
清华大学提出DAT | DCN+Swin Transformer会碰撞出怎样的火花???


最近,Transformer在各种视觉任务上都表现出了卓越的表现。有时Transformer模型比CNN模型具有更高的表现能力。然而,单纯扩大感受野也会引起一些问题。一方面,在ViT中使用密集的注意力会导致内存和计算成本过高,特征会受到超出兴趣区域的不相关部分的影响。另一方面,在PVT或Swin Transformer 中采用的稀疏注意里力是数据不可知的,可能会限制建模长期关系的能力。
为了缓解这些问题,本文提出了一种新的可变形的自注意力模块,该模块以数据依赖的方式选择了自注意力中的key和value对的位置。这种灵活的方案使自注意力模块能够聚焦于相关区域并捕获更多信息。在此基础上,提出了一种可变形注意力Transformer(Deformable Attention Transformer)模型,该模型具有可变形注意力,适用于图像分类和密集预测任务。大量的实验表明,本文的模型在综合基准上取得了持续改进的结果。
1简介
Transformer最初是用来解决自然语言处理任务的。它最近在计算机视觉领域显示出巨大的潜力。先锋工作Vision Transformer(ViT)将多个Transformer块堆叠在一起,以处理非重叠的图像patch(即视觉Token)序列,从而产生了一种无卷积的图像分类模型。与CNN模型相比,基于Transformer的模型具有更大的感受野,擅长于建模长期依赖关系,在大量训练数据和模型参数的情况下取得了优异的性能。然而,视觉识别中的过度关注是一把双刃剑,存在多重弊端。具体来说,每个query patch中参与的key数过多会导致较高的计算成本和较慢的收敛速度,并增加过拟合的风险。
为了避免过度的注意力计算,已有的研究利用精心设计的有效注意力模式来降低计算复杂度。其中有两种具有代表性的方法:
Swin Transformer采用基于Window的局部注意力来限制Local Window中的注意力;
Pyramid Vision Transformer(PVT)则通过对key和value特征映射进行采样来节省计算量。
手工设计的注意力模式虽然有效,但不受数据影响,可能不是最佳的。相关的key/value很可能被删除,而不太重要的key/value仍然保留。
理想情况下,给定query的候选key/value集应该是灵活的,并且能够适应每个单独的输入,这样就可以缓解手工制作的稀疏注意力模式中的问题。事实上,在cnn的文献中,学习卷积滤波器的可变形感受野已被证明在依赖于数据的基础上有选择性地关注更多信息区域时是有效的。
