
MosaicML Composer 炼丹技巧14条
GiantPandaCV 导语:本文的主要内容是介绍 MosaicML Composer 库中包含的一些炼丹调优技巧
Github 链接:https://github.com/mosaicml/composer
一、ALiBi (Attention with Linear Biases)
参考文献:Train Short, Test Long: Attention with Linear Biases Enables Input Length Extrapolation, https://arxiv.org/abs/2108.12409
核心思想
对于 transformer 模型还有一个开放性的问题仍然未解决(how to achieve extrapolation at inference time),也就是如果遇到推理阶段的序列长度,长于训练阶段的序列长度的时候该如何处理。
论文中提出了一种尝试解决该问题的方法,首先去掉 transformer 输入的位置编码,接着在计算 self-attention 的时候,给计算出来的 qk attension 分数加上一个偏置项,偏置项的大小正比于 q 和 k 的距离。
论文在一个 13 亿参数量的模型上做了实验,使用 ALiBi 方法,在训练阶段序列长度是 1024 推理阶段增加到 2048,和训练与预测阶段序列长度都是 2048 且用了位置编码的设置相比,具有同样的 perplexity 指标,且速度上快 11% 同时也能节省 11% 的内存。
方法介绍
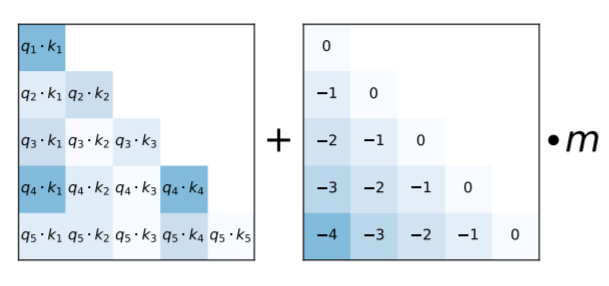
上图中左边是计算出来的其中一个 Head 的 qk attention 分数矩阵,右边是一个常量矩阵,矩阵中每个位置的值对应 qk 对在序列中的距离,距离越远值越小,然后该矩阵再乘以一个 m 常量,该常量与 Head 相关,其计算公式如下:
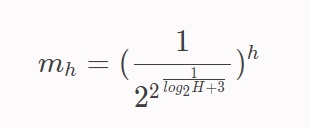
H 表示 multi-head attention 层中 Head 的个数,h 则表示 Head 的索引。
实验结果
实验设置:
采用 GPT2 模型在 OpenWebText 数据集上做实验。GPT2-52m baseline 表示训练序列长度 1024 且输入加上可学习的位置编码,GPT2-52m ALiBi 0.25x 则表示去除输入位置编码且qk attention 加上偏置的方式, 0.25x 表示训练序列长度 256 推理阶段序列长度 1024。
实验结果如下表所示:
| Name | Perplexity | Perplexity Difference | Wall Clock Train Time (s) | Train Time (ALiBi/Baseline) | GPU Memory Allocated (%) | GPU Allocated (ALiBi/Baseline) |
|---|---|---|---|---|---|---|
| GPT2-52m baseline | 30.779±0.06 | 9801±1 | 92.91 | |||
| GPT2-52m ALiBi 0.25x | 30.542±0.03 | 0.24 | 8411±5 | 0.86 | 79.92 | 0.86 |
| GPT2-83m baseline | 26.569 | 17412 | 97.04 | |||
| GPT2-83m ALiBi 0.25x | 26.19±0.02 | 0.38 | 14733±3 | 0.85 | 80.97 | 0.83 |
| GPT2-125m baseline | 24.114 | 30176 | 95.96 | |||
