
智算中心网络架构选型及对比

通常,在在AI智算系统中,一个模型从生产到应用,一般包括离线训练和推理部署两大阶段;本文选自“智算中心网络架构白皮书(2023)”“智能计算中心规划建设指南”,常用的对IB和ROCE V2高性能网络进行全面的分析对比。
1. 智算网络是复用当前的TCP/IP通用网络的基础设施,还是新建一张专用的高性能网络?
2. 智算网络技术方案采用 InfiniBand 还是 RoCE ?
3. 智算网络如何进行运维和管理?
-
4. 智算网络是否具备多租户隔离能力以实现对内和对外的运营?
离线训练,就是产生模型的过程。用户需要根据自己的任务场景,准备好训练模型所需要的数据集以及神经网络算法。模型训练开始后,先读取数据,然后送入模型进行前向计算,并计算与真实值的误差。然后执行反向计算得到参数梯度,最后更新参数。训练过程会进行多轮的数据迭代。训练完成之后,保存训练好的模型,然后将模型做上线部署,接受用户的真实输入,通过前向计算,完成推理。因此,无论是训练还是推理,核心都是数据计算。为了加速计算效率,一般都是通过 GPU 等异构加速芯片来进行训练和推理。

随着以 GPT3.0 为代表的大模型展现出令人惊艳的能力后,智算业务往海量参数的大模型方向发展已经成为一个主流技术演进路径。以自然语言处理(NLP)为例,模型参数已经达到了千亿级别。计算机视觉(CV) 、广告推荐、智能风控等领域的模型参数规模也在不断的扩大,正在往百亿和千亿规模参数的方向发展。
在自动驾驶场景中,每车每日会产生 T 级别数据,每次训练的数据达到 PB 级别。大规模数据处理和大规模仿真任务的特点十分显著,需要使用智算集群来提升数据处理与模型训练的效率。
大模型训练中大规模的参数对算力和显存都提出了更高的要求。以GPT3为例,千亿参数需要2TB显存,当前的单卡显存容量不够。即便出现了大容量的显存,如果用单卡训练的话也需要32年。为了缩短训练时间,通常采用分布式训练技术,对模型和数据进行切分,采用多机多卡的方式将训练时长缩短到周或天的级别。

分布式训练就是通过多台节点构建出一个计算能力和显存能力超大的集群,来应对大模型训练中算力墙和存储墙这两个主要挑战。而联接这个超级集群的高性能网络直接决定了智算节点间的通信效率,进而影响整个智算集群的吞吐量和性能。要让整个智算集群获得高的吞吐量,高性能网络需要具备低时延、大带宽、长期稳定性、大规模扩展性和可运维几个关键能力。
分布式训练系统的整体算力并不是简单的随着智算节点的增加而线性增长,而是存在加速比,且加速比小于 1。存在加速比的主要原因是:在分布式场景下,单次的计算时间包含了单卡的计算时间叠加卡间通信时间。因此,降低卡间通信时间,是分布式训练中提升加速比的关键,需要重点考虑和设计。
降低多机多卡间端到端通信时延的关键技术是 RDMA 技术。RDMA 可以绕过操作系统内核,让一台主机可以直接访问另外一台主机的内存。
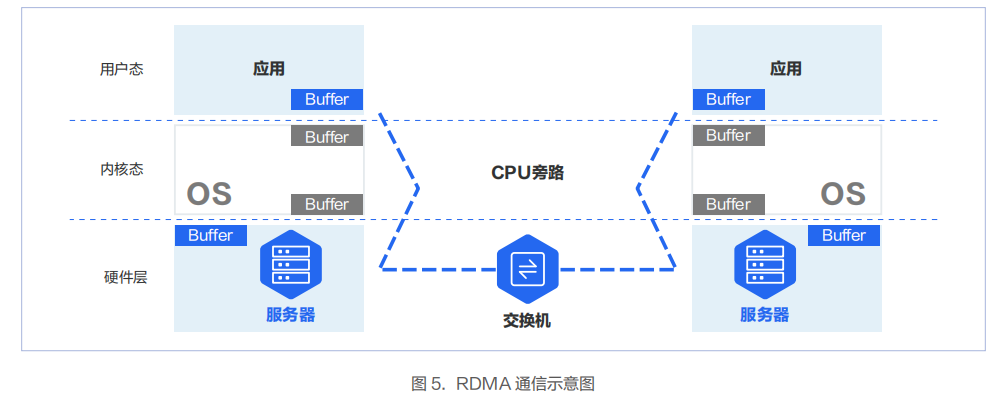
实 现 RDMA 的 方 式 有 InfiniBand、RoCEv1、RoCEv2、i WARP 四 种。其 中 RoCEv1 技 术 当 前 已 经 被 淘 汰,iWARP 使用较少。当前 RDMA 技术主要采用的方案为 InfiniBand 和 RoCEv2 两种。