最值得注意的工作,Deformable Convolution Networks(DCN),已经在许多具有挑战性的视觉任务上产生了令人印象深刻的结果。这促使想在Vision Transformer中探索一种可变形的注意力模式。然而,这种想法的简单实现会导致不合理的高内存/计算复杂度:
由Deformable offsets引入的开销是patch数量的平方。因此,尽管最近的一些工作研究了变形机制的思想,但由于计算成本高,没有人将其作为构建强大的Backbone(如DCN)的基本构件。相反,它们的可变形机制要么在检测头中采用,要么作为预处理层对后续Backbone的patch进行采样。
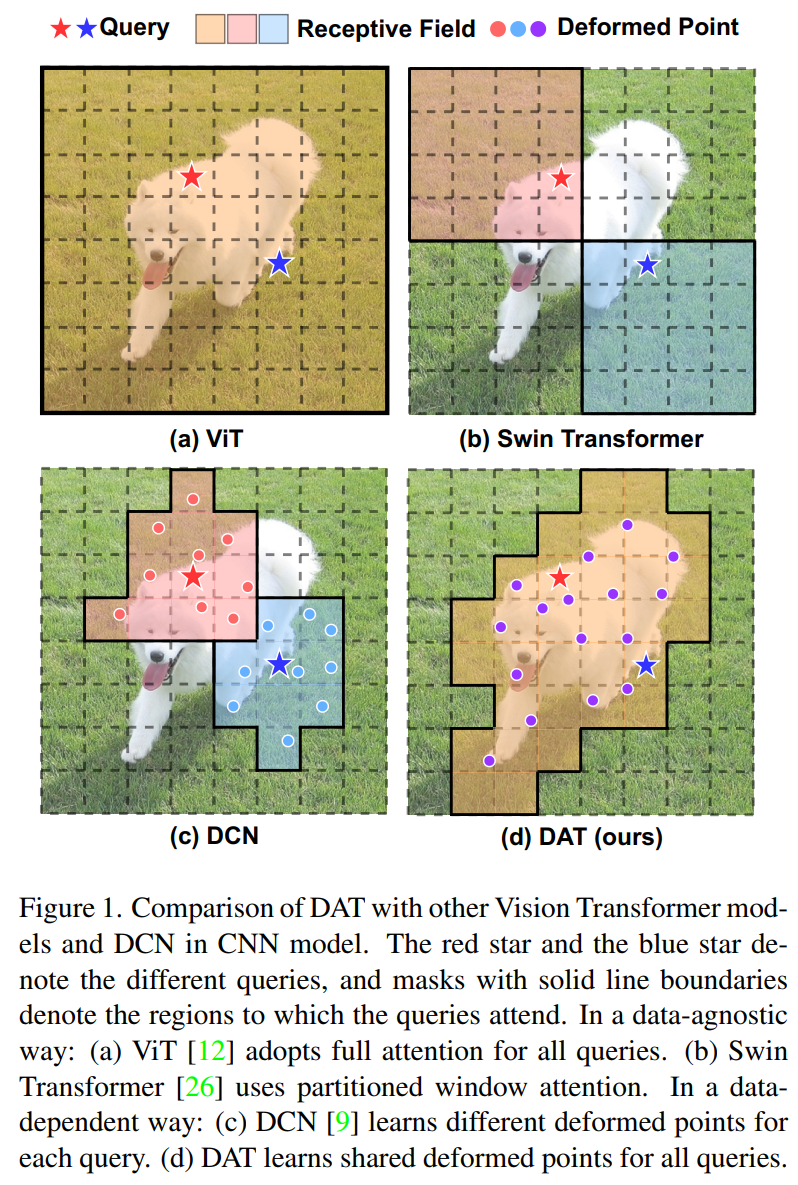
本文提出了一种简单有效的可变形的自注意力模块,并在此模块上构造了一个强大的Pyramid Backbone,即可变形的注意力Transformer(Deformable Attention Transformer, DAT),用于图像分类和各种密集的预测任务。
不同于DCN,在整个特征图上针对不同像素学习不同的offset,作者建议学习几组query无关的offset,将key和value移到重要区域(如图1(d)所示),这是针对不同query的全局注意力通常会导致几乎相同的注意力模式的观察结果。这种设计既保留了线性空间的复杂性,又为Transformer的主干引入了可变形的注意力模式。
具体来说:
对于每个注意力模块,首先将参考点生成为统一的网格,这些网格在输入数据中是相同的; 然后,offset网络将query特征作为输入,并为所有参考点生成相应的offset。这样一来,候选的key /value被转移到重要的区域,从而增强了原有的自注意力模块的灵活性和效率,从而捕获更多的信息特征。
2相关工作
2.1 ViT Backbone
自引入ViT以来,改进的重点是密集预测任务的多尺度特征学习和高效的注意力机制。这些注意力机制包括Window Attention、Global Token、Focal Attention和动态Token Size。
最近,基于卷积的方法被引入到Vision Transformer模型中。其中,已有的研究集中在用卷积运算来补充变压器模型,以引入额外的电感偏差。CvT在标记化过程中采用卷积,利用步幅卷积来降低自注意的计算复杂度。带卷积茎的ViT建议在早期添加卷积,以实现更稳定的训练。CSwin Transformer采用了基于卷积的位置编码技术,并显示了对下游任务的改进。这些基于卷积的技术中有许多可以应用于DAT之上,以进一步提高性能。