| GPT2-125m ALiBi 0.25x | 23.487 | 0.63 | 25280 | 0.84 | 74.83 | 0.78 |
从实验结果表明,采用 AliBi 方法可以获得更低的 Perplexity 指标,且训练阶段耗时和内存占用都更低。不过实验中也观察到一个现象就是当训练阶段序列长度小于 128 的时候,推理阶段拓展到更长的序列,AliBi 方法的性能下降严重。所以建议采用 AliBi 方法训练模型的时候,训练序列长度应大于 256 或者训练阶段序列长度应该不小于推理阶段序列长度的 0.03125 倍。
二、AugMix
参考文献:AugMix: A Simple Data Processing Method to Improve Robustness and Uncertainty,https://arxiv.org/abs/1912.02781
核心思想
目前基于深度神经网络的图像分类模型普遍都具有的问题是,当训练和测试集是独立同分布的情况下,模型在测试集上的精确度会很高反之则很低,而在实际场景中训练和测试集独立同分布的概率非常低。
目前已有的一些技术旨在,提升模型鲁棒性和改善在部署的时候可能遇到的数据分布不同的问题。而在该论文中提出了 AugMix 数据预处理方法,实验结果表明该方法能很大程度提升图像分类模型的鲁棒性。
方法介绍
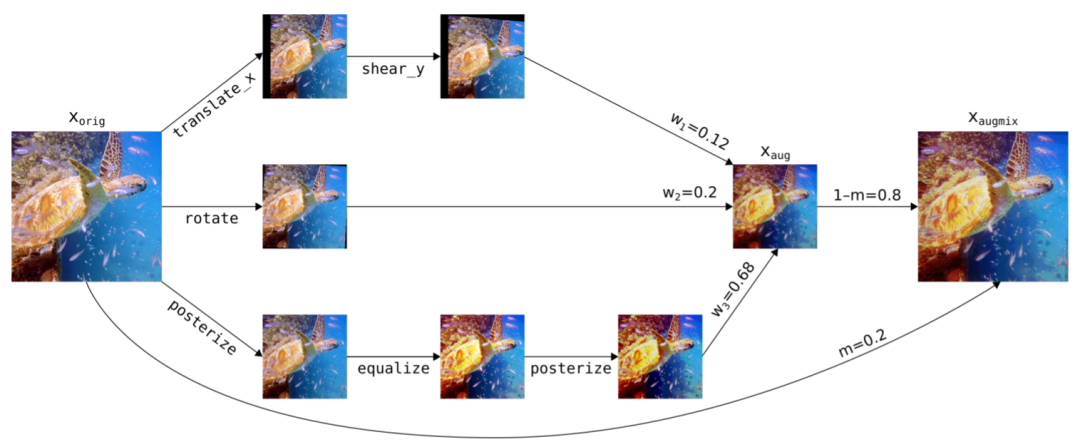
上图就是 AugMix 数据预处理的流程示意图。
简单来说 AugMix 方法流程如下,总体会做 k 次并行的串联 data augmentation,比如上图中 k=3。
所谓串联的 data augmentation 就是首先有一个 data augmentation 的操作候选集合(translate_x, translate_y, shear_x, shear_y, rotate, solarize, equalize, posterize, autocontrast, color, brightness, contrast, sharpness 等)。
每次串联 augmentation 会从中随机采样一个组合,比如上图中第一个串联就是 translate + shear。接着按顺序以随机强度应用 augmentation 的到前一个 augmentaion 的结果图片上。
做完 k 次串联操作之后,接着从迪利克雷分布采样出 k 个权值 w,它们之和为1。然后将并行的 k 个串联 data augmentation 的结果加权求和得到图中的 Xaug 。最后再和原始图片 Xorg 再做一次加权求和得到 AugMix 的输出(权值 m 从貝塔分布中采样得到)。
三、BlurPool
参考文献:Making Convolutional Networks Shift-Invariant Again,https://proceedings.mlr.press/v97/zhang19a.html
官方代码:https://github.com/adobe/antialiased-cnns
核心思想
目前深度卷积神经网络普遍存在一个问题,就是当对输入做轻微的平移的时候,网络的输出相对于原输入的输出会有非常大的变动。网络中常用的比如最大池化、平均池化和带步长的卷积等常用的下采样方法,是导致这个问题的主要原因。
在信号处理领域,通常采用抗锯齿(anti-aliasing)来处理下采样可能带来的问题,简单来说就是在下采样之前应用低通滤波。
但是对于深度神经网络又不能随便加这个模块,很容易会导致性能下降,所以应用的很少。而这篇文章的贡献点就在于发现了在哪些位置适合插入这个低通滤波,能够很好和和目前的架构融合到一起,比如最大池化和带步长卷积。
同时实验结果表明对于常用的网络比如 ResNet、DenseNet 和 MobileNet 应用了这个技术之后,在 ImageNet 分类任务上的性能都有了提升,同时网络的泛化能力和鲁棒性都有了改善。
