
带你了解Git大仓库
前言
Git 是目前世界上最为广泛使用的软件版本控制系统(Version Control System),同时也是一个成熟及活跃的开源项目。

在git-scm.com点击git图标,你可以看到如下几句话:
--fast-version-control (快捷的版本控制) --local-branching-on-the-cheap (廉价的本地分支) --distributed-is-the-new-centralized (分布式是新的集中式) --distributed-even-if-your-workflow-isnt(分布式,且与你的工作流无关) --everything-is-local(一切本地化)
Git 最初是由 Linux 之父 Linus Torvalds 在 2005 年创建,截至目前共有1500多名贡献者参与其中。
Git使用范围虽广,但仍有一个普遍的共识:Git并不适合用于维护巨型的仓库。接下来,让我们一起来深入了解一下其中的原因,以及有哪些可以优化的手段。
1.什么是大仓库?
提到大仓库,大家通常会联想到单仓Monorepo。
业内最出名的几家monorepo实践分别是:
Google,基于 Perforce[1] 开发而来的Piper。 Facebook,基于 Mercurial[2] 定制化实现。 Microsoft,基于 Windows 虚拟文件系统及 Git 开发而成的 GitVFS[3] 。
以上这些 Monorepo 实践,无一不依赖内部/特定的基础设施;并且,想要落地并不是解决了代码托管这一个问题就可以万事大吉,还需要整个研发生态能力的支持。
在Monorepo基础设施建设尚不完善的今天,大多数厂商都选择基于Git来尝试探索Monorepo实践。那么,让我们把焦点聚焦在Git单体大仓库(即单体大于100GB)。
2.Git大仓库带来哪些挑战?
2.1 存储挑战
我们第一个要面临的就是如何存一个巨大的Git单仓。
在通常的认知当中,Git仓库是一个完整的个体(不考虑shallow clone的情况下)。Git 之所以称为分布式版本控制系统,也正是由于它区别于 SVN 等中央版本控制系统, 其最大差异点在于,在每一个仓库的使用者那里,都维护了完整的 Git 仓库数据,任何人都可以选择将自己本地的内容作为中心副本来维护。
在今天,不论是我们的个人电脑还是服务器,存储容量都已经大幅升级;所以看来,将100GB的仓库存储到本地,似乎并不是什么难题。那假如,类比Google PB(1PB=1024TB)级别的代码资产,都存储到Git当中,你是否仍然可以把它下载到本地呢(😣)?答案显然是否定。
有人会说,那使用共享存储(如NAS),是否可以解决存储的问题呢?
答案是该方案会遇到较大的性能挑战,让我们一起往下看。
2.2 性能挑战
性能挑战主要在读和写两个方面,让我们先来看看写性能挑战。
2.2.1 并发协作(写)
如果一个仓库只是几个人维护,那即使这个仓库的体积变得非常大,有些问题还是可以忍受的;但挖大坑(😝) 的,往往是一个很大的团队(数千人,甚至数万人)。
以千人实践主干模式为例,你可能需要:
清晰的管理方案:上千个松散引用(引用 reference refs/*,常见的分支branch refs/heads/*及标签tag refs/tags/*都属于引用的范畴)来维护每个人的特性。 更为合理的多副本架构,来解决单点负载不足问题。 一个良好的Checkin机制,来解决root tree争夺问题。
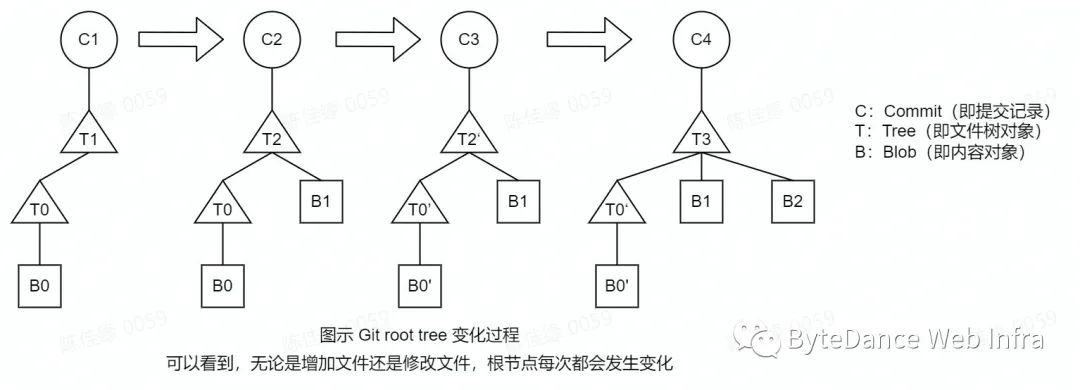
更为顺畅的垃圾回收机制,避免仓库陷入无限GC循环(默认6700个松散对象触发autogc,可能一个GC还未结束,又一次新的GC在路上了)。
2.2.2 大范围查找(读)
在前面的图中,我们也可以看到,Git是通过commits树来串联整个版本历史的。在不借助额外的索引的情况下,可以认为git的对象是离散存储在文件当中的。
Git的对象存储包含两个部分:
松散对象:存储在 objects/xx 目录下,每个文件就是一个对象。 包文件(packfile):存储在 objects/pack 目录下,相较于松散对象,pack是一组对象的集合,拥有一个索引文件 pack-xxx.idx;当然,在仓库较大的情况下,还会包含多个打包文件。
➜ objects git: tree
.