2.2 DCN和Attention
可变形卷积是一种强大的机制,可以处理基于输入数据的灵活空间位置。最近,它已被应用于Vision Transformer。Deformable DETR通过在CNN Backbone的顶部为每个query选择少量的key来提高DETR的收敛性。由于缺少key限制了其表示能力,其Deformable Attention不适合用于特征提取的视觉Backbone。
此外,Deformable DETR中的注意力来自简单的线性投影,query token之间不共享key。DPT和PS-ViT构建Deformable Block来细化视觉token。具体来说,DPT提出了一种Deformable Patch Embedding方法来细化跨阶段的Patch,PS-ViT在ViT Backbone前引入了空间采样模块来改善视觉Token。它们都没有把Deformable Attention纳入视觉中枢。相比之下,本文的Deformable Attention采用了一种强大而简单的设计,来学习一组在视觉token之间共享的全局key,并可以作为各种视觉任务的一般Backbone。本文方法也可以看作是一种空间适应机制,它在各种工作中被证明是有效的。
3Deformable Attention Transformer
3.1 Preliminaries
首先在最近的Vision Transformer中回顾了注意力机制。以Flatten特征图为输入,M头自注意力(MHSA)块表示为:
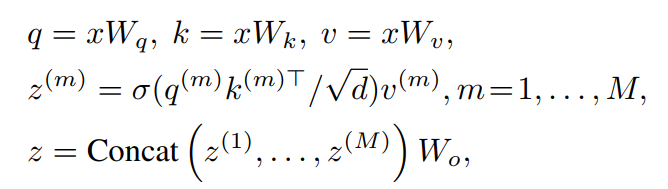
其中,表示softmax函数,d=C/M为每个Head的尺寸。z(m)表示第m个注意力头的嵌入输出,分别表示query、key和value嵌入。是投影矩阵。为了建立一个Transformer Block,通常采用一个具有2个线性变换和一个GELU激活的MLP块来提供非线性。
通过归一化层和shortcuts,第1个Transformer Block被表示为:
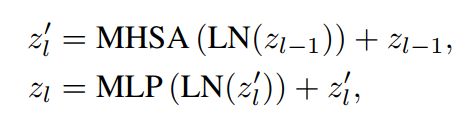
其中LN表示层归一化。
3.2 Deformable Attention