方法介绍
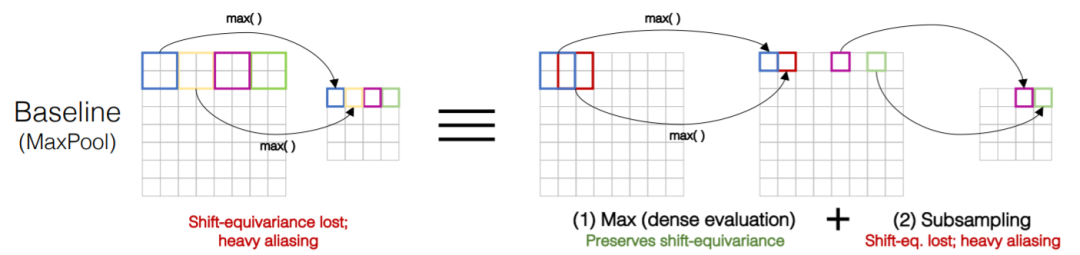
上图展示的是原始的 MaxPool 操作 ,可以看出来 MaxPool 不具有平移不变性(当输入有偏移结果可能和之前有很大的不同)。而原始的 MaxPool 可以等价于右边的操作,首先是步长为1的 MaxPool 然后再接一个下采样操作。
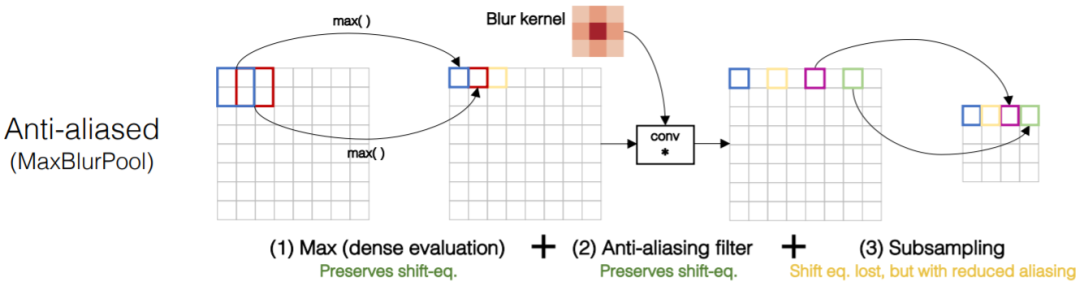
上图是论文中提出的看锯齿 MaxBlurPool,首先是一个步长为1的 MaxPool,然后接一个高斯滤波,然后再接一个下采样。官方代码实现是将后两步骤合并为一个 BlurPool (https://github.com/adobe/antialiased-cnns/blob/master/antialiased_cnns/blurpool.py) 操作,就是一个步长为 2 的 depthwise 卷积,手动初始化卷积核为高斯核。

上图展示了网络中原始的下采样模块如何被替换为抗锯齿的版本。
详细分析
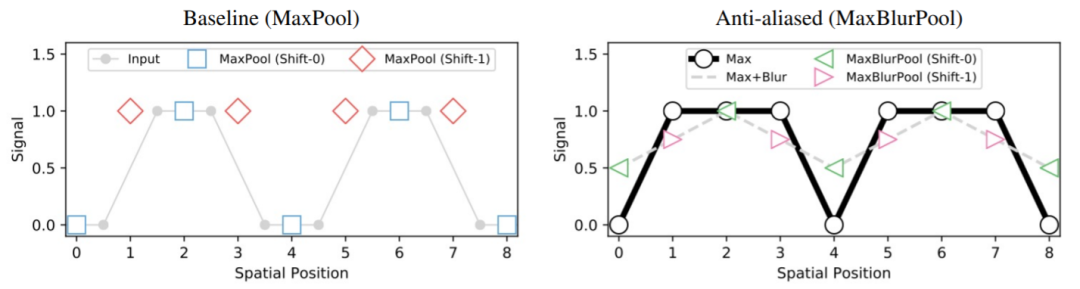
论文中举了一个简单信号处理的例子来分析为何 MaxBlurPool 会优于 MaxPool。
比如对于一个一维信号 [0, 0, 1, 1, 0, 0, 1, 1], 看到上图中左边的哪幅图表,图中灰色的8原点就对应着输入,接着对输入应用一个 kernel=2, stride=2 的 MaxPool ,就得到蓝色方框的结果 [0, 1, 0, 1],这时候如果对输入进行向右循环移1位,就得到新的输入 [1, 0, 0, 1, 1, 0, 0, 1],这时候 maxpool 的结果就对应图中的红色菱形 [1, 1, 1, 1]。
而之前分析可知,原始的 maxpool 操作等价于步长为 1 的 maxpool + 下采样操作,步长为 1 的 maxpool 具有平移相似的性质,但是下采样则破坏了这个性质。上图右边的图表中,黑色空心圆点就代表原始信号 [0, 0, 1, 1, 0, 0, 1, 1] 做步长为 1 的 maxpool 之后的结果 [0, 1, 1, 1, 0, 1, 1, 1]。
右图中灰色虚线表示 步长为 1 的 maxpool + 高斯滤波的结果,可以看到曲线相对于黑色实线更平滑了,而绿色和粉红色三角则表示对原始信号应用 MaxBlurPool 和 将输入信号进行向右循环移1位之后再做 MaxBlurPool 的结果,分别是 [0.5, 1, 0.5, 1] 和 [0.75, 0.75, 0.75, 0.75] 两个结果相对于原始 MaxPool 更加的接近。
四、Channels Last (NHWC Data Format)
参考文献:
Volta Tensor Core GPU Achieves New AI Performance Milestones,https://developer.nvidia.com/blog/tensor-core-ai-performance-milestones/
Inside Volta: The World’s Most Advanced Data Center GPU,https://developer.nvidia.com/blog/inside-volta/
核心思想
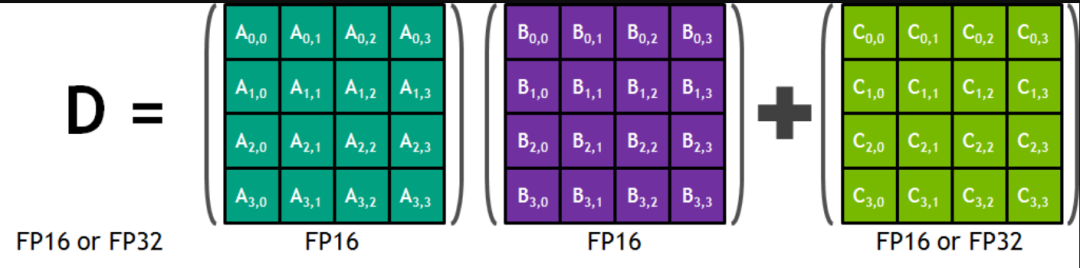
Tensor Core 是一种新型处理核心,适用于深度学习和某些类型的高性能计算任务。Tesla V100 GPU 包含 640 个 Tensor Cores, 每个 SM 包含8个。每个 Tensor Core 在每个时钟周期都能进行一次 4x4x4 矩阵乘法操作。如上图所示,A,B,C和 D 都是 4x4 矩阵。A和B都是 fp16 类型,累加结果 D 可能是 fp16 或者 fp32。