├── 03
│ └── 273f5843529db977846d7c6fd28dc790123d38
├── 7f
│ ├── ec94d35df31a1deb570f8b863526a27f148f48
│ └── ff37186bcf8a8f5428aa168f981c9094bef2e6
├── info
└── pack
├── pack-0c63ce8bd48a11517c3f1775d9060d45c088afc5.idx
├── pack-0c63ce8bd48a11517c3f1775d9060d45c088afc5.pack
├── pack-47155f8be24f5b6666bf849d681f831d5f34bffe.idx
└── pack-47155f8be24f5b6666bf849d681f831d5f34bffe.pack查找指定对象的过程,如 git cat-file -t xxx。
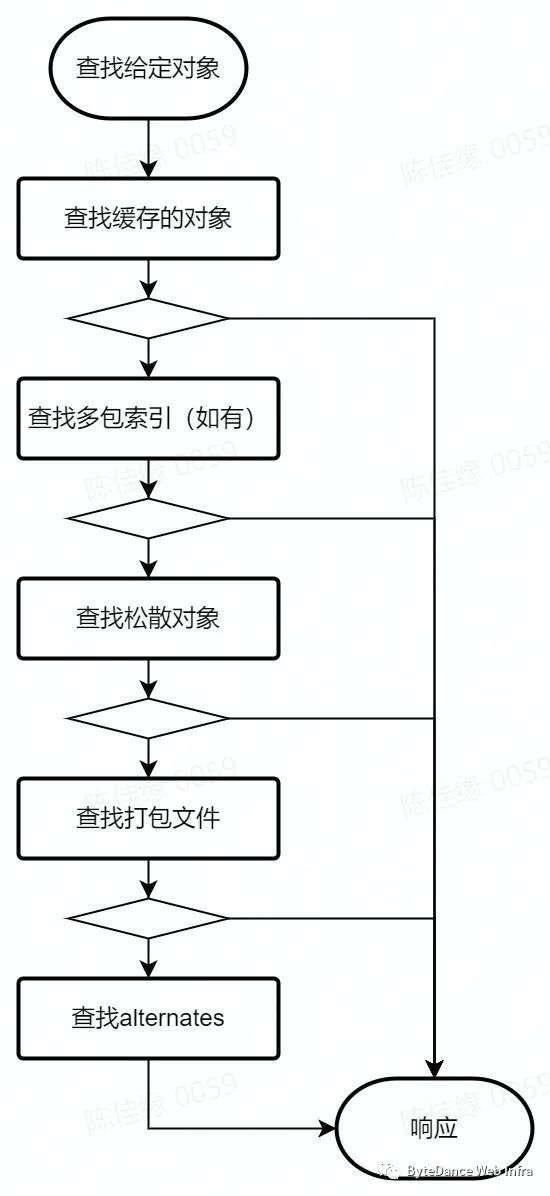
如图所示,在上述没有多包索引的仓库中,如果我们想要根据一个hash值来查找指定对象,首先需要遍历松散对象目录查找是否存在于松散对象,而后再逐个查询打包文件,在打包文件较多的情况下,逐个遍历索引的效率也并不高。
如果你说,性能问题我忍了,那我是不是可以高枕无忧(🤔)?答案也是否定的。
2.3 稳定性挑战
二八定律同样也适用在代码托管领域。
而极为少数的单体大仓库,往往能得到额外的优待:
独享的机器资源 更多的技术支持占用 更高的技术关注度
人肉炸弹💣——某次生产环境代码存储节点上的内存使用变化:
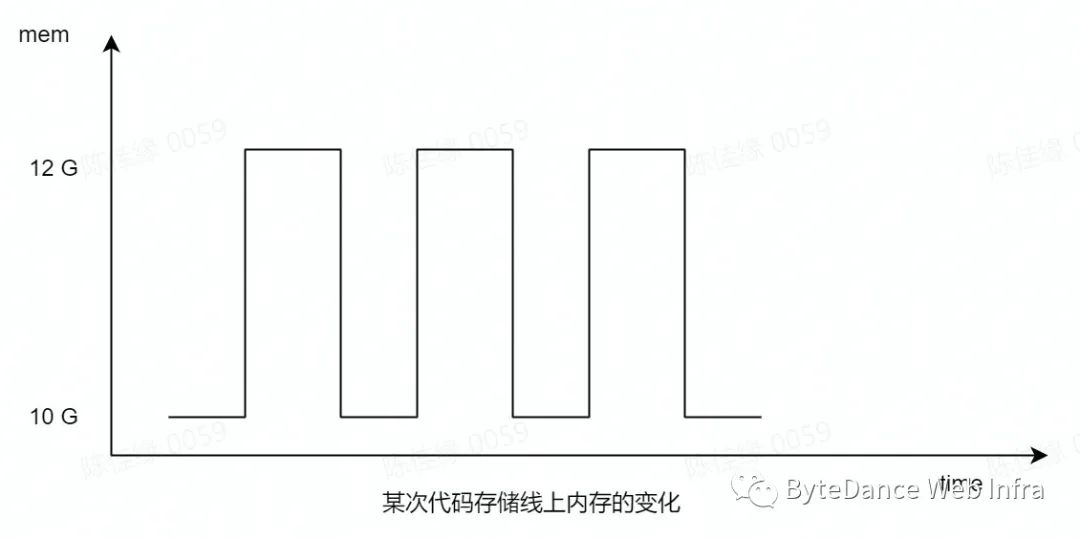
而类似问题,可能还需要在Git当中进行优化才能得以解决,参考《unpack-objects: support streaming blobs to disk》[4]。
2.4 可靠性挑战
让我们再来思考一个问题,对于存储类的服务,我们要守住的底线是什么?
我认为,必须要守住的底线是数据完整性。我们可以接受一定时间的服务不可用,我们可以通过各种手段,提升我们的服务可用率;但若是出现数据完整性问题,那对用户带来的影响是更加大的。