现有的分层Vision Transformer,特别是PVT和Swin Transformer试图解决过度关注的问题。前者的降采样技术会导致严重的信息丢失,而后者的注意力转移会导致感受野的增长要慢得多,这限制了建模大物体的潜力。因此,需要依赖数据的稀疏注意力来灵活地建模相关特征,这也孕育了在DCN中提出的可变形的机制。
然而,简单地在Transformer模型中实现 DCN 是一个重要的问题。在DCN中,特征图上的每个元素分别学习其offset,其中H×W×C特征图上的3×3可变形卷积的空间复杂度为9HWC。如果直接在自注意力模块应用相同的机制,空间复杂度将急剧上升到,、为query和key的数量,通常有相同的尺度特征图大小HW,带来近似双二次复杂度。
虽然Deformable DETR通过在每个检测头设置更少的key()来减少这个计算开销,但是,在Backbone中,这样少的key是次要的,因为这样的信息丢失是不可接受的(见附录中的详细比较)。
同时,在先前的工作中的观察显示,不同的query在视觉注意力模型中具有相似的注意力图。因此,选择了一个更简单的解决方案,为每个query共享移动的key和value以实现有效的权衡。
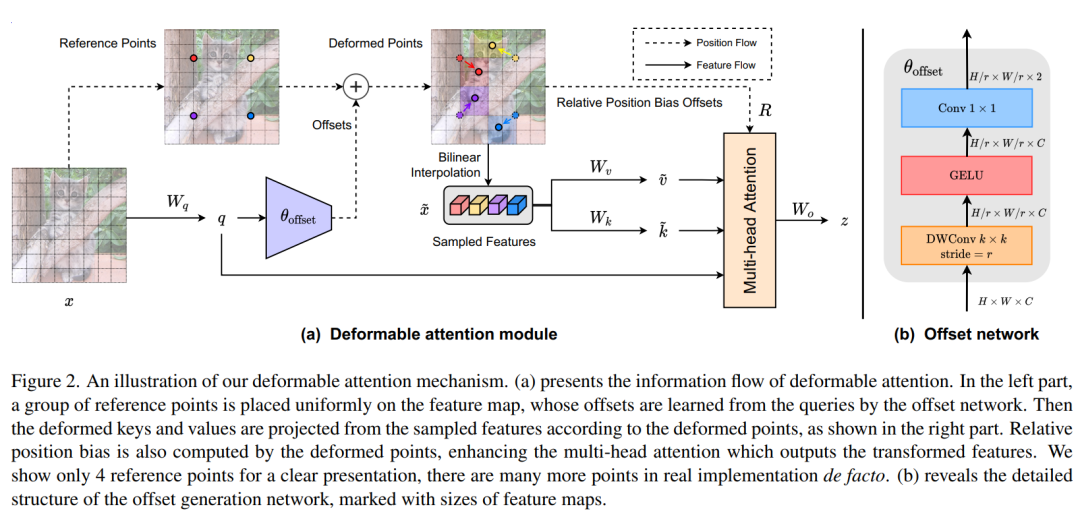
具体来说,本文提出了Deformable Attention,在特征映射中重要区域的引导下,有效地建模Token之间的关系。这些集中的regions由offset网络从query中学习到的多组Deformable sampling点确定。采用双线性插值对特征映射中的特征进行采样,然后将采样后的特征输入key投影得到Deformable Key。
1、Deformable注意力模块
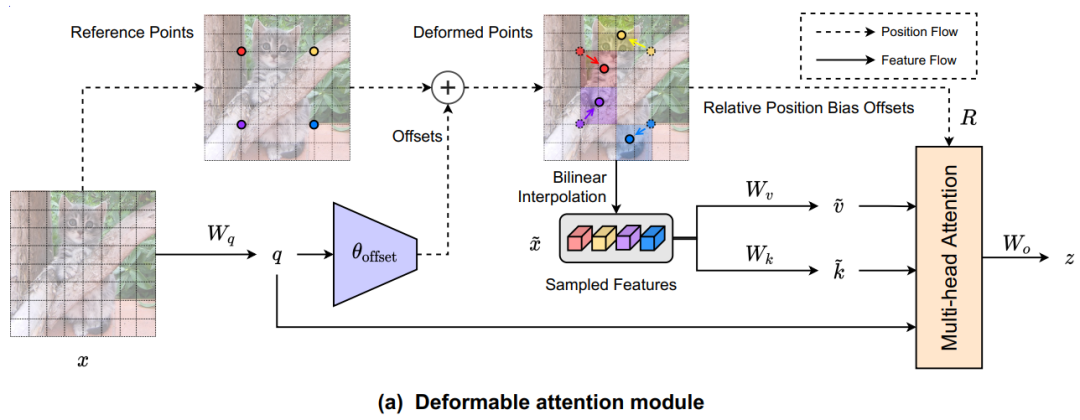
如图2(a)所示,给定输入特征图,生成一个点的统一网格作为参考。具体来说,网格大小从输入的特征图大小降采样一个系数,,。参考点的值为线性间隔的2D坐标,然后根据网格形状将其归一化为范围,其中表示左上角,表示右下角。
为了获得每个参考点的offset,将特征映射线性投影到query token ,然后输入一个轻量子网络,生成偏移量。为了稳定训练过程,这里用一些预定义的因子来衡量的振幅,以防止太大的offset,即。然后在变形点的位置进行特征采样,作为key和value,然后是投影矩阵:
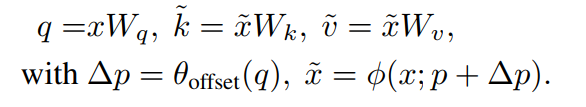