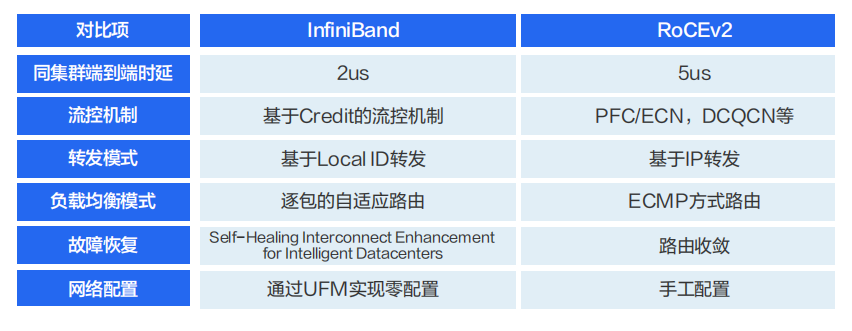
在 InfiniBand 和 RoCEv2 方案中,因为绕过了内核协议栈,相较于传统 TCP/IP 网络,时延性能会有数十倍的改善。在同集群内部一跳可达的场景下,InfiniBand 和 RoCEv2 与传统 IP 网络的端到端时延在实验室的测试数据显示,绕过内核协议栈后,应用层的端到端时延可以从 50us(TCP/IP),降低到 5us(RoCE)或 2us(InfiniBand)。

在完成计算任务后,智算集群内部的计算节点需要将计算结果快速地同步给其他节点,以便进行下一轮计算。在结果同步完成前,计算任务处于等待状态,不会进入下一轮计算。如果带宽不够大,梯度传输就会变慢,造成卡间通信时长变长,进而影响加速比。
要满足智算网络的低时延、大带宽、稳定运行、大规模以及可运维的需求,目前业界比较常用的网络方案是 InfiniBand方案和 RoCEv2 方案。
一、InfiniBand网络介绍
InfiniBand网络的关键组成包括Subnet Manager(SM)、InfiniBand 网卡、InfiniBand交换机和InfiniBand连接线缆。
支持 InfiniBand 网卡的厂家以 NVIDIA 为主。下图是当前常见的 InfiniBand 网卡。InfiniBand 网卡在速率方面保持着快速的发展。200Gbps 的 HDR 已经实现了规模化的商用部署,400Gbps 的 NDR的网卡也已经开始商用部署。

在InfiniBand交换机中,SB7800 为 100Gbps 端口交换机(36*100G),属于 NVIDIA 比较早的一代产品。Quantum-1 系列为 200Gbps 端口交换机(40*200G),是当前市场采用较多的产品。
在 2021 年,NVIDIA 推出了 400Gbps 的 Quantum-2 系列交换机(64*400G)。交换机上有 32 个 800G OSFP(Octal Small Form Factor Pluggable)口,需要通过线缆转接出 64 个 400G QSFP。
InfiniBand 交换机上不运行任何路由协议。整个网络的转发表是由集中式的子网管理器(Subnet Manager,简称 SM)进行计算并统一下发的。除了转发表以外,SM 还负责管理 InfiniBand 子网的 Partition、QoS 等配置。InfiniBand 网络需要专用的线缆和光模块做交换机间的互联以及交换机和网卡的互联。
InfiniBand 网络方案特点
(1)原生无损网络
InfiniBand 网络采用基于 credit 信令机制来从根本上避免缓冲区溢出丢包。只有在确认对方有额度能接收对应数量的报文后,发送端才会启动报文发送。InfiniBand 网络中的每一条链路都有一个预置缓冲区。发送端一次性发送数据不会超过接收端可用的预置缓冲区大小,而接收端完成转发后会腾空缓冲区,并且持续向发送端返回当前可用的预置缓冲区大小。依靠这一链路级的流控机制,可以确保发送端绝不会发送过量,网络中不会产生缓冲区溢出丢包。