虽然Git自带的hashsum,可以解决数据完整性校验问题,但解不了所有问题,因为:
Git是IO密集 大仓库加剧了IO消耗
3.如何应对Git单体大仓库?
看完了问题,让我们再来看看有哪些解决方案。
3.1 事前预防
3.1.2 如何控制仓库膨胀?
在不考虑 submodule 及 Git-repo[5] 进行逻辑拆分的情况下,如何控制仓库的体积?
我们先来看,导致仓库体积超过预期的原因都有哪些?
大型的二进制文件(如图片资源、可执行程序、Office文档等)。
# 取top20的大文件
git rev-list --objects --all | grep "$(git verify-pack -v .git/objects/pack/*.idx | sort -k 3 -n | tail -20 | awk '{print$1}')"
# 取大于500k的大文件
git rev-list --objects --all | grep "$(git verify-pack -v .git/objects/pack/*.idx | awk '{if($3>500000)print $1}')"大量的无用引用(如早先版本的gitlab在添加文件等场景下会创建tmp引用,并缺少清理机制)。
git的GC机制仅会移除不可达的对象(不存在于任何一个引用上)。 庞大的文件数据及版本记录(针对这个问题,我们需要区分对待)。
例如:iOS的应用依赖管理工具Cocoapods。
对症下药:
对于二进制文件,可以借助 https://github.com/git-lfs/git-lfs[6],将文件上传到对象存储。
Git-lfs 的落地,依赖客户端的安装,存在一定的成本,但确是上选。 对于非预期的提交,添加 pre-commit hook 做本地拦截也是一个好选择。 活用.gitignore,排除编译产物、非必要依赖等的提交。 引用清理:
本地经常性进行开发分支清理并GC是一个不错的选择。 选择更合理的存储服务:
对版本要求不高的场景,对象存储(Object Storage,如火山云产品TOS[7])的成本更为低廉。
3.1.3 如何高效识别用户大文件提交?
