
你真的了解 GET 和 POST 吗,它们的区别是什么?
回复交流,加入前端编程面试算法每日一题群
引言
本文从以下几个方面走进 GET 与 POST 的区别:
w3school 给出的标准答案 从 HTTP 是什么开始,深入 GET 与 POST 请求方法,及两者的本质区别 常见的 GET 与 POST 问题与误解 POST 方法比 GET 方法安全? POST 方法会产生两个 TCP 数据包?
标准答案
GET 与 POST 是 HTTP 请求中最常用的两种方法,GET 与 POST 的区别也是老生常谈的问题了,信手拈来
| GET | POST | |
|---|---|---|
| 后退按钮/刷新 | 无害 | 数据会被重新提交(浏览器应该告知用户数据会被重新提交)。 |
| 书签 | 可收藏为书签 | 不可收藏为书签 |
| 缓存 | 能被缓存 | 不能缓存 |
| 编码类型 | application/x-www-form-urlencoded | application/x-www-form-urlencoded 或 multipart/form-data。为二进制数据使用多重编码。 |
| 历史 | 参数保留在浏览器历史中。 | 参数不会保存在浏览器历史中。 |
| 对数据长度的限制 | 是的。当发送数据时,GET 方法向 URL 添加数据;URL 的长度是受限制的(URL 的最大长度是 2048 个字符)。 | 无限制。 |
| 对数据类型的限制 | 只允许 ASCII 字符。 | 没有限制。也允许二进制数据。 |
| 安全性 | 与 POST 相比,GET 的安全性较差,因为所发送的数据是 URL 的一部分。在发送密码或其他敏感信息时绝不要使用 GET ! | POST 比 GET 更安全,因为参数不会被保存在浏览器历史或 web 服务器日志中。 |
| 可见性 | 数据在 URL 中对所有人都是可见的。 | 数据不会显示在 URL 中。 |
上面是 w3school 给出的标准答案
但你真的理解它吗?在我们学习了那么多 HTTP 知识后,仅仅回答这些就够了吗?GET 与 POST 都是 HTTP 的请求方法,如何理解请求方法?本质区别又是什么?
下面让我们一步步走进 GET 与 POST 方法,以及两者的本质区别
深入 GET 与 POST 请求方法
1. HTTP 是什么?
HTTP (HyperText Transfer Protocol)是建立在 TCP 上的应用层协议,超文本传输协议。其中:
超文本:图片、音频、视频、甚至是压缩包等 传输:两点之间数据的双向传送 协议:一种行为约定和规范
所以,HTTP 协议用更通俗易懂的话描述就是 一个在计算机世界里专门在两点之间传输文字、图片、音频、视频等超文本数据的约定和规范
虽说 HTTP 协议是“传输协议”,但它不关心寻址、路由、数据完整性等传输细节,这些底层的具体传输工作是由 TCP/IP 协议负责,例如 IP 协议实现寻址和路由、TCP 协议实现可靠数据传输,另外还有 DNS 协议实现域名查找、SSL/TLS 协议实现安全通信等
那 HTTP 协议主要干嘛喃?
2. HTTP 报文
HTTP 协议的核心部分就是它定义的传输报文的格式,例如报文的组成、解析规则等,以便于在 TCP/IP 上实现更多样灵活的功能,如缓存控制、数据编码、内容协议等
HTTP 报文分为四部分:
起始行:在请求报文中是请求行,在响应报文中是状态行(表示服务器的响应状态) 头部:header 空行:在 header 与 body 之间其实是有个 “空行” 的 实体:我们通常说的 body
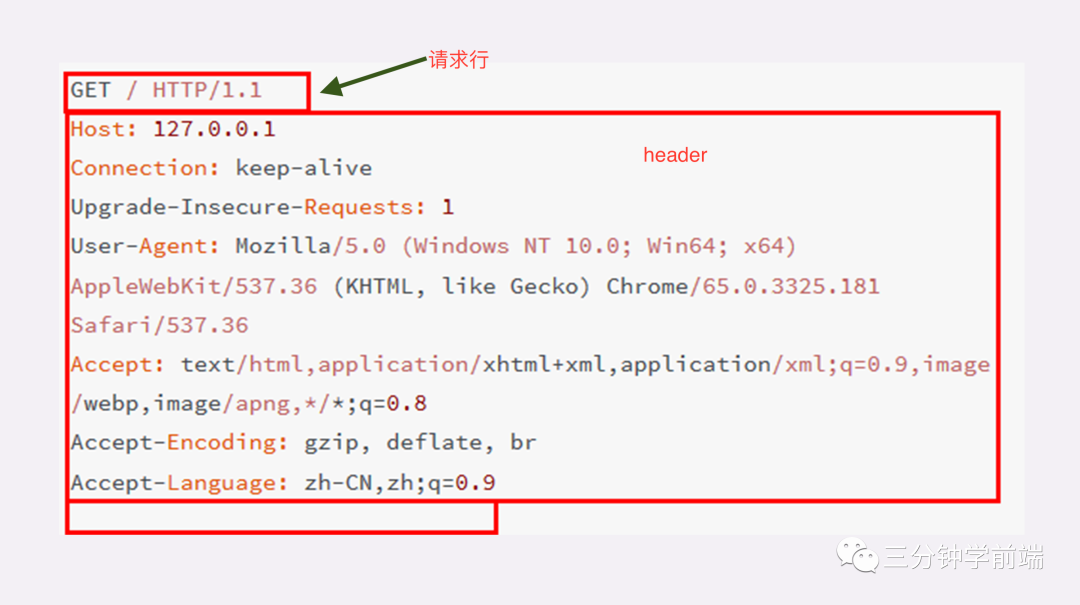
注意:此报文中最后是一个空白行结束,没有 body(GET 请求一般都没有 body)
其中,请求方法就规定在起始行中:
请求行:GET /uri HTTP/1.1,包含请求方法 GET 或 POST 等