和分别表示deformed key嵌入和value嵌入。具体来说,将采样函数设置为双线性插值,使其可微:
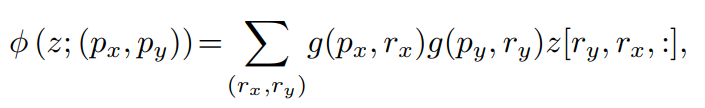
其中和索引了的所有位置。由于只在最接近的4个积分点上不为零,因此它简化了Eq(8)到4个地点的加权平均值。与现有的方法类似,对进行多头注意力,并采用相对位置偏移。注意力头的输出被表述为:
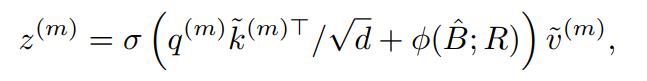
其中对应于位置嵌入,同时有一些适应。详细信息将在本节的后面进行解释。每个头部的特征连接在一起,通过投影得到最终输出z。
2、Offset生成
如前面所述,采用一个子网络进行Offset的生成,它分别消耗query特征和输出参考点的offset值。考虑到每个参考点覆盖一个局部的s×s区域(×是偏移的最大值),生成网络也应该有对局部特征的感知,以学习合理的offset。
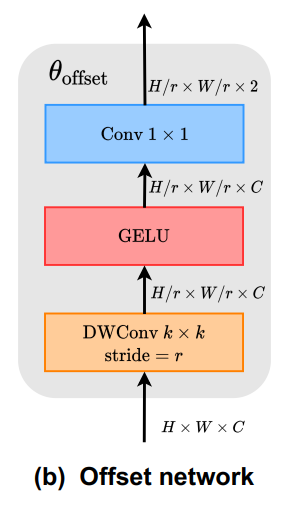
因此,将子网络实现为2个具有非线性激活的卷积模块,如图2(b)。所示输入特征首先通过一个5×5的深度卷积来捕获局部特征。然后,采用GELU激活和1×1卷积得到二维偏移量。同样值得注意的是,1×1卷积中的偏差被降低,以缓解所有位置的强迫性偏移。
3、Offset groups
为了促进变形点的多样性,在MHSA中遵循类似的范式,并将特征通道划分为G组。每个组的特征分别使用共享的子网络来生成相应的偏移量。在实际应用中,注意力模块的Head数M被设置为偏移组G大小的倍数,确保多个注意力头被分配给一组deformed keys 和 values 。
4、Deformable相对位置偏差
相对位置偏差对每对query和key之间的相对位置进行编码,通过空间信息增强了普通的注意力。考虑到一个形状为H×W的特征图,其相对坐标位移分别位于二维空间的[−H,H]和[−W,W]的范围内。在Swin Transformer中,构造了相对位置偏置表,通过对表的相对位移进行索引,得到相对位置偏置B。由于可变形注意力具有连续的key位置,计算在归一化范围内的相对位移[−1,+1],然后在连续的相对偏置表中插值,以覆盖所有可能的偏移值。
5、 计算的复杂度
可变形多头注意力(DMHA)的计算成本与PVT或Swin Transformer中对应的计算成本相似。唯一的额外开销来自于用于生成偏移量的子网络。整个模块的复杂性可以概括为:
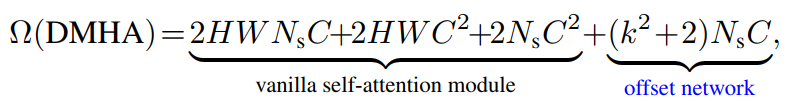
