
实践教程 | Evo-ViT:高性能Transformer加速方法

作者 | 沁园夏@知乎(已授权)
来源 | https://zhuanlan.zhihu.com/p/397939585
编辑 | 极市平台
极市导读
本文提出了一种新式的Transformer加速算法:Evo-ViT: Slow-Fast Token Evolution for Dynamic Vision Transformer,该算法能够在保证分类准确率损失较小的情况下,大幅提升Transformer的推理速度。 >>加入极市CV技术交流群,走在计算机视觉的最前沿

论文地址:
https://link.zhihu.com/?target=https%3A//arxiv.org/abs/2108.01390
前言
Transformer基础网络的高效性设计问题随着Transformer在计算机视觉领域的蓬勃发展逐渐受到国内外众多学术机构和企业的关注。本文提出了一种新式的Transformer加速算法:Evo-ViT: Slow-Fast Token Evolution for Dynamic Vision Transformer,该算法能够在保证分类准确率损失较小的情况下,大幅提升Transformer的推理速度,如在ImageNet 1K数据集下,Evo-ViT可以提升DeiT-S 60%推理速度的同时仅仅损失0.4%的精度。
研究意义与背景
最近,Vision Transformer 及其变体在各种计算机视觉任务中显示出巨大的潜力。通过自注意力机制捕获短程和长程视觉依赖的能力是其成功的主要来源。但是长程感受野同样带来了巨大的计算开销,特别是对于高分辨率视觉任务(例如,目标检测、分割)。研究者们开始研究如何在尽量保持原有模型准确率的前提下,降低模型计算复杂度,从而使得视觉 Transformer成为一种更加通用、高效、低廉的解决框架。
目前,主流的Transformer高效设计方案包括两种:一种是借助结构化的空间先验,如PiT[2],LeViT[6]等利用空间下采样构造金字塔型模型,再例如PVT[1],Swin Transformer[9]等利用图像局部先验构造稀疏化的自注意力模块;另一种是进行非结构化的网络裁剪,例如DynamicViT[3]、PS-ViT[4],基于预训练好的模型,分析该模型的冗余性,对模型进行空间token或者特征通道的裁剪。然而,非结构化的裁剪会破化模型内部特征的空间结构,使得这两种方法无法相辅相成。
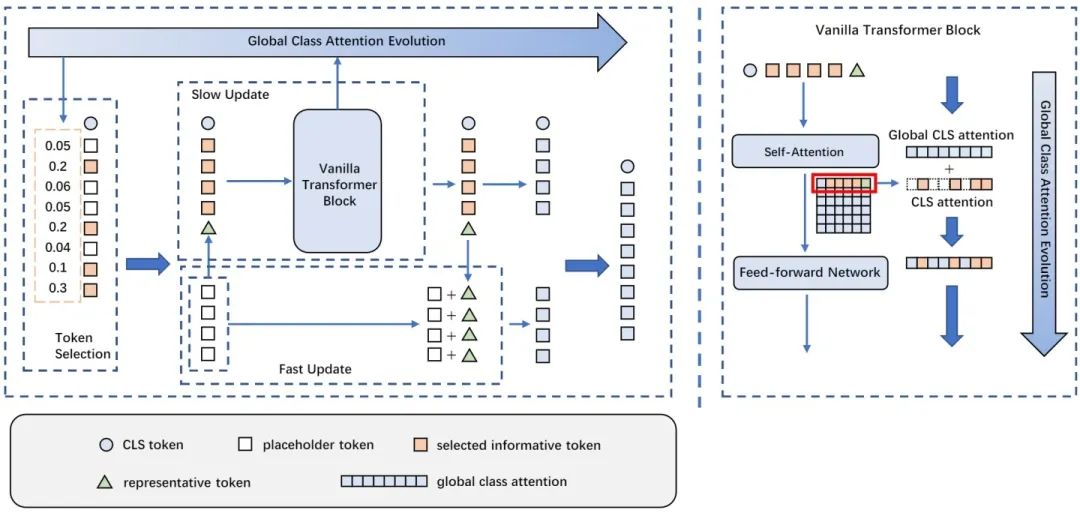
如图1第三个分支,相比直接将信息量低的token裁剪掉,此次工作中提出一种新的即插即用的token双流更新策略,能在模型训练的同时动态判断非结构性的token冗余及低信息分布,从而高效更新低信息token、精细更新高信息token,实现模型的高效准确建模,并保留了完整的空间结构。因此,该工作所提出的Evo-ViT方法可以同时适用于直筒型和金字塔型Transformer结构。
技术创新
与现有的Transformer高效设计方案相比,Evo-ViT是即插即用的加速策略,既适用于直筒型结构,也适用于金字塔型结构的视觉Transformer,不破坏原有模型的结构化设计;同时,Evo-ViT是在模型训练过程中动态发掘冗余与低效信息,无需预训练模型,因此能同时提升模型的训练和推断效率。方法主要两点创新:
提出了结构保留的token选择策略,通过分析全局class attention,来动态区分高信息token和低信息token,并保留低信息token来确保完整的信息流;
提出了双流token更新策略,对高信息token及低信息token的归纳进行精细更新,然后用归纳token对低信息token进行高效更新,从而在不改变网络结构的情况下,大幅提升模型性能。
技术细节
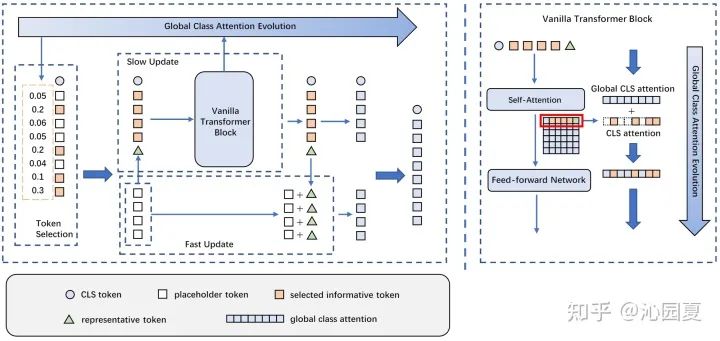
图2 介绍了Evo-ViT的具体框架设计,包括基于全局class attention的token选择以及慢速-快速双流token更新两个模块。其根据全局class attention的排序判断高信息token和低信息token,将低信息token整合为一个归纳token,和高信息token一起输入到原始多头注意力(Multi-head Self-Attention, MSA)模块以及前向传播(Fast Fed-forward Network, FFN)模块中进行精细更新。更新后的归纳token用来快速更新低信息token。全局class attention也在精细更新过程中进行同步更新变化。
实验结果
为了验证方法的有效性,Evo-ViT基于直筒型Transformer结构DeiT[5]、金字塔型结构LeViT[6],在主流Benchmark ImageNet-1k上进行对比实验。
图3是Evo-ViT和现有token相关高效性设计方法的对比,包括PS-ViT[4]、DynamicViT[3]、SViTE[7]、IA-RED2[8]。实验结果表明,其在确保准确率的同时,能够有更高的吞吐量提升,性能优化的表现更佳。
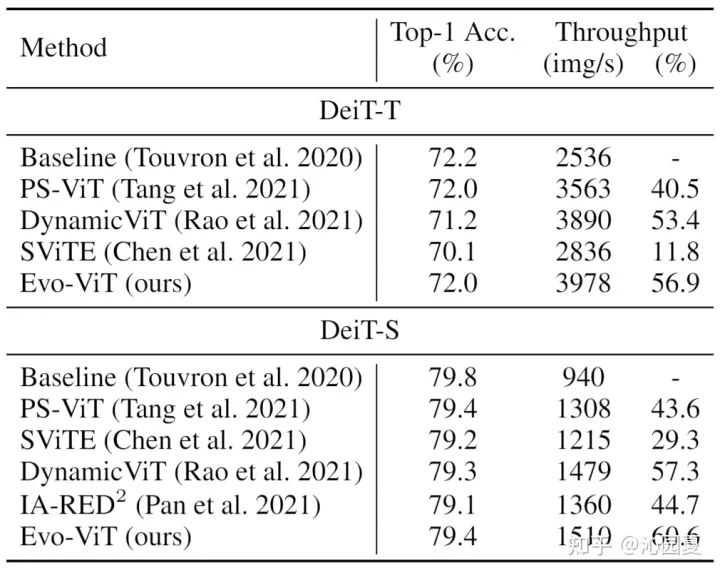
图4为Evo-ViT在金字塔型结构上的验证实验。由于以往直接裁剪的方法均无法直接用于具有空间先验的金字塔型结构,Evo-ViT只和目前SOTA的金字塔型Transformer进行了比较。

