
python抓取、解析、下载小电影……

老实说是不是因为标题才点进来的 ?虽然我这里没有小电影,但是今天的内容也是实打实的干货,这叫授人以鱼不如授人以渔,有了这技术,小电影不也是分分钟的事嘛!
?虽然我这里没有小电影,但是今天的内容也是实打实的干货,这叫授人以鱼不如授人以渔,有了这技术,小电影不也是分分钟的事嘛!
前言
一到周末就想搞点有意思的事,比如之前分享的arduino开发,比如上周分享的博客爬虫,今天我又想搞点有意思的事,所以就有了今天的内容——python爬取m3u8视频资源。不过需要在这里需要着重说明的是,技术无罪,切勿用技术搞违法犯罪的事,不然日子真的就越来越有判头了 。
。
知识扩展
在开始抓取m3u8视频(小电影)之前,我们先了解下m3u8的相关知识,了解的更多,可以让我们少走弯路。
m3u8是什么?
在此之前,我仅仅知道m3u8是一种网络串流,在平时娱乐时候会找一些m3u8的资源,看看直播啥的,直到今天要分享m3u8的相关内容,才真正开始搜集m3u8的相关知识点。关于m3u8连百度百科都没有说明,搜到知乎一篇内容(【全网最全】m3u8到底是什么格式?一篇文章搞定m3u8下载),下面的原理图也是参照的这篇内容:
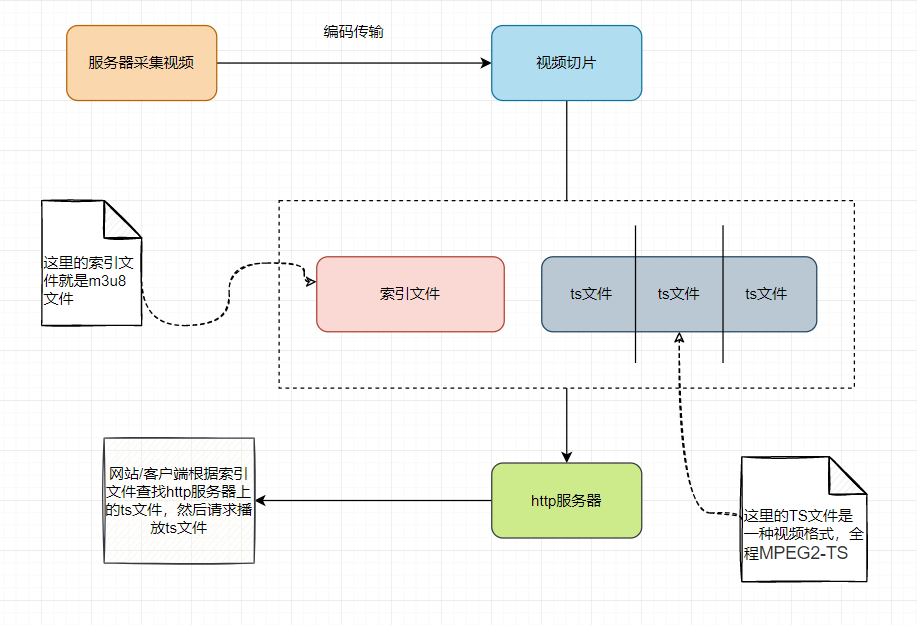
从上面的原理图中我们可以得到以下知识点:
首先 m3u8并非是视频格式,而是视频文件的索引。ts文件才是我们真正播放的视频资源。ts是日本高清摄像机拍摄下进行的封装格式,全称为MPEG2-TS。ts即"Transport Stream"的缩写。MPEG2-TS格式的特点就是要求从视频流的任一片段开始都是可以独立解码的。
m3u8通常分两种格式,一种是单码率(固定分辨率),一种是多码率(包含多种分别率)。下面就是一个单码率的m3u8文件的内容:
#EXTM3U
#EXT-X-VERSION:3
#EXT-X-TARGETDURATION:10
#EXT-X-MEDIA-SEQUENCE:1619459525
#EXT-X-PROGRAM-DATE-TIME:2021-10-23T05:39:42Z
#EXTINF:10.0,
1634967582-1-1619459525.hls.ts
#EXT-X-PROGRAM-DATE-TIME:2021-10-23T05:39:52Z
#EXTINF:10.0,
1634967592-1-1619459526.hls.ts
#EXT-X-PROGRAM-DATE-TIME:2021-10-23T05:40:02Z
#EXTINF:10.0,
1634967602-1-1619459527.hls.ts
