
Jsrpc学习——Cookie变化的网站破解教程
共 3119字,需浏览 7分钟
·
2022-02-09 19:14
回复“资源”即可获赠Python学习资料
大家好,我是皮皮。前几天给大家分享jsrpc的介绍篇,Python网络爬虫之js逆向之远程调用(rpc)免去抠代码补环境简介,感兴趣的小伙伴可以戳此文前往。
今天给大家来个jsrpc实战教程,让大家加深对jsrpc的理解和认识。下面是具体操作过程,不懂的小伙伴可以私我。
1、对Cookie进行hook,需要在浏览器的控制台输入命令Object.defineProperty(document, "cookie", {set:function(a){debugger}})

2、之后点击下一页,进入debug模式
3、依次点击右边的Call Stack内的东西,直到找到加密函数,里边的值对应请求参数即可判定。
4、之后可以在控制台输入指令window.dcpeng = ct.update,其中ct.update为加密函数。注意:这个地方挺重要的,很多时候我们会写成ct.update(),这样会有问题!加了括号就是赋值结果,没加就是赋值整个函数!千差万别。
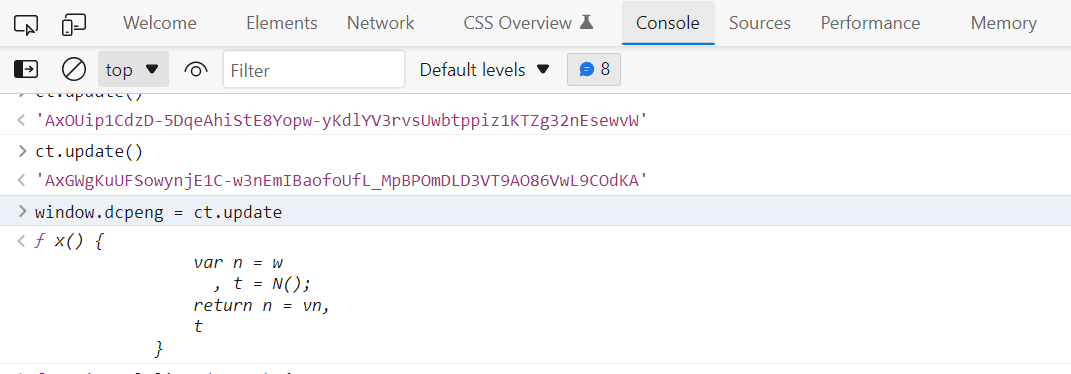
5、关闭网页debug模式。注意:这个地方挺重要的,很多时候如果不关闭,ws无法注入!
6、此时在本地双击编译好的文件win64-localhost.exe,启动服务。
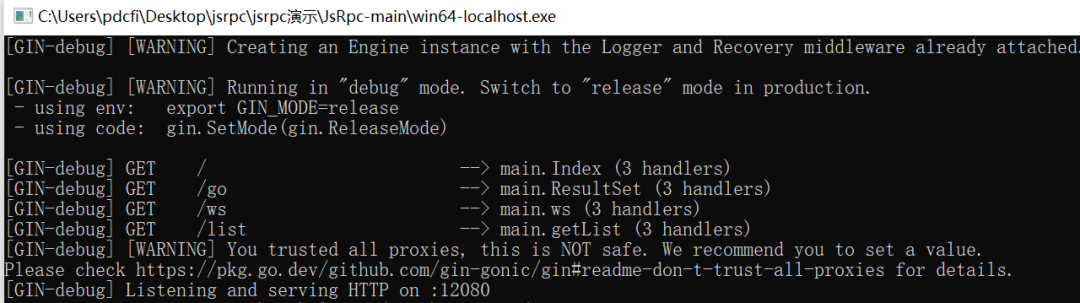
7、之后在控制台注入ws,即将JsEnv.js文件中的内容全部复制粘贴到控制台即可(注意有时要放开断点)。
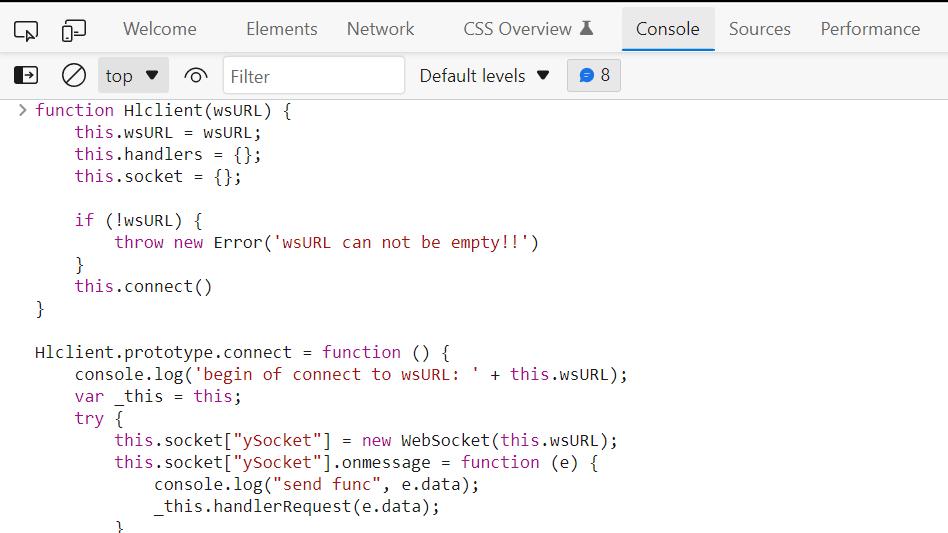
8、连接通信,在控制台输入命令var demo = new Hlclient("ws://127.0.0.1:12080/ws?group=v&name=test");
9、随后继续输入命令:
// 注册一个方法 第一个参数get_v为方法名,
// 第二个参数为函数,resolve里面的值是想要的值(发送到服务器的)
// param是可传参参数,可以忽略
demo.regAction("get_v", function (resolve, param) {
// var c = "好困啊" + param;
