ACL 2022录用结果出炉:国内多支团队晒“战绩”,清华一实验组18篇入选
大数据文摘
共 12422字,需浏览 25分钟
·
2022-03-02 21:46

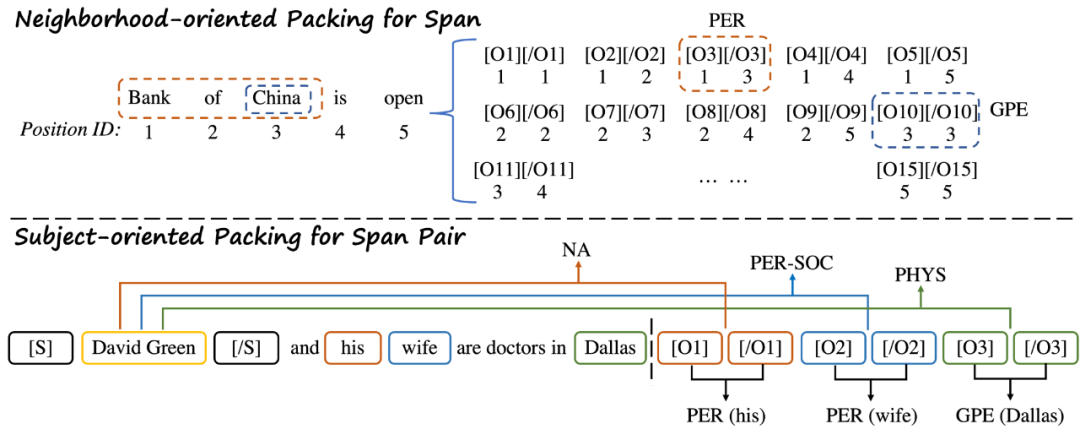
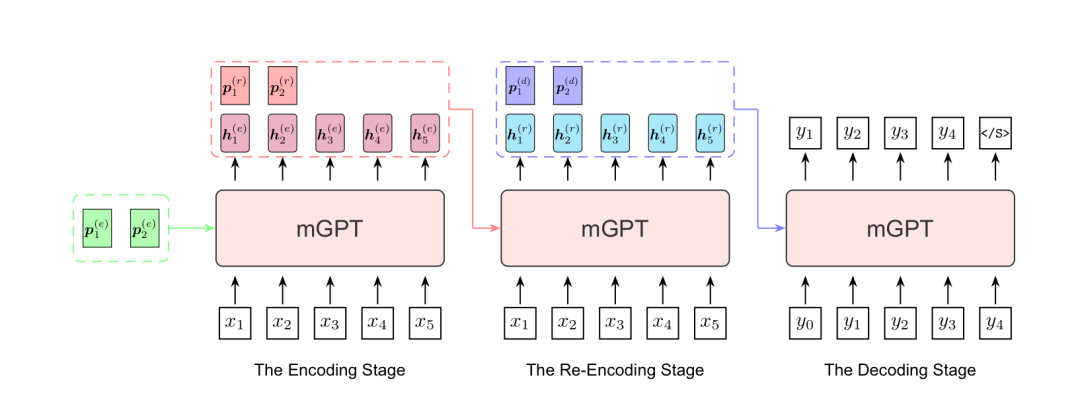
