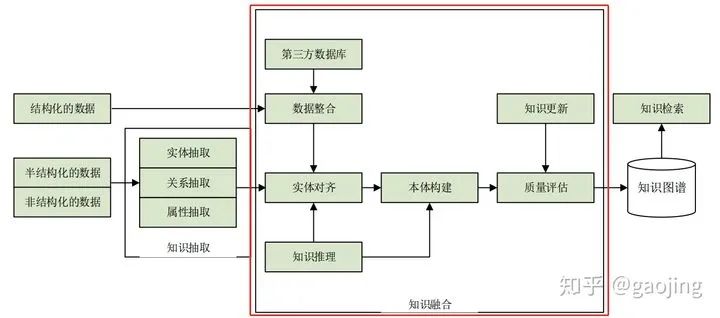
知识融合
知识融合-异构问题
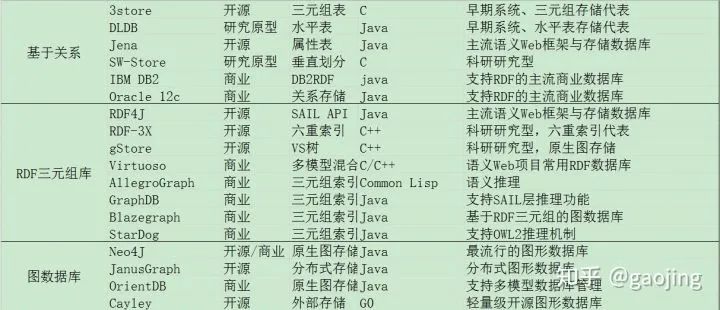
知识存储
知识图谱的知识存储一般是采用图形数据库进行存储,主要有两种图数据模型:RDF图和属性图 查询语言:RDF图---SPARQL;属性图:Cypher 和 Gremlin 常见知识图谱存储方式 基于关系数据库的存储方案 主要是三元组表(3store)、水平表(DLDB)、属性表(JENA)、垂直划分(SW-Store)、DB2RDF和六重索引(RDFX-3X、Hexastore) 面向RDF的三元组数据库 Jena RDF4J RDF-3X gStore 原生图数据库 Neo4j 分布式图形数据库 JanusGraph OrientDB Cayley 图形数据库对比

知识推理
基于演绎的知识图谱推理
基于归纳的知识图谱推理
基于图结构 基于规则学习 基于表示学习 新的方法 时序法 基于强化学习 基于图神经网路
开源工具
Jena和Drools
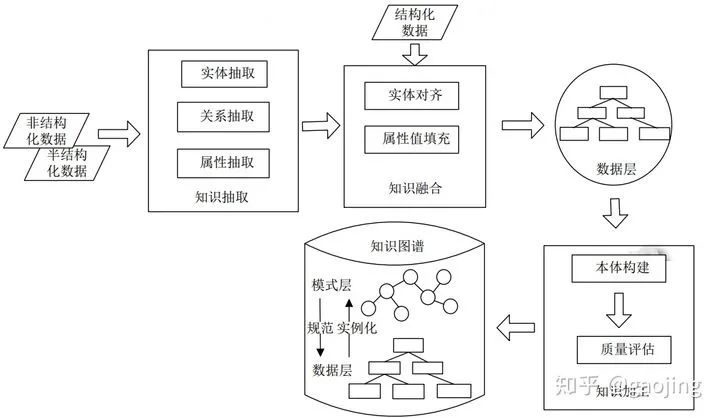
知识图谱构建流程
主要介绍主流的知识图谱构建流程,实体图谱的构建主要有自底向上、自顶向下和二则混合的方法,如下图所示,分别为自底向上和自顶向下

评论