var c = dcpeng();
resolve(c);
})
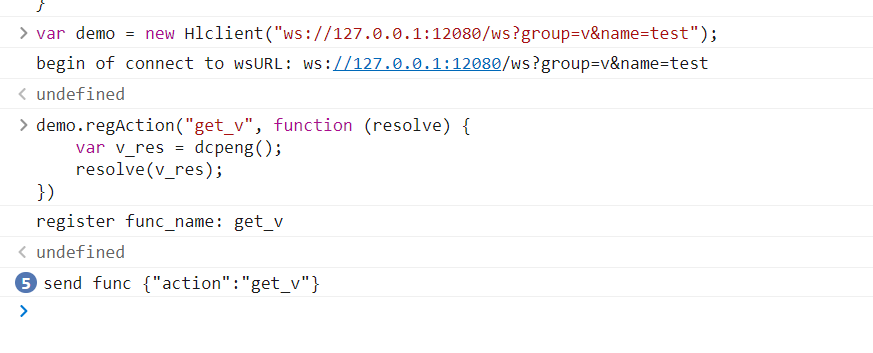
10、之后就可以在浏览器中访问数据了,打开网址 http://127.0.0.1:12080/go?group={}&name={}&action={}¶m={} ,这是调用的接口 group和name填写上面注入时候的,action是注册的方法名,param是可选的参数,这里续用上面的例子,网页就是:http://127.0.0.1:12080/go?group=v&name=test&action=get_v

11、如上图所示,我们看到了那个变化的参数v的值,直接通过requests库可以发起get请求。
12、现在我们就可以模拟数据,进行请求发送了。
13、将拷贝的内容可以丢到这里进行粘贴:http://tool.yuanrenxue.com/curl
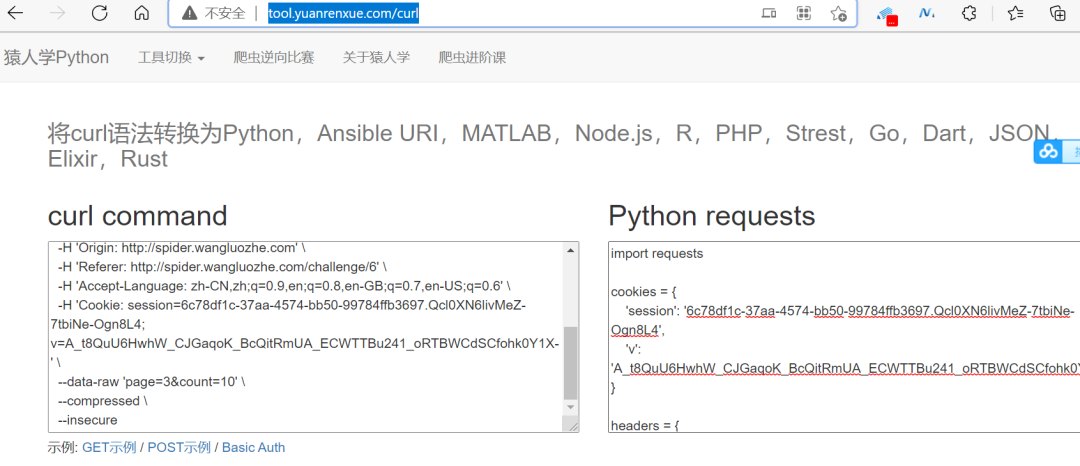
14、之后将右侧的代码复制到Pycharm中即可用,非常便利。
15、之后就可以构造请求了,整体代码如下所示。
import requests
v_url = "http://127.0.0.1:12080/go?group=v&name=test&action=get_v"
v_res = requests.get(url=v_url).json()["get_v"]
cookies = {
'session': '6c78df1c-37aa-4574-bb50-99784ffb3697.Qcl0XN6livMeZ-7tbiNe-Ogn8L4',
'v': v_res,
}
headers = {
'Connection': 'keep-alive',
'Accept': 'application/json, text/javascript, */*; q=0.01',
'X-Requested-With': 'XMLHttpRequest',
'hexin-v': 'A3_4zkkuI7xygCZatjHGiHM8DlgKZNPp7bnX-hFMGsZ175EOGTRjVv2IZ04i',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.99 Safari/537.36 Edg/97.0.1072.69',