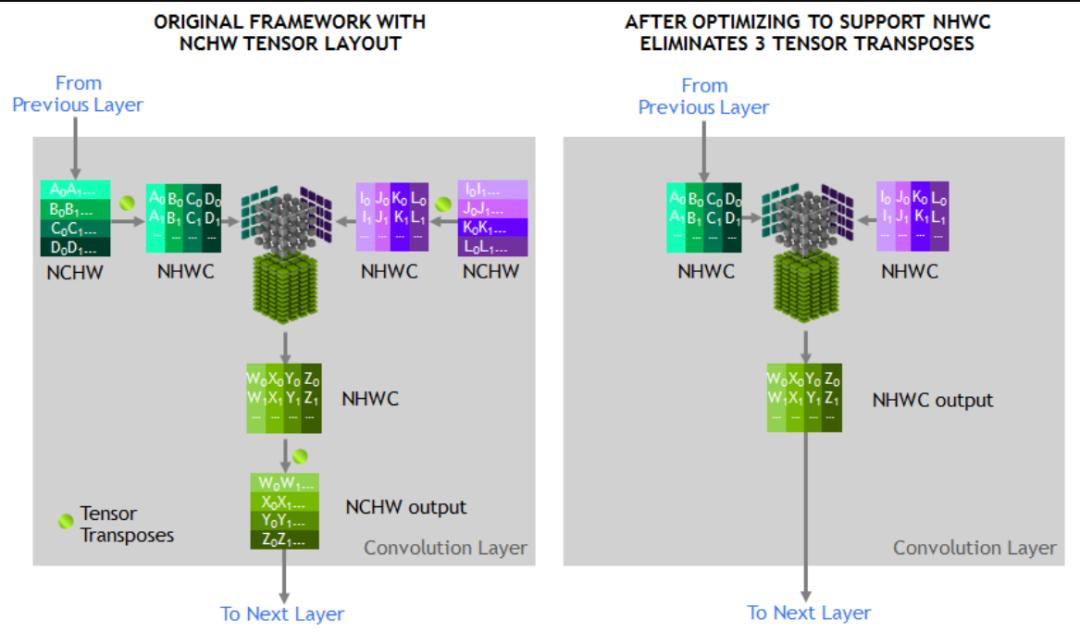
对于支持 Tensor Core 的显卡,在启用了 fp16 之后, cuDNN 会自动启用 Tensor Core 加速计算速度,但是数据格式必须是 NHWC 格式,否则首先会做次 transpose 操作转为 HNWC 计算完成之后再转回原始格式,如上图所示。所以这个transpose也会带来额外的开销,而如果网络一开始就是 NHWC 格式则可以省略掉这些格式转换的开销。
五、Cutout
参考文献:Improved Regularization of Convolutional Neural Networks with Cutout,https://arxiv.org/abs/1708.04552
官方代码:https://github.com/uoguelph-mlrg/Cutout
核心思想
针对卷积神经网络容易出现的过拟合问题,这篇论文中提出了一种 data augmentation 方法 Cutout,能够有效提升模型的分类性能和泛化能力。Cutout 其实是受视觉任务(检测,跟踪,人体姿态估计等)中常见的物体遮挡问题所启发,通过人为生成被遮挡的图片,让模型在学习分类的时候更加关注图片中的上下文信息。Cutout 不仅很容易实现而且也可以很好的和其他 data augmentation 方法结合来提升模型的性能,在数据集 CIFAR10, CIFAR-100 和 SVHN 上都刷新了测试集的指标。
方法介绍

Cutout 实现很简单,就是对于输入图片随机选择图中一个火多个矩形区域,将该区域内的像素值替换为整个数据集的像素均值,或者直接替换为0。而且如果对整个 batch 的同一个区域应用 Cutout 则更加的高效,可以充分利用GPU。
六、Label Smoothing
参考文献:
Rethinking the Inception Architecture for Computer Vision,https://arxiv.org/abs/1512.00567
When Does Label Smoothing Help?,https://arxiv.org/abs/1906.02629
方法介绍
将原始的分类 target (也就是label) 修改为 ,原来是1 的改为 1 - alpha,原来是 0 的改为 alpha / (K-1) 其中 K 为类别数, alpha 通常取 0.1 。
七、MixUp
参考文献:mixup: Beyond Empirical Risk Minimization,https://arxiv.org/abs/1710.09412
核心思想
大型的深度神经网络学习能力很强,但是往往存在容易过拟合还有容易受对抗样本的干扰。该论文提出了一个 data augmentaion 方法 MixUp 来改善整个问题。简单来说 MixUp 就是将一对样本以及它们的进行加权融合。实验结果表明在 ImageNet-2012, CIFAR-10, CIFAR-100, Google commands 和 UCI 数据集上, MixUp 都能提高目前最新模型的泛化能力,同时能更好的防御对抗样本。
方法介绍

上图展示了鸟和青蛙图片融合的样例。
MixUp 计算过程很简单,首先从数据集中采样一对样本 (Xi, Xj),它们的标签为 (Yi, Yj),接着从 Beta 分布采样一个权值 lambda 范围 [0, 1],新的图片和标签的计算公式为:
Xnew = lambda * Xi + (1 - lambda) * Xj
Ynew = lambda * Yi + (1 - lambda) * Yj