行业内的普遍做法
通过pre-receive hook,对隔离区(Quarantine,objects/incoming-xxxx)中的对象大小进行识别,其中松散对象可以通过文件头中的size来判断,packfile则通过git verify-pack 。
但是这个方案的效率并不高:
需要遍历隔离区的所有对象,事先并不知道哪些对象是commit、哪些是blob。 verify-pack的核心用途是校验packfile的完整性,对读取完整的数据;而我们的场景,只需求文件大小。
更优的方案
在2021年11月与来自Github的Peff(Jeff King)的交流中,得到了新的启发:
https://lore.kernel.org/git/YaUmFpIeCvHdKixj@coredump.intra.peff.net/
We also set GIT_ALLOC_LIMIT to limit any single allocation. We also have custom code in index-pack to detect large objects (where our definition of "large" is 100MB by default): - for large blobs, we do index it as normal, writing the oid out to a file which is then processed by a pre-receive hook (since people often push up large files accidentally, the hook generates a nice error message, including finding the path at which the blob is referenced) - for other large objects, we die immediately (with an error message). 100MB commit messages aren't a common user error, and it closes off a whole set of possible integer-overflow parsing attacks (e.g., index-pack in strict-mode will run every tree through fsck_tree(), so there's otherwise nothing stopping you from having a 4GB filename in a tree).
我们可以在执行 index-pack / unpack-objects 的过程中,将对象的oid、类型、大小记录在额外的文件中,在后续pre-receive hook执行的时候,就可以根据已有的结果来做展示信息加工。在这个过程中,无需再遍历所有的对象及packfile整体,复用了数据接收过程,这对大型仓库的效率提升是显著的。
3.2 事中提效
3.2.1 如何下载一个Git大仓?
通常会遇到如下问题:
引用发现慢 对象计算久 网络不稳定中断
可以怎么做:
使用 protocol version 2
以 https://github.com/kubernetes/kubernetes 为例,如果下载该仓库的全量引用,总共有近10w,而如果仅关心 branches 及 tags,那么仅有不到 1k。
10:39:01.435687 pkt-line.c:80 packet: clone> ref-prefix HEAD
10:39:01.435692 pkt-line.c:80 packet: clone> ref-prefix refs/heads/
10:39:01.435696 pkt-line.c:80 packet: clone> ref-prefix refs/tags/Git 在 2.18以后就开始支持新的协议,在更新的版本中,更是将 v2 作为默认协议,在这个协议下可以有更好的表达空间。
如果你的Git版本不高,可以考虑增加设置使用v2:
git config --global protocol.version=2使用 shallow clone
如果你不那么关心历史版本,shallow clone是一个不错的选择。
git clone --depth=100 git@github.com:kubernetes/kubernetes.git使用 partial clone[8]
比如我也想试试本地维护一个linux,同时也想看看这个拥有100w个commits仓库的演进历史,我可以这么做:
git clone --filter=blob:none git@github.com:torvalds/linux.git使用bundle
Git当中,提供了将所有对象及引用打包的能力 git bundle,借助对象存储及CDN,可以对文件进行分段读取,在网络条件不好的情况下,真的可以救命。
目前Git社区的 Derrick Stolee 及 Ævar Arnfjörð Bjarmason 正在推进bundle uri能力的落地,这将更好地改善大仓库的下载体验。
https://lore.kernel.org/git/pull.1234.git.1653072042.gitgitgadget@gmail.com/
3.2.2 如何在减小本地工作空间
好不容易把一个Git的仓库下载下来,往往检出又成了难题。
Git仓库中的文件都是经过压缩的,而解压缩之后,体积往往成倍膨胀开来;而对于一个大库,我们可能只关心其中的某个路径,这时候,就轮到 git sparse-checkout 登场了。
下图摘自:[《Bring your monorepo down to size with sparse-checkout》9]
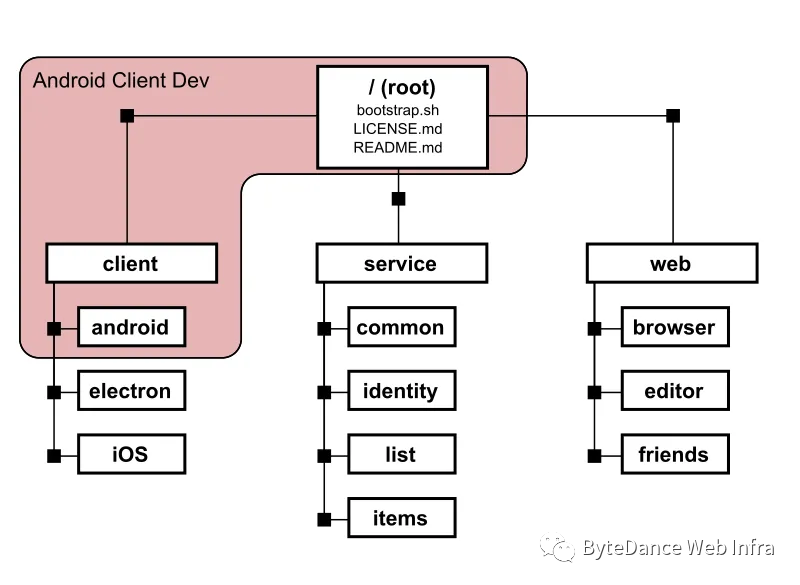
顺带一提,微软的大仓库客户端scalar目前也已经进入git的子项目进行孵化,后续可以在git当中使用。
https://github.com/git/git/tree/master/contrib/scalar
Scalar is an add-on to Git that helps users take advantage of advanced performance features in Git. Originally implemented in C# using .NET Core, based on the learnings from the VFS for Git project, most of the techniques developed by the Scalar project have been integrated into core Git already:
partial clone,
commit graphs,
multi-pack index,
sparse checkout (cone mode),
scheduled background maintenance,
etc
3.2.2 如何提升访问效率?