(2)万卡扩展能力
InfiniBand 的 Adaptive Routing 基于逐包的动态路由,在超大规模组网的情况下保证网络最优利用。InfiniBand 网络在业界有较多的万卡规模超大 GPU 集群的案例,包括百度智能云,微软云等。
目前市场上主要的 InfiniBand 网络方案及配套设备供应商有以下几家。其中,市场占有率最高的是 NVIDIA,其市场份额大于 7 成。
NVIDIA:NVIDIA是InfiniBand技术的主要供应商之一,提供各种InfiniBand适配器、交换机和其他相关产品。
Intel Corporation:Intel是另一个重要的InfiniBand供应商,提供各种InfiniBand网络产品和解决方案。
Cisco Systems:Cisco是一家知名的网络设备制造商,也提供InfiniBand交换机和其他相关产品。
Hewlett Packard Enterprise:HPE是一家大型IT公司,提供各种InfiniBand网络解决方案和产品,包括适配器、交换机和服务器等。
2、RoCEv2 网络介绍
InfiniBand 网络在一定程度上是一个由 SM(Subnet Manager,子网管理器)进行集中管理的网络。而 RoCEv2 网络则是一个纯分布式的网络,由支持 RoCEv2 的网卡和交换机组成,一般情况下是两层架构。
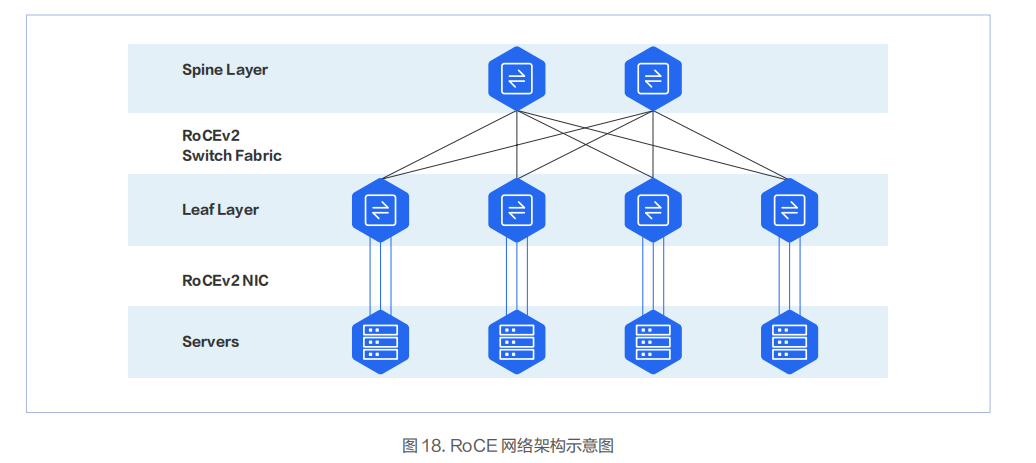
支持 RoCE 网卡的厂家比较多,主流厂商为 NVIDIA、Intel、Broadcom。数据中心服务器网卡主要以 PCIe 卡为主。RDMA 网卡的端口 PHY 速率一般是 50Gbps 起,当前商用的网卡单端口速率已达 400Gbps。

当前大部分数据中心交换机都支持 RDMA 流控技术,和 RoCE 网卡配合,实现端到端的 RDMA 通信。国内的主流数据中心交换机厂商包括华为、新华三等。
高性 能 交 换 机的核心 是 转发 芯片。当前 市场上的商用转发 芯片用的比 较 多的是博通的 Tomahawk 系列芯片。其中Tomahawk3 系列的芯片在当前交换机上使用的比较多,市场上支持 Tomahawk4 系列的芯片的交换机也逐渐增多。