这个就是一个多码率的m3u8文件,从多码率的文件格式可以看出来,多码率中包括了多个单码率是m3u8文链接:
#EXTM3U
#EXT-X-STREAM-INF:PROGRAM-ID=1,BANDWIDTH=500000,RESOLUTION=480x270
500kb/hls/index.m3u8
#EXT-X-STREAM-INF:PROGRAM-ID=1,BANDWIDTH=300000,RESOLUTION=360x202
300kb/hls/index.m3u8
m3u8文件指令
另外我在另外一篇博客发现m3u8其实是m3u文件的扩展(参考文档2),这可能就是为什么没有找到m3u8相关词条的原因吧,同时在m3u的词条中发现了M#U文件的指令描述(每个字段的含义):
#EXTM3U //必需,表示一个扩展的m3u文件
#EXT-X-VERSION:3 //hls的协议版本号,暗示媒体流的兼容性
#EXT-X-MEDIA-SEQUENCE:xx //首个分段的sequence number
#EXT-X-ALLOW-CACHE:NO //是否缓存
#EXT-X-TARGETDURATION:5 //每个视频分段最大的时长(单位秒)
#EXT-X-DISCONTINUITY //表示换编码
#EXTINF: //每个切片的时长
另外关于m3u的文件指令是有国际标准的,感兴趣的小伙伴可以去看下:
http://tools.ietf.org/html/draft-pantos-http-live-streaming-06
好了,关于m3u8的相关内容,我们就说这么多,感兴趣的小伙伴可以自己继续探索,下面我们看下如何用python抓取、解析和下载m3u8文件索引中的视频文。
抓取、解析、下载
首先我们先要拿到目标视频资源的索引文件,也就是m3u8文件。一般稍微懂点web开发的小伙伴,应该都知道浏览器抓包吧,F12打开浏览器控制台,然后选择Network,刷新下页面,在左侧资源区找到index.m3u8文件。
通常会有两个m3u8,第一个是获取视频码率列表的,也就是多码率m3u8,这个文件我们是没办法直接解析的,我们要找的是包含ts视频资源的m3u8文件。这里我随便在网上搜了一个葫芦娃的视频,然后通过控制台拿到m3u8文件地址:
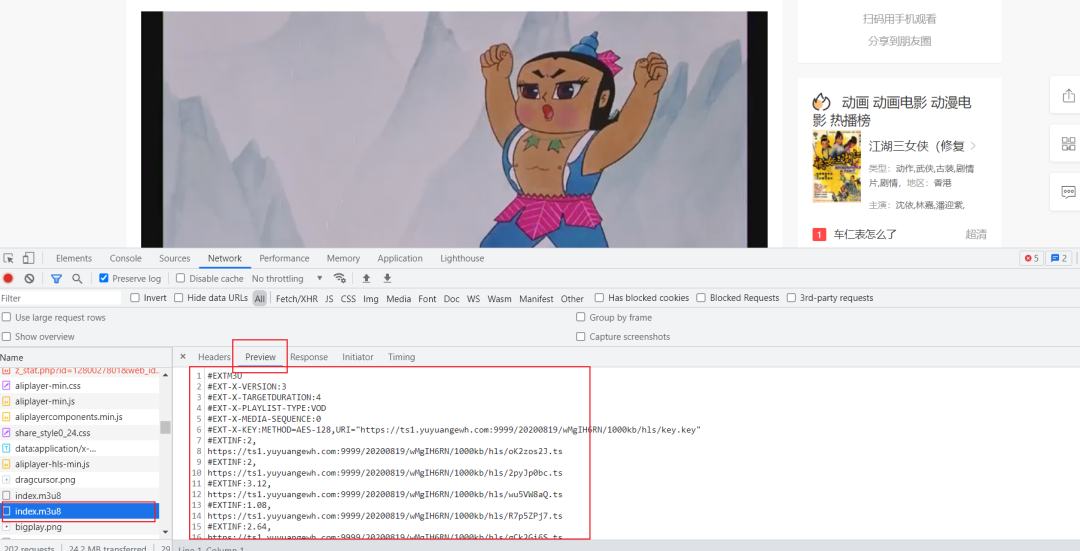
https://vod1.bdzybf1.com/20200819/wMgIH6RN/1000kb/hls/index.m3u8
下面我们就用python解析下载这个视频文件。
解析m3u8文件