其中,为采样点的数量。可以看出,offset网络的计算代价具有线性复杂度w.r.t.通道的大小,这与注意力计算的成本相对较小。通常,考虑用于图像分类的Swin-T模型的第三阶段,其中,单个块模块中注意力模块的计算成本为79.63MFLOPs。如果插入可变形模块(k = 5),额外的开销是5.08M Flops,这仅是整个模块的6.0%。此外,通过选择一个较大的下采样因子,复杂性将进一步降低,这使得它有利于具有更高分辨率输入的任务,如目标检测和实例分割。
3.3 模型架构
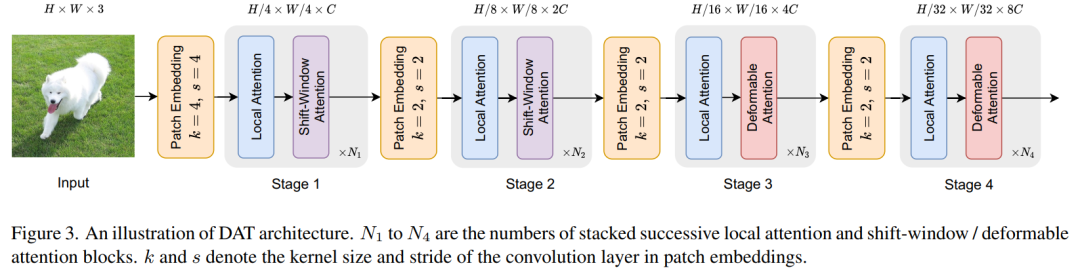
在网络架构方面,模型“可变形注意变换器”与PVT等具有相似的金字塔结构,广泛适用于需要多尺度特征图的各种视觉任务。如图3所示,首先对形状为H×W×3的输入图像进行4×4不重叠的卷积嵌入,然后进行归一化层,得到H4×W4×C 的patch嵌入。为了构建一个层次特征金字塔,Backbone包括4个阶段,stride逐渐增加。在2个连续的阶段之间,有一个不重叠的2×2卷积与stride=2来向下采样特征图,使空间尺寸减半,并使特征尺寸翻倍。
在分类任务中,首先对最后一阶段输出的特征图进行归一化处理,然后采用具有合并特征的线性分类器来预测logits。
在目标检测、实例分割和语义分割任务中,DAT扮演着Backbone的作用,以提取多尺度特征。
这里为每个阶段的特征添加一个归一化层,然后将它们输入以下模块,如目标检测中的FPN或语义分割中的解码器。
在DAT的第三和第四阶段引入了连续的Local Attention和Deformable Attention Block。特征图首先通过基于Window的Local Attention进行处理,以局部聚合信息,然后通过Deformable Attention Block对局部增强token之间的全局关系进行建模。这种带有局部和全局感受野的注意力块的替代设计有助于模型学习强表征,在GLiT、TNT和Point-Former。
由于前两个阶段主要是学习局部特征,因此在这些早期阶段的Deformable Attention不太适合。
此外,前两个阶段的key和value具有较大的空间大小,大大增加了Deformable Attention的点积和双线性插值的计算开销。因此,为了实现模型容量和计算负担之间的权衡,这里只在第三和第四阶段放置Deformable Attention,并在Swin Transformer中采用Shift Window Attention,以便在早期阶段有更好的表示。建立了不同参数和FLOPs的3个变体,以便与其他Vision Transformer模型进行公平的比较。通过在第三阶段叠加更多的块和增加隐藏的维度来改变模型的大小。详细的体系结构见表1。