RoCEv2 承载在以太网上,所以传统以太网的光纤和光模块都可以用。
RoCEv2 网络方案特点
RoCE 方案相对于 InfiniBand 方案的特点是通用性较强和价格相对较低。除用于构建高性能 RDMA 网络外,还可以在传统的以太网络中使用。但在交换机上的 Headroom、PFC、ECN 相关参数的配置是比较复杂的。在万卡这种超大规模场景下,整个网络的吞吐性能较 InfiniBand 网络要弱一些。
支持 RoCE 的交换机厂商较多,市场占有率排名靠前的包括新华三、华为等。支持 RoCE 的网卡当前市场占有率比较高的是 NVIDIA 的 ConnectX 系列的网卡。
3、InfiniBand 和 RoCEv2网络方案对比
从技术角度看,InfiniBand 使用了较多的技术来提升网络转发性能,降低故障恢复时间,提升扩展能力,降低运维复杂度。

具体到实际业务场景上看,RoCEv2 是足够好的方案,而 InfiniBand 是特别好的方案。
业务性能方面:由于 InfiniBand 的端到端时延小于 RoCEv2,所以基于 InfiniBand 构建的网络在应用层业务性能方面占优。但 RoCEv2 的性能也能满足绝大部分智算场景的业务性能要求。
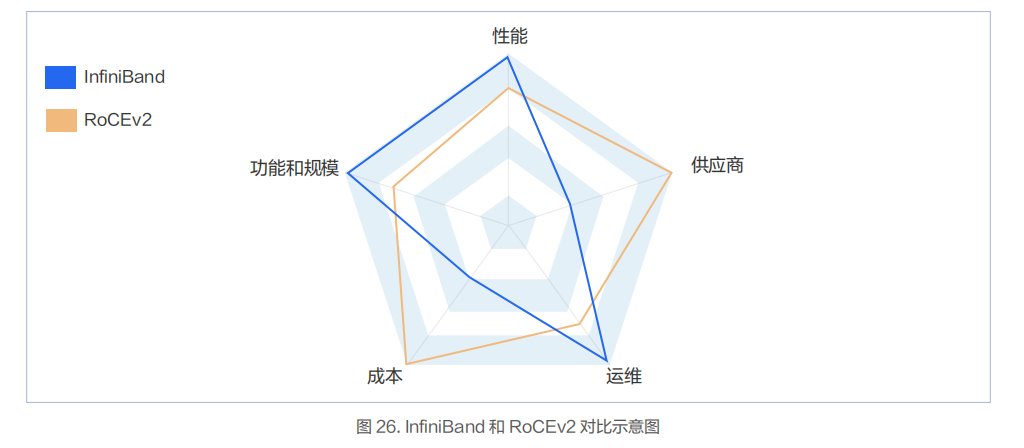
业务规模方面: InfiniBand 能支持单集群万卡 GPU 规模,且保证整体性能不下降,并且在业界有比较多的商用实践案例。RoCEv2 网络能在单集群支持千卡规模且整体网络性能也无太大的降低。
业务运维方面: InfiniBand 较 RoCEv2 更成熟,包括多租户隔离能力,运维诊断能力等。
业务成本方面: InfiniBand 的成本要高于 RoCEv2,主要是 InfiniBand 交换机的成本要比以太交换机高一些。
业务供应商方面: InfiniBand 的供应商主要以 NVIDIA 为主,RoCEv2 的供应商较多。
本文选自“智算中心网络架构白皮书(2023)”“智能计算中心规划建设指南”,更多智算中心技术请参考“算力铸就大模型:超算、智算及数据中心行业报告(2023)、2023年高性能计算研讨合集(上)、2023年高性能计算研讨合集(下)、AI基础知识深度专题详解合集等”。
推荐阅读
2、随着电子书数量增加及内容更新,价格会随之增加,所以现在下单最划算,购买后续可享全店内容更新“免费”赠阅。
温馨提示:
扫描二维码关注公众号,点击阅读原文链接获取“架构师技术全店资料打包汇总(全)”电子书资料详情。