八、Ghost BatchNorm
参考文献:
Train longer, generalize better: closing the generalization gap in large batch training of neural networks,https://arxiv.org/abs/1705.08741
A New Look at Ghost Normalization,https://arxiv.org/abs/2007.08554
核心思想
深度学习模型一般都是采用随机梯度下降法或其变种来训练,这些方法都是根据从一小批训练数据中得到的梯度来更新权值。而之前的实验观察到一个现象就是,当采用大 batch size 来训练模型的时候,模型的泛化能力会下降,这个现象被称为 generalization gap ,如何缩小这个 gap 这个仍然是开放性的问题。
该论文针对大 batch size 这个问题提出了 BatchNorm 的改进版本 GhostBatchNorm。该方法能够不需要通过增加训练迭代次数也能缩小这个 generalization gap。
方法介绍
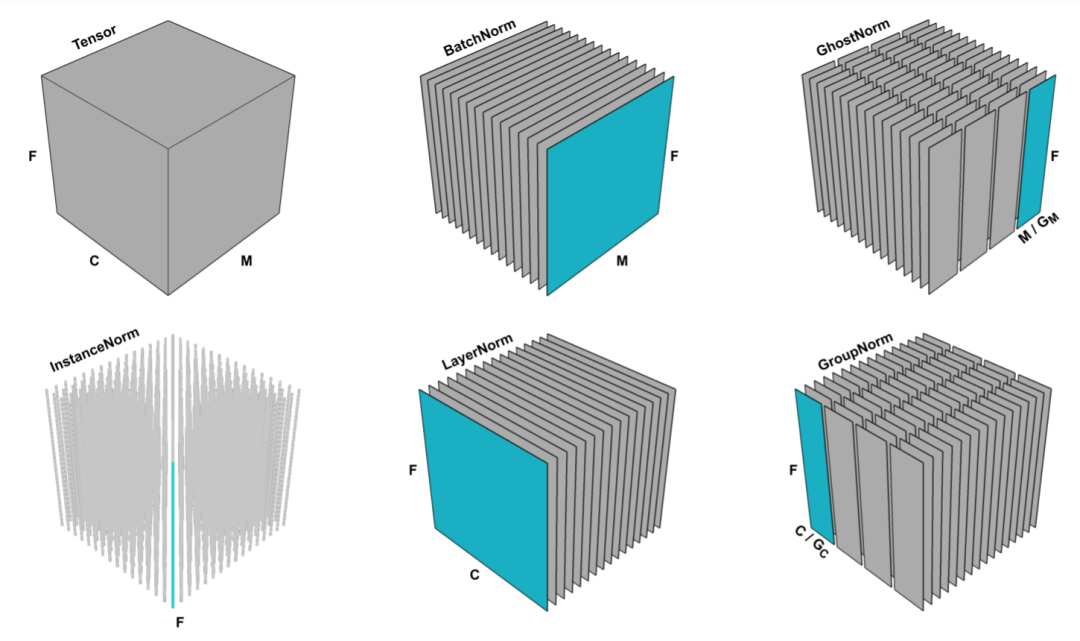
上图展示了 GhostNorm, BatchNorm, InstanceNorm, LayerNorm 和 GroupNorm 的区别,图中字母分别代表:F 表示特征空间维度大小如果是二维图像则是 F=N*W,C 表示通道数,M 表示 batch 维度,GM 表示 GhostNorm 方法中 batch 维度上的分组大小,GC 表示 GroupNorm 方法中通道上的分组大小。
GhostBatchNorm 方法简单来说就是对一个大的 batch 的输入,在 batch 维度上进行分组每组内独立计算 BatchNorm 。

上图展示了 GhostBatchNorm 的算法流程,首先对于一个大 batch_size=BL,设定每组 batch_size=BS,然后就得到 l 组,每组内单独计算 BatchNorm,接着将每个组内计算得到的 mean 和 var 都通过一个公式加权求和累加到统计量 running_mean 和 running_var 上,不过我觉得上面公式中搞错了,加权不同分组内的均值和方差求和下表应该是 l 而不是 i。还有最后推理阶段的公式 running_mean 多了个上标 l。
实际实验结果
原论文中说应用了 GhostBatchNorm 方法在小规模数据集上会带来 0-3% 的性能提升。但是实际实验结果表明,在 ImageNet 数据集上用 ResNet50 做实验会观察到 Top-1 精确度会在 -0.3% - +0.3% 区间内波动,同时吞吐率会下降 5% 左右。
九、Progressive Image Resizing
参考文献:Training a State-of-the-Art Model,https://github.com/fastai/fastbook/blob/780b76bef3127ce5b64f8230fce60e915a7e0735/07_sizing_and_tta.ipynb
方法介绍
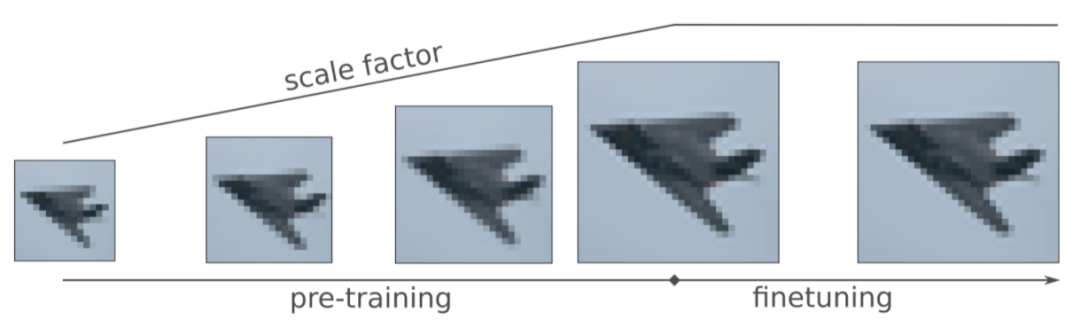
该方法简单来说就是训练初始阶段,将图片以一定比例缩小,然后随着训练的进行,逐渐增大图片大小到训练后期恢复到原始大小。该方法在训练初期能有效降低所需资源,同时网络也能同时学到粗粒度和细粒度的特征。不过该方法只适用于能够适应不同输入大小的网络模型。
在 ImageNet 上用 ResNet 系列实验结果表明,该方法能提升训练速度的同时不会对验证集精度有大的影响。
实现细节
对于缩小图片的方式有两种:
crop通过从原始图片中裁剪出目标大小的一个区域,这种方法适用于哪些对于图像中物体尺度大小很重要的数据集,比如 Cifar-10,图像的分辨率分来就很小了。
resize通过双线性下采样原图的方式来得到目标大小,这种方法适合那种包含多种不同尺度大小物体的数据集,图像中的内容全部都需要可见,又或者原始图像的分辨率高。比如在 ImageNet 数据集上 resnet50 采用这种方法就比较好。
十、RandAugment
参考文献:Randaugment: Practical Automated Data Augmentation With a Reduced Search Space,https://openaccess.thecvf.com/content_CVPRW_2020/html/w40/Cubuk_Randaugment_Practical_Automated_Data_Augmentation_With_a_Reduced_Search_Space_CVPRW_2020_paper.html
核心思想
最近又不少关于自动 data augmentation 的工作,在图像分类和物体检测任务上都获得了刷新了指标。但是这些方法由于策略搜索的开销比较大所以应该用并不广泛。
这边文章提出了 RandAugment 方法,该方法不仅简单,而且在 CIFAR-10/100, SVHN, ImageNet 和 COCO 等数据集上都能获得和自动 augmentation 等方法差不多的精度。
方法介绍

上图展示的是 RandAugment 对原始图片的处理过程,对于每一张原始图片,首先从一个 augmentations 集合(translate_x, translate_y, shear_x, shear_y, rotate, solarize, posterize, equalize, autocontrast, color, contrast, brightness, sharpness)中采样 depth 个操作。接着按顺序以一定的强度(从正态分布采样)应用这些操作。RandAugment 通常是放在图片缩放和裁剪操作之后,而在 normalization 操作之前。
示例代码:

实验结果

上图展示的是 ImageNet 上的分类精度对比结果,Fast AA 和 AA 都表示自动 data augmentation 的方法,RA则是 RandAugment ,可以看到 RA 能获得和 AA 方法同等甚至更优的精度。
十一、Selective Backprop
参考文献:Accelerating Deep Learning by Focusing on the Biggest Losers,https://arxiv.org/abs/1910.00762
核心思想
该论文提出了 Selective-Backprop,是一种加速训练深度神经网络的技术。该方法在每次迭代反向回传的时候,会有很大概率选择哪些 loss 高的样本回传,而那些 loss 低的样本有大概率会跳过,这样能加速训练的同时也不会怎么影响模型的泛化性。
实现细节

上图展示的是 Selective-Backprop 在 CIFAR10 训练过程中选择或扔掉的样本,左边就是选择频率很低的样本,右边则是选择频率很高的样本。
Selective-Backprop 算法流程:

实验结果
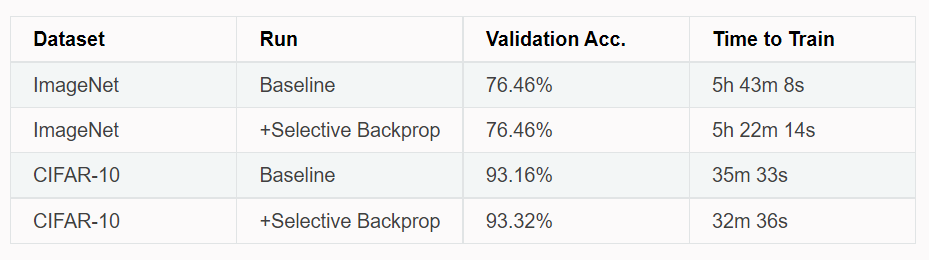
但是从实验结果上看,提速也没多少。
其实个人感觉 Selective-Backprop 很像 hard-negative mining 那类方法,一开始网络基本所以样本都是难的,而随着训练的进行,模型很快就学会识别简单样本了,这时候通过一个阈值过滤掉简单样本,因为这些样本loss很小,对梯度的贡献也很小可以忽略,从而让网络关注于那些更难得样本上。当然这个方法着重点在于加速训练。