解析m3u8文件最核心的地方是分析m3u8的文件结构,然后根据其文件内容写出对应的解析逻辑。这里我推荐直接用requests库模拟调用,然后分析响应结果,因为用文本工具之类的查看m3u8文件的话,换行符\n、制表符\t这些看起来不够直观,但是requests就不会有这个问题,因为我们解析的就是requests的响应结果。
这里的以我们上面m3u8文件为例响应结果如下:

可以清晰地看出,这个m3u8文件是通过换行符\n分割的,有部分m3u8文件中会出现制表符和换行符组合的情况,所以具体情况具体分析。
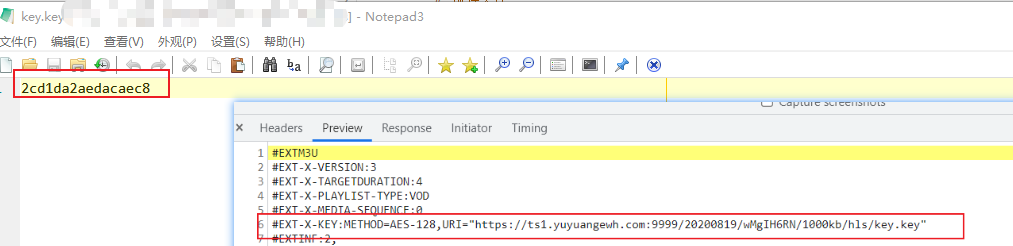
另外,我从响应内容中发现,这个视频资源是进行了AES-128加密的,所以后面在下载视频资源的时候要解密。
解析ts视频地址
因为python代码都很简单,代码量也不多,所以就不展开讲了,看代码注释应该可以看懂。这个方法主要是为了获取ts视频文件的地址。
import requests
def getTsFileUrlList(m3u8Url):
# 组装请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36'
}
# 请求 m3u8文件,并拿到文件内容
ts_rs = requests.get(url = m3u8Url, headers=headers).text
print(ts_rs)
# 换行符分割文件内容
list_content = ts_rs.split('\n');
print('list_content:{}'.format(list_content))
player_list = []
# 循环分割结果
for line in list_content:
# 以下拼接方式可能会根据自己的需求进行改动
if '#EXTINF' in line:
continue;
# 仅记录 ts文件地址
elif line.endswith('.ts'):
player_list.append(line)
print('数据列表组装完成-size: {}'.format(len(player_list)));
return player_list;
运行上面这个方法的话,最终会获取到m3u8索引文件中所有的ts视频地址,但是由于我们刚才已经从m3u8文件中发现了,视频资源是加密的,所以在下载的时候我们需要解密。
下载文件
这里的方法是下载并解密视频资源,这里我加了一个解密操作,因为注释够清晰,所以我也不过多赘述了
def fileDownloadWithdecrypt(fileSavePath, player_list):
# 创建文件夹
if not os.path.exists(fileSavePath):
os.mkdir(fileSavePath);
# 循环 ts 视频资源列表
for index, url in enumerate(player_list):