该工作还进一步可视化了其token选择结果,如图5所示。左边部分为训练好的完整模型在各层的token选择结果,右边部分为训练过程中不同阶段的token选择结果。可以发现,训练好的模型各层选择基本趋于一致,这是因为模型倾向于用更多的资源更新高信息量的token,即让高信息量token通过所有层的精细更新。同时,由于文章提出的保持结构的双流更新策略,可以发现一些浅层被误判的token在深层也可以被捡回来,如第四行的棒球图片,在前层时棒球杆被误判为低信息量token,但是在深层全部被捡了回来。进一步观察右边部分,可以发现随着训练的深入token选择效果逐渐趋于最优。

结论
本文提出了一种基于慢速-快速双流更新思想的通用视觉Transformer加速方法,Evo-ViT。不同于以往的方法,本文通过给高信息量token和低信息量token分配不同的计算优先级,使得加速模型的同时保留了内部特征的空间结构,同时适用于直筒型和金字塔型Transformer。实验表明Evo-ViT可以对模型进行有效的加速。
从可视化结果可以看出,本文所提出的方法可以使模型更关注于图像的核心区域,这对于模型的可解释性,以及需要利用高层语义的任务有潜在的帮助。如何将本文的方法用于更多下游任务,如检测、分割,也是一个有趣的方向。
以上即Evo-ViT的基本介绍,更多细节可见论文。大家有什么想法意见欢迎评论留言~
参考文献
[1] Pyramid vision transformer: A versatile backbone for dense prediction without convolutions. arXiv:2102.12122
[2] Rethinking spatial dimensions of vision transformers. arXiv preprint arXiv:2103.16302
[3] DynamicViT: Efficient Vision Transformers with Dynamic Token Sparsification. arXiv:2106.02034.
[4] Patch Slimming for Efficient Vision Transformers. arXiv:2106.02852
[5] Training data-efficient image transformers & distillation through attention. arXiv:2012.12877.
[6] LeViT: a Vision Transformer in ConvNet’s Clothing for Faster Inference. arXiv:2104.01136
[7] Chasing Sparsity in Vision Transformers: An End-to-End Exploration. arXiv:2106.04533
[8] IA-RED2: Interpretability-Aware Redundancy Reduction for Vision Transformers. arXiv:2106.12620
[9] Swin transformer: Hierarchical vision transformer using shifted windows. arXiv preprint arXiv:2103.14030.
如果觉得有用,就请分享到朋友圈吧!
公众号后台回复“CVPR21检测”获取CVPR2021目标检测论文下载~

# CV技术社群邀请函 #

备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~