在前文“2.2 性能挑战”当中,我们已经了解了Git如何存储及查找对象的方式。
对于Git访问来说,影响访问效率的核心在于需要解决两个问题:
这个对象是什么? 这个对象和其他对象的关系是什么?
Git大仓库的性能优化,一直也来也是社区非常关注的问题,为此,社区引入了几个特性:
1. 回答关系的问题:
Git当中引入了commit-graph[10],通过记录commit的root tree、parents、date等信息,加速了commits遍历的效率。Commit-graph 可以通过
core.commitGraph配置进行开启。
2. 回答是什么的问题:
Git当中引入了bitmap[11],通过 Commits、Trees、Blobs、Tags 4个位图,在无需读取对应对象的头信息的情况下,就可以知道对象的类型及位置信息。
这里有人会说,bitmap 只能解决 单个packfile的场景,多个packfile就失效了。
在多个packfile的情况下,
core.multiPackIndex开启多包索引,进行packfile的索引合并,也可以加速对象索引的过程。此外,在Git的 v2.34.0 当中,引入了multi-pack-bitmap,至此针对于多包场景下的几何打包策略(geometric repack,参见《Scaling monorepo maintenance》[12])开始登上舞台。
3.3 事后优化
3.3.1 优化存量仓库
坦言,今天对于合理发展的存量大仓库,并没有太多可以瘦身的手段。
而对于“3.1.2 如何控制仓库膨胀?”中提到的不合理的场景,我们可以借助 git filter-branch 等手段进行历史版本重写,移除其中的大对象。
这个操作本身存在较大的风险,并且在版本重写之后,所有用户本地的副本也要重新从远端拉取,在执行成本上也是非常高的。
3.3.2 增量冷备
bundle冷备无论是为了bundle uri能力预设,还是预防非预期问题上,都是代码安全能力建设的一道重要防线。而在传统的全量备份方案上,Git单体大仓极大提升了备份的周期及难度。
而随着增量bundle能力的支持,针对大仓库的冷备也不再那么困难,我们可以基于先前的备份做增量补丁。
增量bundle支持:https://lore.kernel.org/git/20210103095457.6894-1-worldhello.net@gmail.com/
小结
我们从Git单体大仓库入手,了解了其带来的存储、性能、可靠性等方面的挑战,并且我们从事前、事中、事后三个角度提出了针对一些问题的解决/优化方案。
当然,今天所提到的也只是几个比较经典的问题,还有更多的问题及解决方案等待我们在实践中持续探索。
附录
Perforce:https://www.perforce.com/
Mercurial:https://www.mercurial-scm.org/
VFSForGit:https://github.com/microsoft/VFSForGit
《unpack-objects: support streaming blobs to disk》:https://lore.kernel.org/git/cover.1654914555.git.chiyutianyi@gmail.com/
git-repo:https://gerrit.googlesource.com/git-repo
git-lfs:https://github.com/git-lfs/git-lfs
TOS:https://www.volcengine.com/product/tos
partial clone:https://git-scm.com/docs/partial-clone
《Bring your monorepo down to size with sparse-checkout》:https://github.blog/2020-01-17-bring-your-monorepo-down-to-size-with-sparse-checkout/
commit-graph:https://github.com/git/git/blob/master/Documentation/technical/commit-graph.txt
bitmap:https://github.com/git/git/blob/master/Documentation/technical/bitmap-format.txt
Scaling monorepo maintenance:https://github.blog/2021-04-29-scaling-monorepo-maintenance/