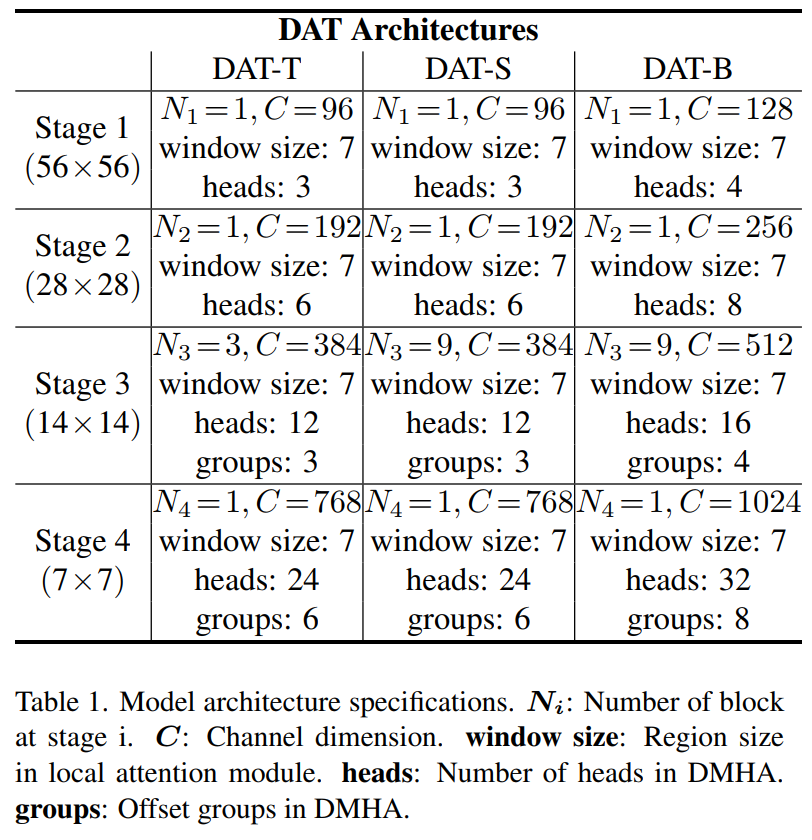
请注意,对于DAT的前两个阶段,还有其他的设计选择,例如,PVT中的SRA模块。比较结果见表7。
4实验
4.1 ImageNet-1K 图像分类
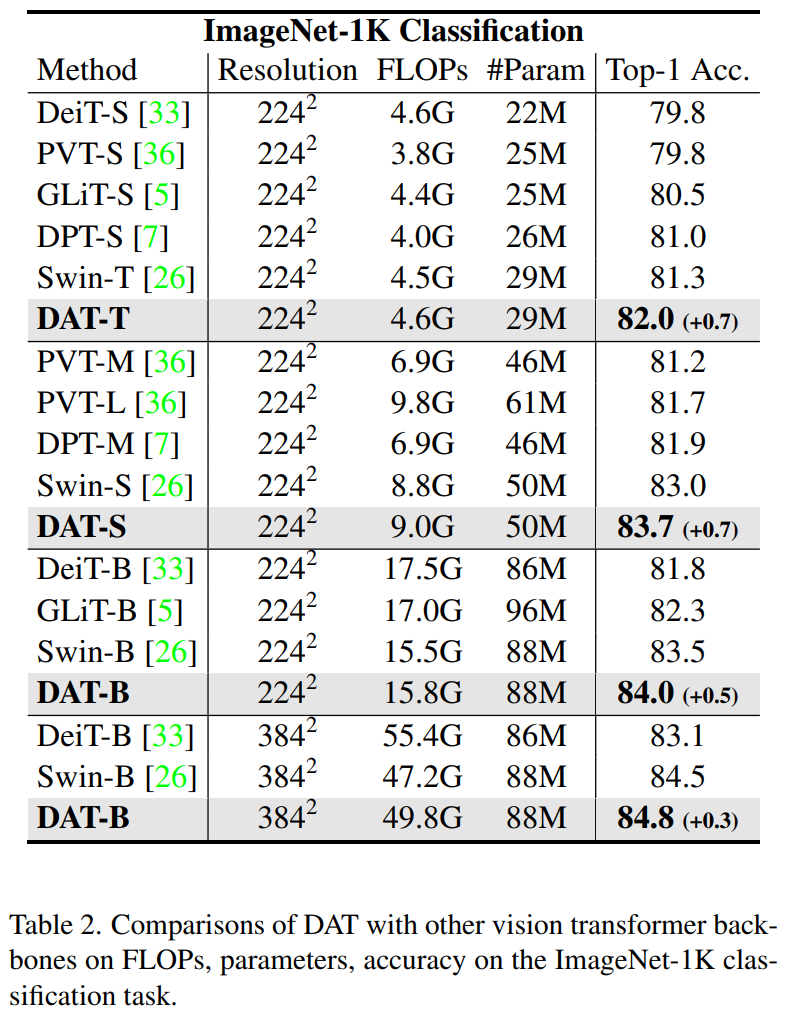
在表2中报告了的结果,有300个训练周期。与其他最先进的ViT相比,DAT在类似的计算复杂性上实现了Top-1精度的显著改进。我们的DAT方法在所有三个尺度上都优于Swin Transformer、PVT、DPT和DeiT。在没有在Transformer Block中插入卷积,或在Patch嵌入中使用重叠卷积的情况下,比Swin Transformer对应的数据获得了+0.7、+0.7和+0.5的提升。当在384×384分辨率下进行微调时,比Swin Transformer表现好0.3%。
4.2 COCO目标检测
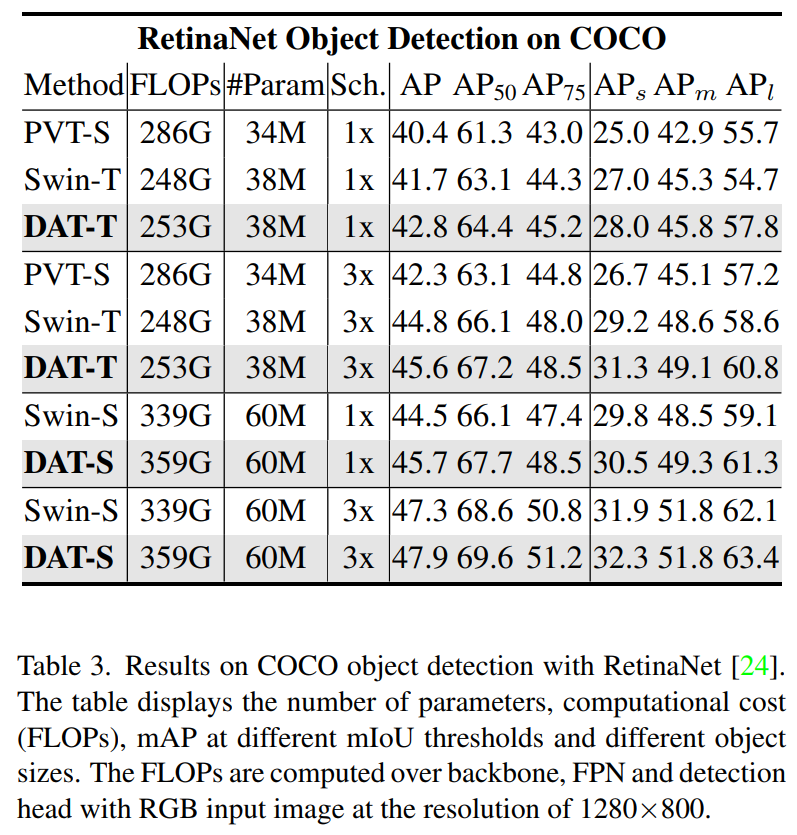
如表3所示,DAT在小型模型中的性能分别超过Swin变压器1.1和1.2mAP。
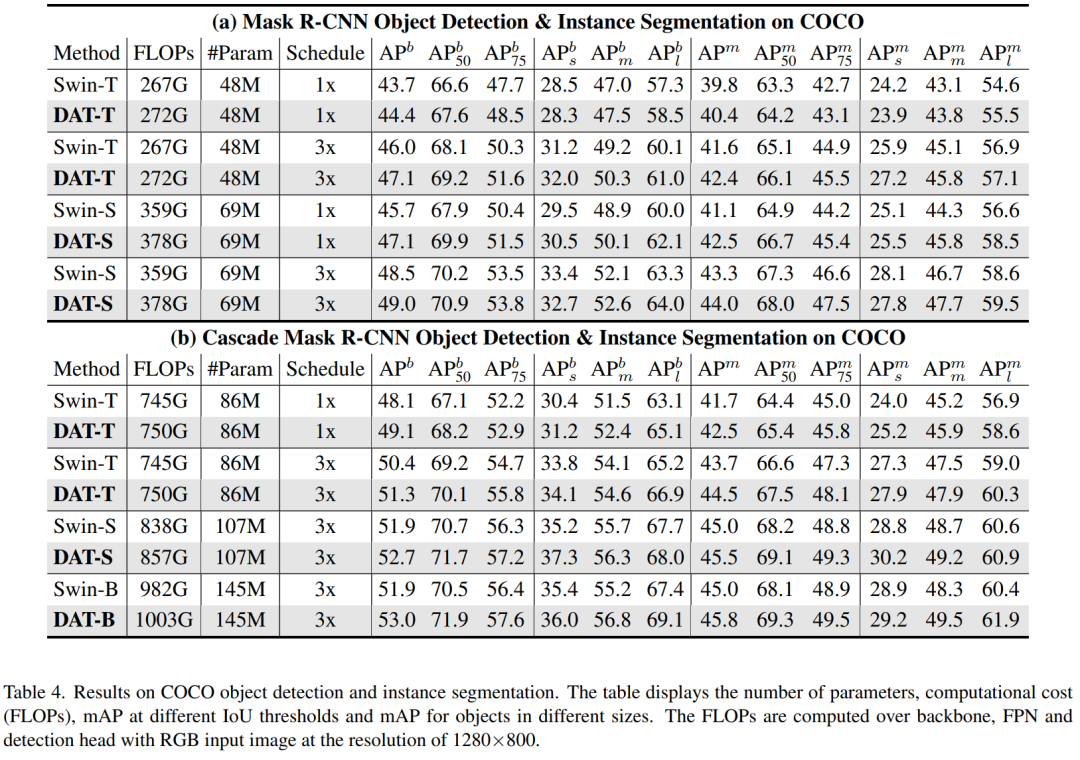
当在两阶段检测器中实现时,如Mask R-CNN和Cascade Mask R-CNN,模型比不同尺寸的Swin Transformer模型实现了一致的改进,如表4所示。可以看到,由于建模随机依赖关系的灵活性,DAT在大型目标上实现了对其(高达+2.1)的改进。小目标检测和实例分割的差距也很明显(高达+2.1),这表明DATs也具有在局部区域建模关系的能力。
4.3 ADE20K语义分割
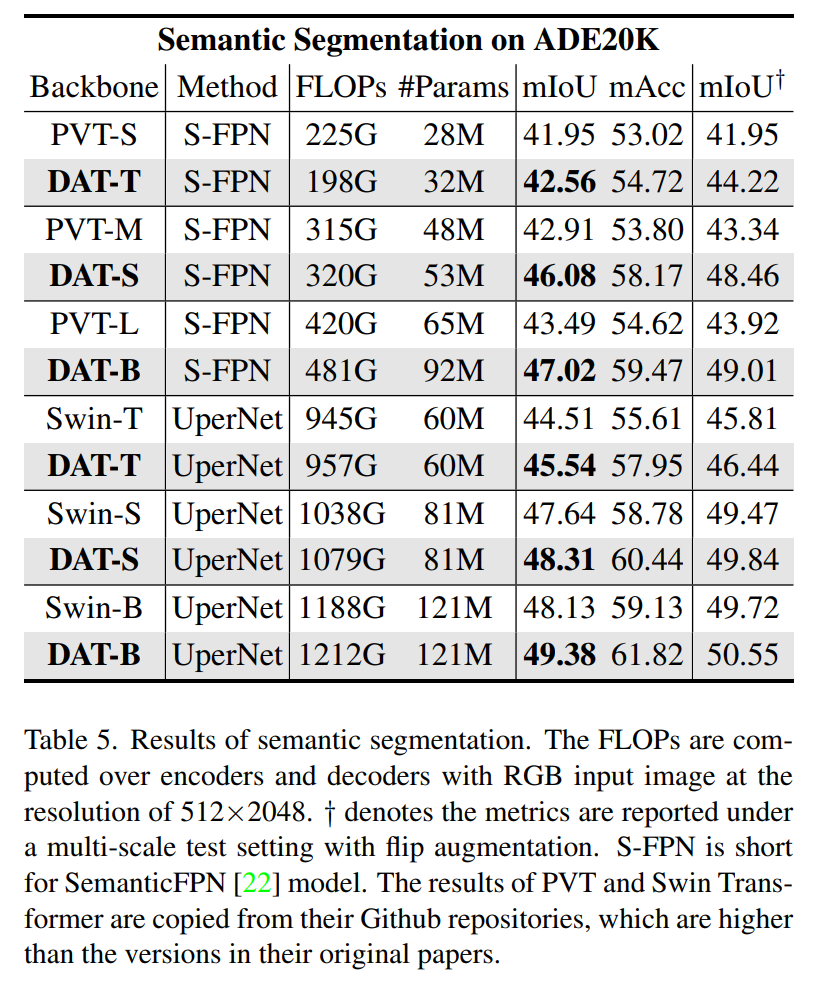
在表5中,所有方法中mIoU得分最高的验证集上的结果。与PVT相比,小模型在参数更少的情况下也超过PVT-S 0.5 mIoU,并且在+3.1和+2.5中实现了显著的提升。DAT在3个模型尺度上都比Swin Transformer有显著的改进,在mIoU中的分别提升了+1.0、+0.7和+1.2,显示了方法的有效性。
4.4 消融实验
1、几何信息开发