十二、Squeeze-and-Excitation
参考文献:Squeeze-and-Excitation Networks,https://arxiv.org/abs/1709.01507
官方代码:https://github.com/hujie-frank/SENet
方法介绍
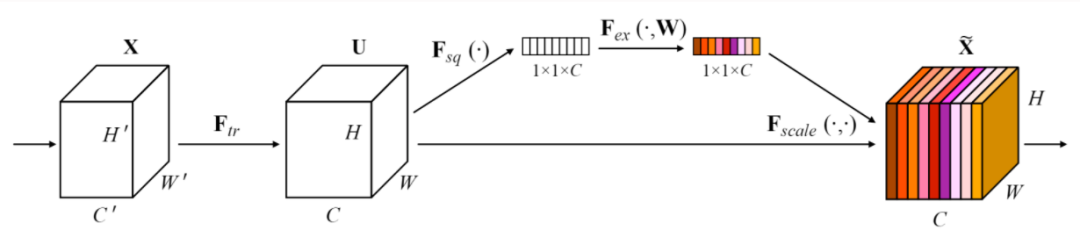
Squeeze-and-Excitation 本质就是在原来网络结构中插入了一个通道级别的注意力操作,每个通道的注意力系数通过一个可训练的 MLP 来生成。
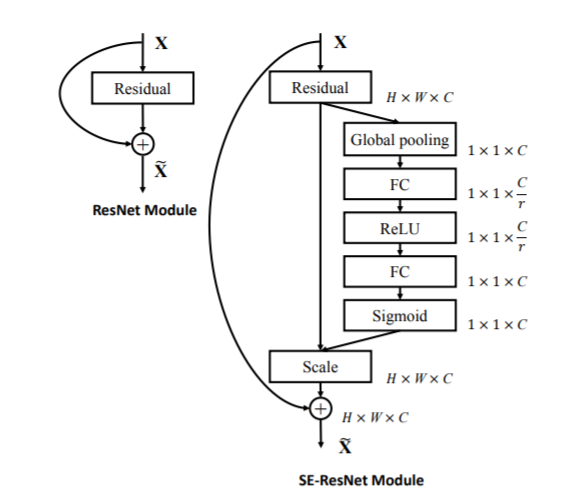
上图展示的是如何在残差模块中加入 SE 模块。
十三、Stochastic Weight Averaging
参考文献:Averaging Weights Leads to Wider Optima and Better Generalization,https://arxiv.org/abs/1803.05407
官方代码:https://github.com/timgaripov/swa
方法介绍
这个方法简单来说就是,会初始化两份一样的网络,在训练的时候只训练其中一个网络,然后在每个epoch结束的时候将训练网络的权值通过移动平均加权的方式累加到不训练网路的权值上。而不训练网络的bn的 running_mean 和 running_var 则是最后训练完成之后,过一遍训练集得到。
实验结果
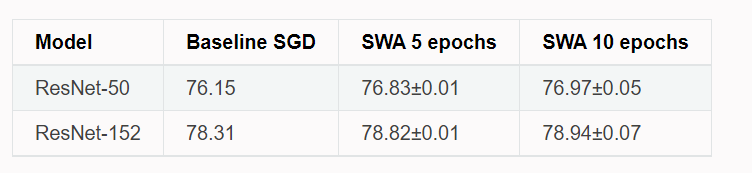
十四、Sequence Length Warmup
参考文献:Curriculum Learning: A Regularization Method for Efficient and Stable Billion-Scale GPT Model Pre-Training,https://arxiv.org/abs/2108.06084
核心思想
近年来大型的自回归语言模型(GPT,GPT-2,GPT-3)虽然在文本生成上可以取得很好的生成效果,但是普遍会遇到训练平稳性的问题。在 GPT-2 (117M and 1.5B parameters)模型上的实验结果表明,当增大模型大小,训练的序列长度,batch size 和 学习率的时候,训练的平稳性就越差。为了避免这个问题,一般会采用小的batch size和学习率,但是又会导致训练效率很低,需要更长的训练时间。
针对这个问题,该论文提出了基于课程学习的方法 Sequence Length Warmup,该方法可以改善自回归语言模型的预训练收敛速度。实验结果表明,采用课程学习的设置可以在训练 GPT-2 的时候采用更大的 batch size (可以比原来大 8 倍)和更大的学习率(比原来大 4倍)。
方法介绍
这个方法简单来说就是,类似上面提到的图像分类任务中的 Progressive Image Resizing,不过这里是初始训练从一个小的序列长度开始,随着训练迭代的进行,逐渐增加序列长度最后到最大的长度。Sequence Length Warmup 通常都能够减少 1.5 倍的训练时间同时能够达到和 baseline 差不多的 loss 级别。
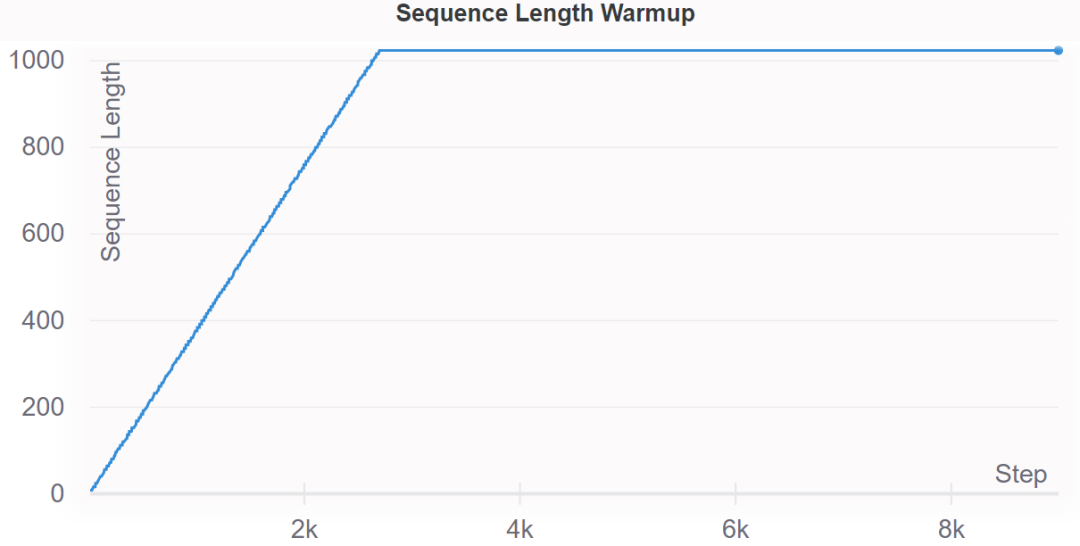
实现细节
对于 warmup 过程中如何生成指定长度序列,有两种方式:
直接截断句子到指定长度
比如序列长度设置为 8,原始 batch size 为 2:
We choose to go to the moon. We choose to go to the moon in this decade and do the other things, not because they are easy, but because they are hard, because that goal will serve to organize and measure the best of our energies and skills.