# 发送下载请求
ts_video = requests.get(url = url, headers=headers)
# 保存文件
with open('{}/{}.ts'.format(fileSavePath, str(index + 1)), 'wb') as file:
# 视频资源解密
context = decrypt(ts_video.content);
# 文件写入
file.write(context)
print('正在写入第{}个文件'.format(index + 1))
print('下载完成');
下面是解密代码
from Crypto.Cipher import AES # 用于AES解码
def decrypt(context):
# 加密的key
key = b'2cd1da2aedacaec8';
# 解密
cryptor = AES.new(key, AES.MODE_CBC, key);
decrypt_content = cryptor.decrypt(context);
return decrypt_content;
这里用的是pycryptodome库,安装方式如下:
pip3 install pycryptodome
关于密文,在m3u8文件里面已经有了,直接下载就可以拿到,这里我就不通过代码拿了:
这里下载视频会比较费时间,为了提高下效率可以用多线程,但是由于时间的关系就不演示了。
合并视频
合并视频就更简单了,就是讲前面我们保存的视频合并成一个完整的视频,合并完之后的格式是mp4。
def fileMerge(filePath):
# 查询出文件中的ts文件
c = os.listdir(filePath)
# 打开视频保存文件
with open('%s.mp4' % filePath, 'wb+') as f:
# 循环
for i in range(len(c)):
# 打开 ts 视频文件
x = open('{}/{}.ts'.format(filePath, str(i + 1)), 'rb').read()
f.write(x)
print('合并完成')
我看了下,短短的一集葫芦娃,总共被分割成272个ts文件(好像比这个多,我没下载完就把网断了 ):
):
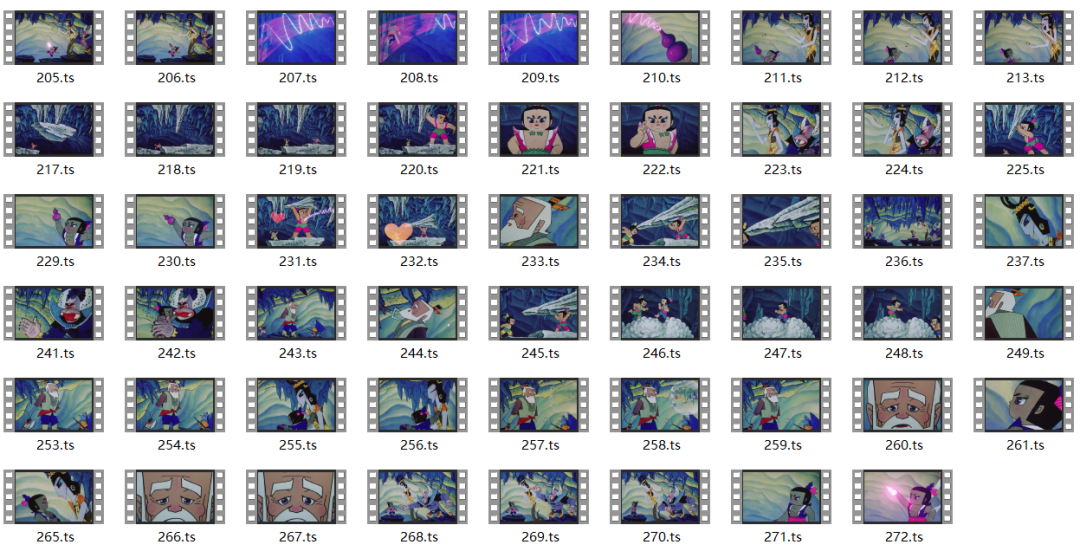
272个ts文件合并成一个视频文件:
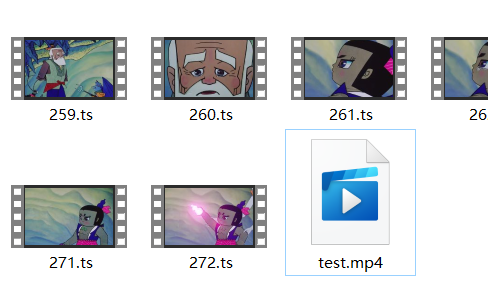
好了,到这里我们python爬取m3u8视频资源的实例就结束了,今天的示例还算比较完美,目标也比较完美的达成了。奈斯!