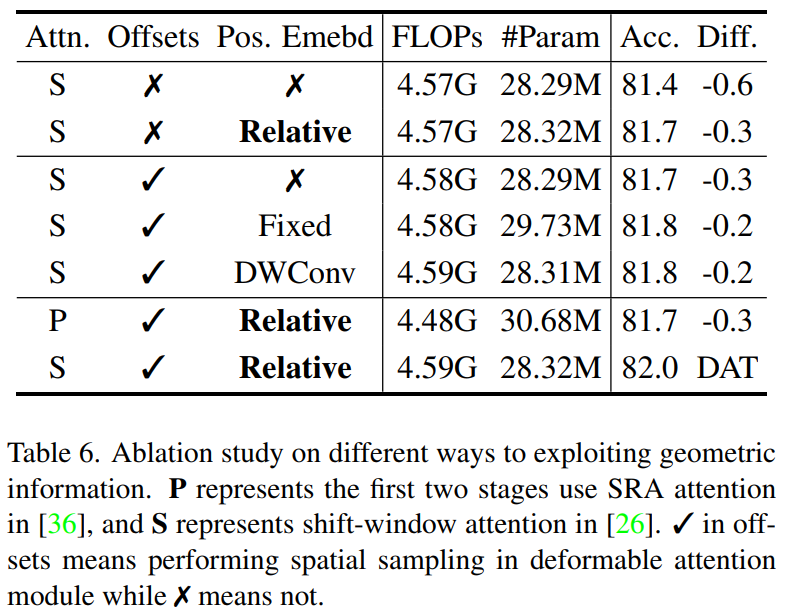
首先评估了提出的可变形偏移量和可变形相对位置嵌入的有效性,如表6所示。无论是在特征采样中采用偏移量,还是使用可变形的相对位置嵌入,都提供了+0.3的提升。作者还尝试了其他类型的位置嵌入,包括固定的可学习位置偏差中的深度卷积。但在没有位置嵌入的情况下,只提升了0.1,这表明变形相对位置偏差更符合Deformable attention。从表6中的第6行和第7行也可以看出,模型可以在前两个阶段适应不同的注意力模块,并取得有竞争的结果。SRA在前两个阶段的模型在65%的FLOPs上比PVT-M高出0.5倍。
2、不同Stage使用Deformable attention
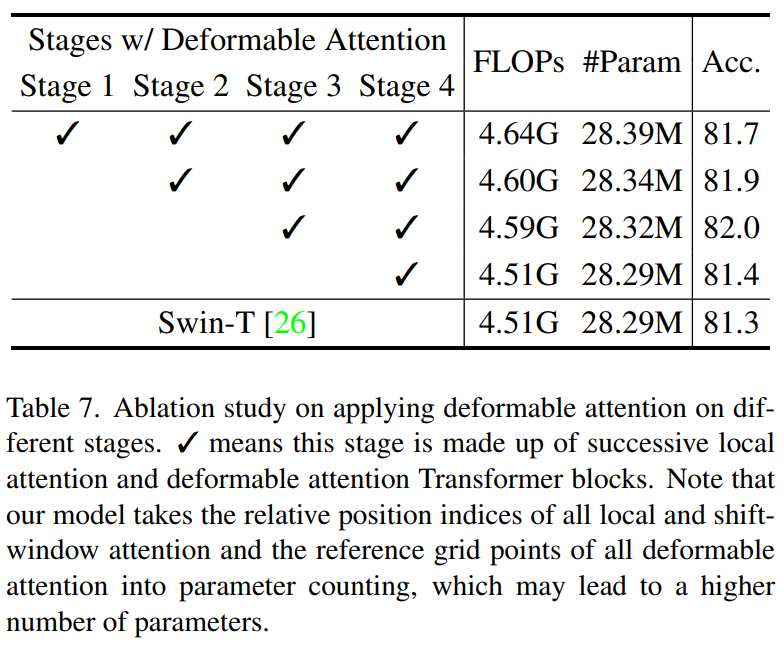
用不同阶段的Deformable attention取代了Swin Transformer shift window attention。如表7所示,只有替换最后一个阶段的注意力才能提高0.1,替换最后两个阶段的性能才能提高0.7(总体精度达到82.0)。然而,在早期阶段用更多Deformable attention代替,会略微降低精度。
4.5 可视化结果

如图所示,采样点被描述在目标检测框和实例分割Mask的顶部,从中可以看到这些点被移到了目标上。
在左边一列中,变形的点被收缩成两个目标长颈鹿,而其他的点则是保持一个几乎均匀的网格和较小的偏移量。
在中间的一列中,变形点密集地分布在人的身体和冲浪板中。
右边的一列显示了变形点对六个甜甜圈的每个焦点,这表明本文的模型有能力更好地建模几何形状,即使有多个目标。
上述可视化表明,DAT可以学习到有意义的偏移量,以采样更好的注意力key,以提高各种视觉任务的表现。
5参考
[1].Vision Transformer with Deformable Attention.
6推荐阅读

全新Backbone | Pale Transformer完美超越Swin Transformer
AI部署篇 | CUDA学习笔记1:向量相加与GPU优化(附CUDA C代码)

激活函数 | Squareplus性能比肩Softplus激活函数速度快6倍(附Pytorch实现)
长按扫描下方二维码添加小助手。
可以一起讨论遇到的问题
声明:转载请说明出处
扫描下方二维码关注【集智书童】公众号,获取更多实践项目源码和论文解读,非常期待你我的相遇,让我们以梦为马,砥砺前行!