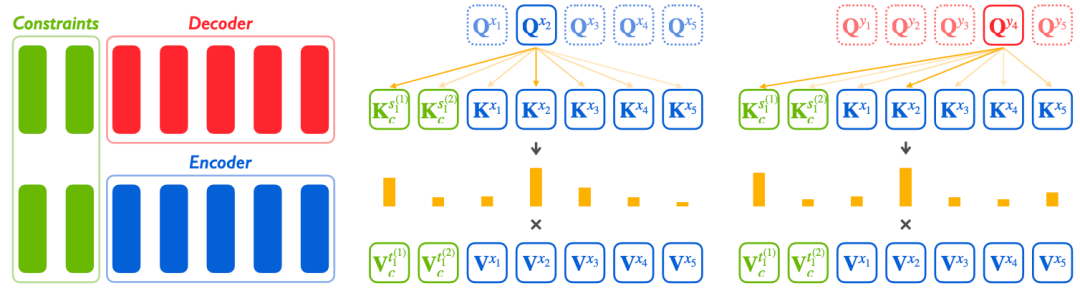
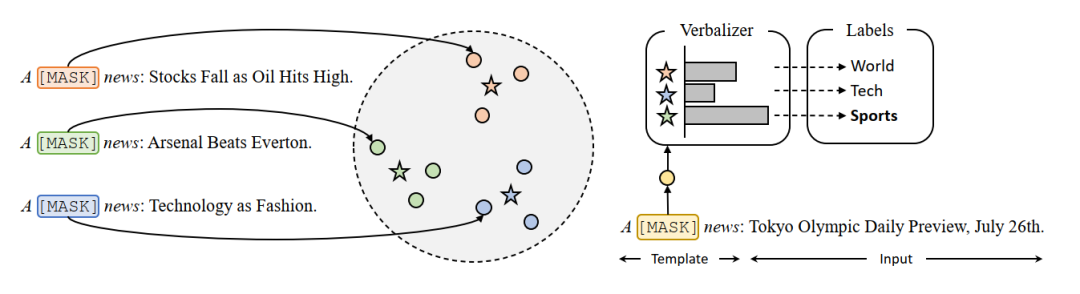
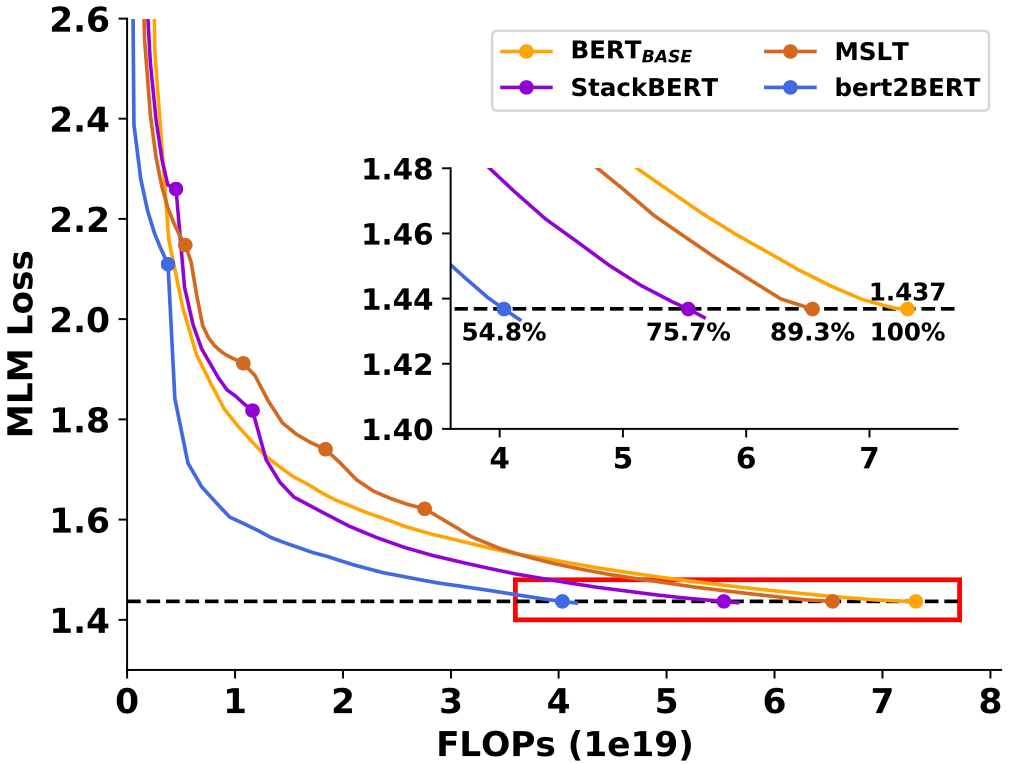
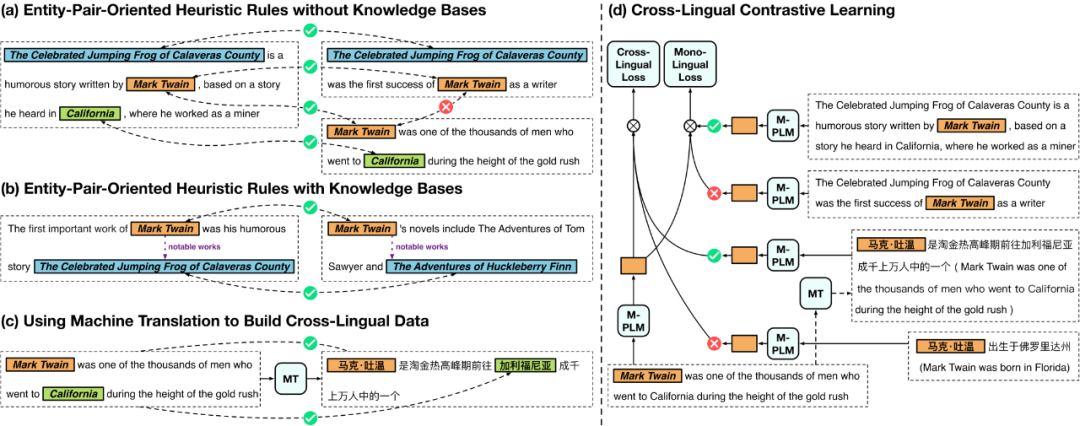
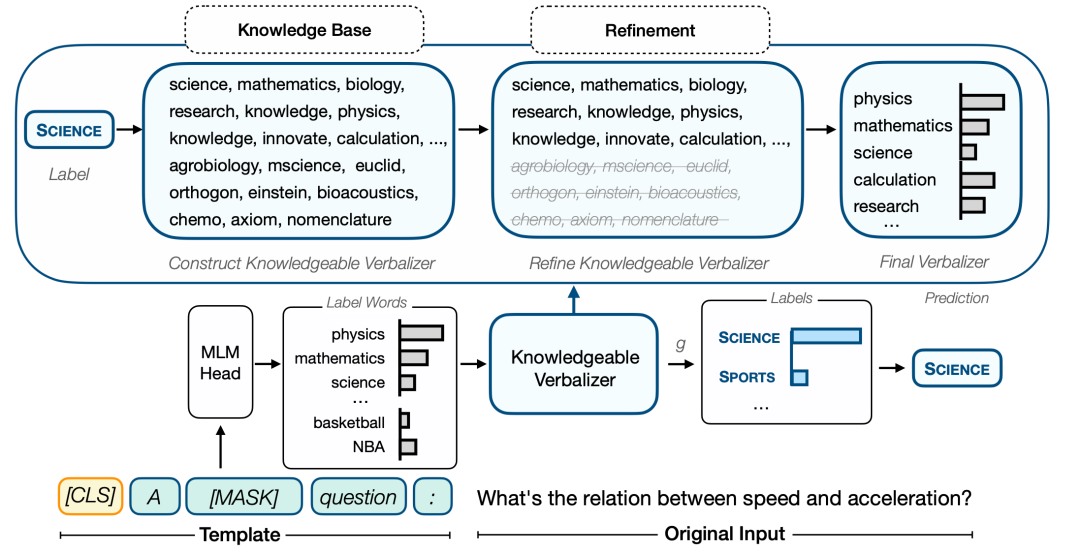