状态行:HTTP/1.1 200 OK,仅仅包含服务器的响应状态,不包含请求方法

请求方法
客户端发起 HTTP 请求,服务器响应客户端请求,客户端可以对服务器端的资源进行操作,例如查询、添加、删除等,但具体执行哪种操作喃?
这就是请求方法存在的意义,它规定了客户端的某种操作指令,用来告诉服务器端我需要进行哪种操作,常见的请求方法有:
GET :获取资源,常用于读取或下载资源 HEAD :请求一个与 GET 请求的响应相同的响应,只返回请求头,没有响应体,多数由 JavaScript 发起 POST :用于将实体(body)提交到指定的资源,通常导致状态或服务器上的副作用的更改 PUT :用请求有效载荷替换目标资源的所有当前表示。 DELETE :删除指定的资源。 CONNECT :建立一个到由目标资源标识的服务器的隧道,多用于 HTTPS 和 WebSocket 。 OPTIONS :预检,用于描述目标资源的通信选项。通过该请求来知道服务端是否允许跨域请求。 TRACE :沿着到目标资源的路径执行一个消息环回测试,多数线上服务都不支持 PATCH :用于对资源应用部分修改。
GET 请求方法应该是 HTTP 所有请求方法中最开始出现的了,它表示从服务器获取资源
POST 请求方法是 HTTP 所有协议中除 GET 之外最常使用的请求方法了,它表示向指定的服务器资源提交数据,提交数据存放在 HTTP 报文中的 body 中,通常导致状态或服务器上的副作用的更改
3. GET 与 POST 请求方法的本质区别
综上所述,总结一下,GET 与 POST 的本质区别有两点:
请求行不同: GET:GET /uri HTTP/1.1 POST:POST /uri HTTP/1.1 对服务器资源的操作不同: GET:表示从服务器获取资源 POST:向指定的服务器资源提交数据(通常导致状态或服务器上的副作用的更改)
进阶:常见问题及解答
1. POST 方法比 GET 方法安全?
在 HTTP 协议里,所谓的“安全”是指请求方法不会对服务器上的资源进行修改,“破坏”服务器上的资源
按照这种定义,GET 请求方法是安全的,它对服务器资源执行的仅仅是只读操作,也是幂等的
幂等指多次执行相同的操作,结果也都是相同的,即多次“幂”后结果“相等”
POST 请求方法是不安全的,它会修改服务器上的资源,在 RFC 里的语义,POST 是指“新增或提交数据”,多次提交数据会创建多个资源,所以不是幂等的
总结:
GET:安全,幂等 POST:不安全,不幂等
对于传输来说,GET 和 POST 报文在传输上都是不安全的,因为 HTTP 在网络上是明文传输的,想要安全传输就得加密,也就是 HTTPS
2. POST 方法会产生两个 TCP 数据包?
这个就神奇了,在部分文章中提到,POST 请求方法会将 header 和 body 分开发送,先发送 header,服务端返回 100 状态码再发送 body 🤔️🤔️🤔️
HTTP 协议中没有明确说明 POST 会产生两个 TCP 数据包,而且实际测试(Chrome、Firefox)发现,header 和 body 不会分开发送。
但为什么有些作者会这样写喃?我查找了相关资料,终于发现,真有这种情况,原文在这里:
In search of performance - how we shaved 200ms off every POST request
https://gocardless.com/blog/in-search-of-performance-how-we-shaved-200ms-off-every-post-request/
主要内容是作者发现 POST 比 GET 多 200ms,然后深入研究,发现 ruby 的 net::HTTP 库,会将一个 http 请求拆分,先发送 header 部分。另外,由于没有设置 TCP_NODELY ,所以第一个包之后要等待 ack ,才发下一个包,导致了一个请求有 200ms 的延迟。

另外,关于 HTTP 100 Continue:
100 Continue的目的是对HTTP客户端应用程序有一个实体的主体部分要发送服务器,但希望在发送之前查看一下服务器是否会接受这个实体这种情况进行优化
----《HTTP权威指南》
客户端:
如果客户端在向服务器发送一个实体,并愿意在发送实体之前等待100 Continue响应,那么客户端就要发送一个携带了值为100 Continue的Expect请求首部。如果客户端没有发送实体,就不应该发送100 Continue Expect首部,因为这样会使服务器误以为客户端要发送一个实体
服务器端:
如果服务器收到一条带有值为100 Continue的Expect首部的请求,它会用100 Continue响应或一条错误码来进行响应。服务器永远也不应该向没有发送100 Continue期望的客户端发送100 Continue状态码。
如果服务器在有机会发送100 Continue响应之前就收到了部分(或者全部)的实体,说明服务器已经打算继续发送数据了,这样服务器就不需要发送这个状态码了,但是服务器完成请求之后,还是应该为请求发送一个最终状态码
也就是说,没收到客户端的 100 Continue 就不会有响应
总结
因此,大多数框架都是尽量在一个 TCP 包里面把 HTTP 请求发出去的,但是也确实存在先发 HTTP 头,然后发 body 的框架。但是具体发多少个TCP包,这个 不是 HTTP 协议的事情是操作系统 TCP 协议栈与代码的问题,跟 HTTP 没关系