It is for these reasons that I regard the decision last year to shift our efforts in space from low to high gear as among the most important decisions that will be made during my incumbency in the office of the Presidency.则会被截断为:
We choose to go to the moon.
It is for these reasons that I regard如果句子长于指定长度,则将超过长度的部分截取出来拼接到 batch 维度上
比如序列长度设置为 8,原始 batch size 为 2:
We choose to go to the moon. We choose to go to the moon in this decade and do the other things, not because they are easy, but because they are hard, because that goal will serve to organize and measure the best of our energies and skills, because that challenge
It is for these reasons that I regard the decision last year to shift our efforts in space from low to high gear as among the most important decisions that will be made during my incumbency in the office of the Presidency.则会变成 batch size 14:
We choose to go to the moon.
We choose to go to the moon in
this decade and do the other things
not because they are easy, but because
they are hard, because that goal will
serve to organize and measure the best of
our energies and skills, because that challenge
It is for these reasons that I regard
the decision last year to shift our efforts
in space from low to high gear as
among the most important decisions that will be
made during my incumbency in the office
of the Presidency. In the last 24
hours we have seen facilities now being created
避免潜在的 Out-Of-Memory 错误
因为序列长度是逐渐增大的,所以框架比如 Pytorch 可能会不断的扩展其内存。所以一个方法是一开始就按照最大的序列长度来申请显存,但是把大于 warmup 序列长度的部分的梯度置0。