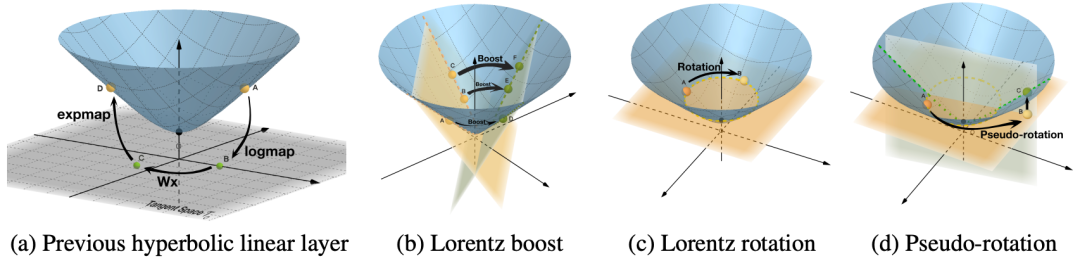
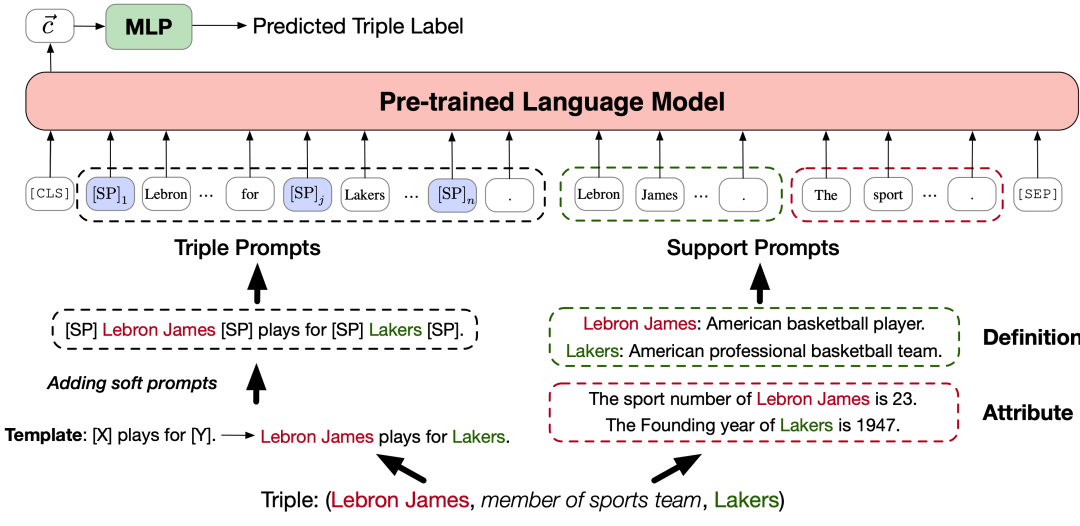
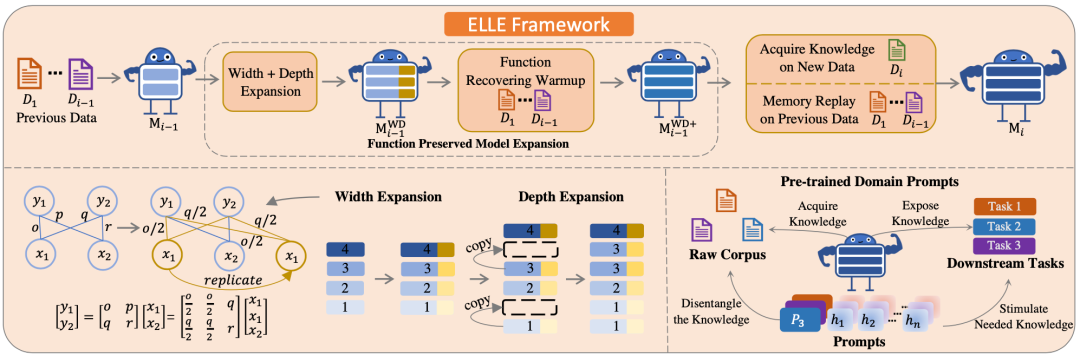
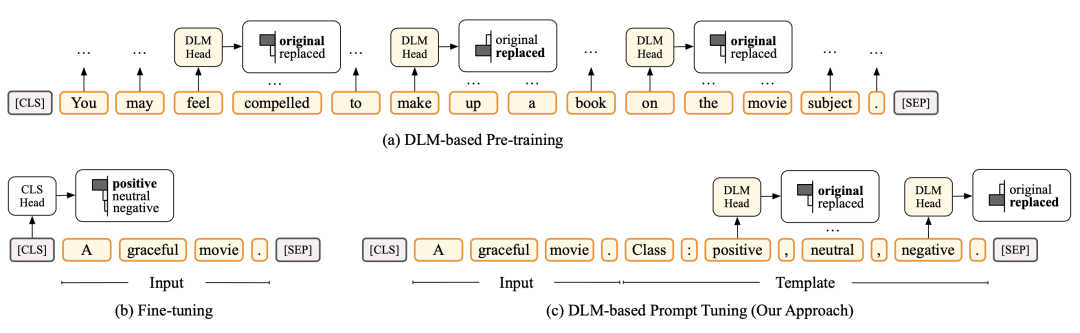
根据官方公开信息,现将多支国内团队的录取结果汇总如下,包括清华NLP团队、中科院计算所跨媒体计算课题组(ICTMCG)、北京语言大学语言监测与智能学习研究组(BLCU-ICALL)、中科院软件所中文信息处理实验室,入选论文方向涵盖预训练、多模态、无监督等前沿方法。

评论

共 12422字,需浏览 25分钟
·
2022-03-02 21:46