
GitHub项目推荐|基于强化学习的自动化剪枝模型

极市导读
GitHub上最新开源的一个基于强化学习的自动化剪枝模型,本模型在图像识别的实验证明了能够有效减少计算量,同时还能提高模型的精度。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
今天为大家介绍一个GitHub上最新开源的一个基于强化学习的自动化剪枝模型,本模型在图像识别的实验证明了能够有效减少计算量,同时还能提高模型的精度。
项目地址:
https://github.com/freefuiiismyname/cv-automatic-pruning-transformer
介绍
目前的强化学习工作很多集中在利用外部环境的反馈训练agent,忽略了模型本身就是一种能够获得反馈的环境。本项目的核心思想是:将模型视为环境,构建附生于模型的 agent ,以辅助模型进一步拟合真实样本。
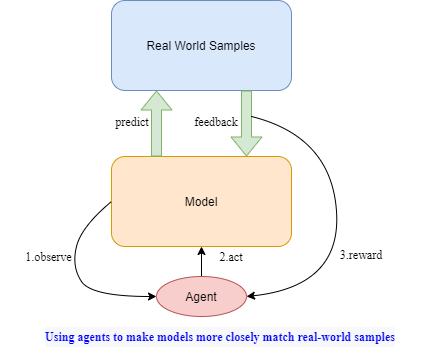
大多数领域的模型都可以采用这种方式来优化,如cv/多模态等。它至少能够以三种方式工作:
1.过滤噪音信息,如删减语音或图像特征;
2.进一步丰富表征信息,如高效引用外部信息;
3.实现记忆、联想、推理等复杂工作,如构建重要信息的记忆池。
这里推出一款早期完成的裁剪机制transformer版本(后面称为APT),实现了一种更高效的训练模式,能够优化模型指标;此外,可以使用动态图丢弃大量的不必要单元,在指标基本不变的情况下,大幅降低计算量。
该项目希望为大家抛砖引玉。

为什么要做自动剪枝
在具体任务中,往往存在大量毫无价值的信息和过渡性信息,有时不但对任务无益,还会成为噪声。比如:表述会存在冗余/无关片段以及过渡性信息;动物图像识别中,有时候背景无益于辨别动物主体,即使是动物部分图像,也仅有小部分是关键的特征。