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'Origin': 'http://spider.wangluozhe.com',
'Referer': 'http://spider.wangluozhe.com/challenge/6',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6',
}
data = {
'page': '3',
'count': '10'
}
response = requests.post('http://spider.wangluozhe.com/challenge/api/6', headers=headers, cookies=cookies, data=data, verify=False).json()
print(response)
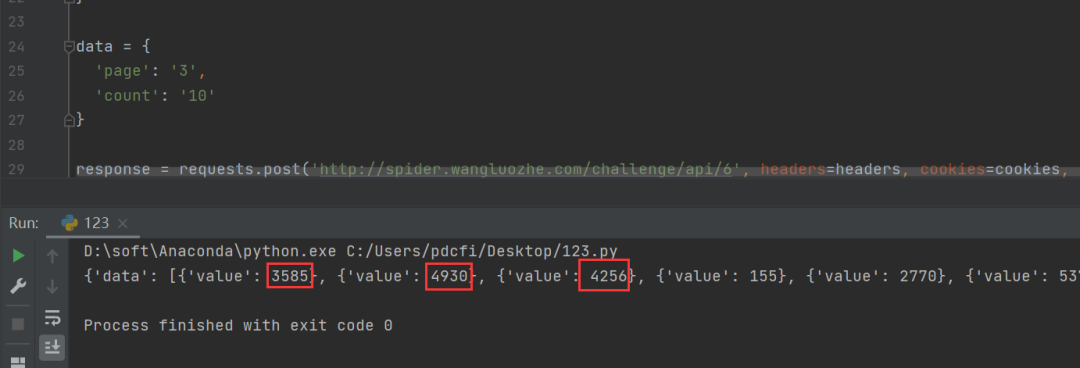
运行结果如上图所示,和网页上呈现的数据一模一样。
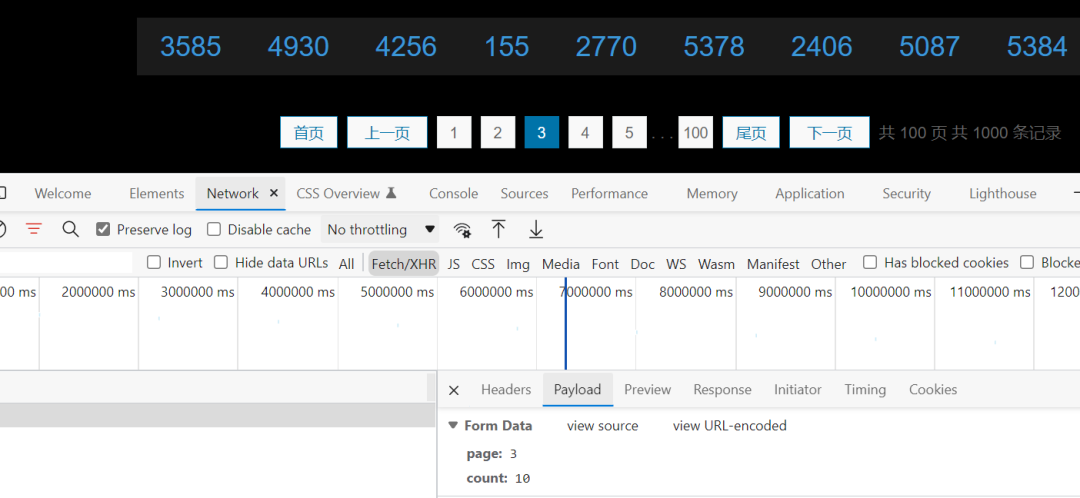
16、至此,请求就已经完美的完成了,如果想获取全部网页,构造一个range循环翻页即可实现。
17、也欢迎大家挑战该题目,我已经挑战成功了,等你来战!
总结
大家好,我是皮皮。这篇文章主要给大家介绍了jsrpc的实战教程,使用jsrpc工具可以在网络爬虫过程中事半功倍,无需仔细的去扣环境,去一步步逆向,只一个黑盒的模式,我们就拿到了想要的结果,屡试不爽。
初次接触jsrpc的小伙伴可能看不懂,这里还有黑哥录制的一个视频,大家可以对照视频进行学习,地址:https://www.bilibili.com/video/BV1EQ4y1z7GS,黑哥全程无声演示,视频的BGM很大,建议大家可以静音播放,领会其中奥义。
关于jsrpc工具,可以点击原文前往获取。
小伙伴们,快快用实践一下吧!如果在学习过程中,有遇到任何问题,欢迎加我好友,我拉你进Python学习交流群共同探讨学习。
------------------- End -------------------
往期精彩文章推荐:

欢迎大家点赞,留言,转发,转载,感谢大家的相伴与支持
想加入Python学习群请在后台回复【入群】
万水千山总是情,点个【在看】行不行