完整代码如下:
import requests
import os
from Crypto.Cipher import AES # 用于AES解码
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36'
}
def getTsFileUrlList(m3u8Url):
ts_rs = requests.get(url = m3u8Url, headers=headers).text
print(ts_rs)
list_content = ts_rs.split('\n');
print('list_content:{}'.format(list_content))
player_list = []
index = 1;
for line in list_content:
# 以下拼接方式可能会根据自己的需求进行改动
if '#EXTINF' in line:
continue;
elif line.endswith('.ts'):
player_list.append(line)
print('数据列表组装完成-size: {}'.format(len(player_list)));
return player_list;
def fileDownloadWithdecrypt(fileSavePath, player_list):
if not os.path.exists(fileSavePath):
os.mkdir(fileSavePath);
for index, url in enumerate(player_list):
ts_video = requests.get(url = url, headers=headers)
with open('{}/{}.ts'.format(fileSavePath, str(index + 1)), 'wb') as file:
context = decrypt(ts_video.content);
file.write(context)
print('正在写入第{}个文件'.format(index + 1))
print('下载完成');
def fileMerge(filePath):
c = os.listdir(filePath)
with open('%s.mp4' % filePath, 'wb+') as f:
for i in range(len(c)):
x = open('{}/{}.ts'.format(filePath, str(i + 1)), 'rb').read()
f.write(x)
print('合并完成')
def decrypt(context):
key = b'2cd1da2aedacaec8';
cryptor = AES.new(key, AES.MODE_CBC, key);
decrypt_content = cryptor.decrypt(context);
return decrypt_content;
if __name__ == '__main__':
m3u8Url = 'https://vod1.bdzybf1.com/20200819/wMgIH6RN/1000kb/hls/index.m3u8';
videoList = getTsFileUrlList(m3u8Url);
print(videoList)
savePath = "./test"
fileDownloadWithdecrypt(savePath, videoList);
fileMerge(savePath);
运行上面的代码,你就可以得到一集完整的葫芦娃
当然,如果你能找到资源,用上面这段代码爬取小电影也是可以的
总结
今天的视频爬虫很简单,可以说非常简单,核心技术点也不多,主要涉及如下几点:
request请求字符串解析(响应结果解析) 文件操作 ASE解密
只需要稍微有一点python基础,就可以做出来,所以这里我也没什么好总结的了。
最后,免费为python做一个无偿广告。我一直觉得python是一门不错的语言,特别是作为脚本使用的时候,真的是太方便了,今天它也依然没有让我失望。
其实严格来说,我学python,但是之前一直诟病于它的缩进语法,所以也就一直没入门,直到做了一段时间java web开发之后,回头再看下python,觉得好简单,于是就又愉快地使用它了,不过用它写脚本真的太爽了,短短几行代码,搞定java一个繁琐的项目,而且用起来也很轻便。
最近一年多的时间,我用它处理过数据、用它跑数据库统计过数据,然后日程工作中我可以用它生成文件目录、爬取资料,也感觉我对它越来越有好感,所以在这里强烈安利各位小伙伴都来学下python,特别是那些非开发岗位的小伙伴,python简直是统计数据的利器,虽然不像广告吹的那么秀,但是技多不压身呀,而且它真的是可以极大提供我们的效率。
最后的最后,再强调下,技术无罪,切勿用技术搞违法犯罪的事,不然日子真的就越来越有判头了!
技术无罪,切勿用技术搞违法犯罪的事,不然日子真的就越来越有判头了!
技术无罪,切勿用技术搞违法犯罪的事,不然日子真的就越来越有判头了!
重要的事情说三遍!!!
另外,今天忙着搞爬虫了,设计模式的类图还没来得及补,明天要加下油了。好了,铁子们,晚安吧
参考内容
[1] https://zhuanlan.zhihu.com/p/346683119
[2] https://www.cnblogs.com/shakin/p/3870439.html