以transformer为例,在进行self-attention计算时其复杂度与序列长度平方成正比。长度为10,复杂度为100;长度为9,复杂度为81。
利用强化学习构建agent,能够精准且自动化地动态裁剪已丧失意义部分,甚至能将长序列信息压缩到50-100之内(实验中有从500+的序列长度压缩到个位数的示例),以大幅减少计算量。
实验中,发现与裁剪agent联合训练的模型比普通方法训练的模型效果要更好。
模型介绍及实验
模型主体
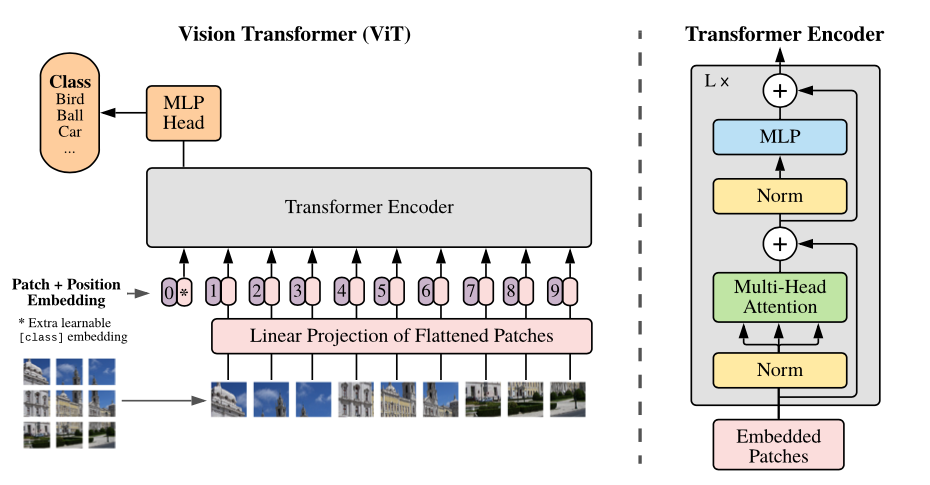
基于transformer的视觉预训练模型ViT是本项目的模型主体,具体细节可以查看论文:《An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale》
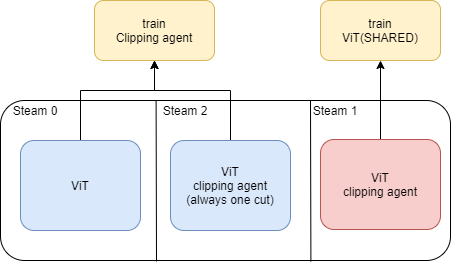
自动化裁剪的智能体
对于强化学习agent来说,最关键的问题之一是如何衡量动作带来的反馈。为了评估单次动作所带来的影响,使用了以下三步骤:
1、使用一个普通模型(无裁剪模块)进行预测;
2、使用一个带裁剪器的模型(执行一次裁剪动作)进行预测;
3、对比两次预测的结果,若裁剪后损失相对更小,则说明该裁剪动作帮助了模型进一步拟合真实状况,应该得到奖励;反之,应该受到惩罚。
但是在实际预测过程中,模型是同时裁剪多个单元的,这或将因为多个裁剪的连锁反应而导致模型失效。训练过程中需要构建一个带裁剪器的模型(可执行多次裁剪动作),以减小该问题所带来的影响。
综上,本模型使用的是三通道模式进行训练。
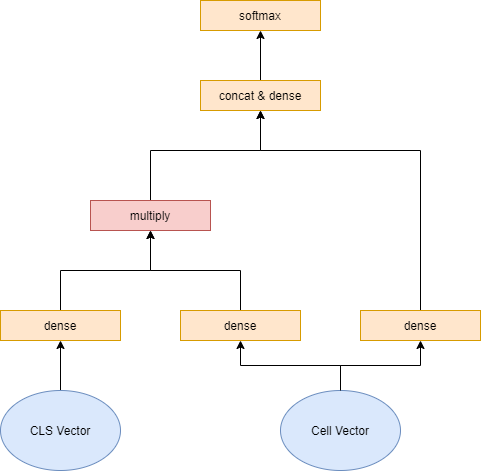
关于裁剪器的模型结构设计,本模型中认为如何衡量一个信息单元是否对模型有意义,建立于其自身的信息及它与任务的相关性上。
因此以信息单元本身及它与CLS单元的交互作为agent的输入信息。
实验
数据集 | ViT | APT(pruning) | APT(no pruning) |
CIFAR-100 | 92.3 | 92.6 | 93.03 |
CIFAR-10 | 99.08 | 98.93 | 98.92 |
以上加载的均为ViT-B_16,resolution为224*224。
使用说明
环境

下载经过预先训练的模型(来自Google官方)
本项目使用的型号:ViT-B_16(您也可以选择其它型号进行测试)

训练与推理
下载好预训练模型就可以跑了。

CIFAR-10和CIFAR-100会自动下载和培训。如果使用其他数据集,您需要自定义data_utils.py。
在裁剪模式的推理过程中,预期您将看到如下格式的输出。

默认的batch size为72、gradient_accumulation_steps为3。当GPU内存不足时,您可以通过它们来进行训练。
注:相较于原始的ViT,APT(Automatic pruning transformer)的训练步数、训练耗时都会上升。原因是使用pruning agent的模型由于总会丢失部分信息,使得收敛速度变慢,同时为了训练pruning agent,也需要多次的观测、行动、反馈。
致谢
感谢基于pytorch的图像分类项目(https://github.com/jeonsworld/ViT-pytorch),本项目是在此基础上做的研发。
最后再附上一次项目地址,欢迎感兴趣的读者Star✨
https://github.com/freefuiiismyname/cv-automatic-pruning-transformer
如果觉得有用,就请分享到朋友圈吧!
公众号后台回复“目标检测竞赛”获取目标检测竞赛经验资源~

# CV技术社群邀请函 #
备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~
