
腾讯云数据库海量数据交互之道
共 5919字,需浏览 12分钟
·
2022-02-19 11:31
TDSQL-A是在腾讯业务场景下诞生的在线分布型OLAP数据库系统,在处理海量数据分析业务的过程中持续对产品构架进行升级调整,是PG生态中分析型MPP产品的又一力作。
本文将由腾讯云数据库专家工程师伍鑫老师为大家详细介绍TDSQL-A的发展历程、技术架构和创新实践,以下为分享实录:
TDSQL-A发展历程
TDSQL-A是一款基于PostgreSQL自主研发的分布式在线关系型数据库。是一个面向海量数据实时在线分析产品,采用无共享MPP构架。面向分析型场景的极致性能优化,我们自研了列式存储,同时也支持行列混合存储模式。在数据转发层面上,针对大规模集群面临的连接风暴问题对集群执行/转发框架做了更深入优化,来保证可以支持超过千台规模的集群能力。同时为加速用户在数据挖掘或分析场景上的时延,通过多种计算能力优化来达到给用户提供更好效果。
在多年的发展过程中TDSQL-A依托腾讯内部业务进行充分打磨,在内部业务及外部企业级用户场景下都有良好表现,并于2021年5月18日上线腾讯云。
TDSQL-A整体架构
首先整体介绍TDSQL-A架构。TDSQL-A是一个多CN入口的MPP分布式集群设计,CN节点作为业务访问入口,每个节点是对等的,对外提供一致的用户元数据和视图访问,同时也可以通过多入口分担用户高并发压力场景下的连接处理。
因为是一个多CN入口,需要一个全局事务管理器GTM节点,进行全局事务管理以及Sequence等全局一致能力的处理节点。早期GTM在高并发情况下获取全局事务快照会有性能瓶颈,TDSQL PG版以及TDSQL-A都针对分布式提交协议做了基于timestamp的改造,解决了全局事务快照的单点瓶颈问题。TDSQL-A整体不管是行存和列存事务提交,整体的提交协议都基于timestamp(GTS)协议,提供业界领先的高并发能力支持。
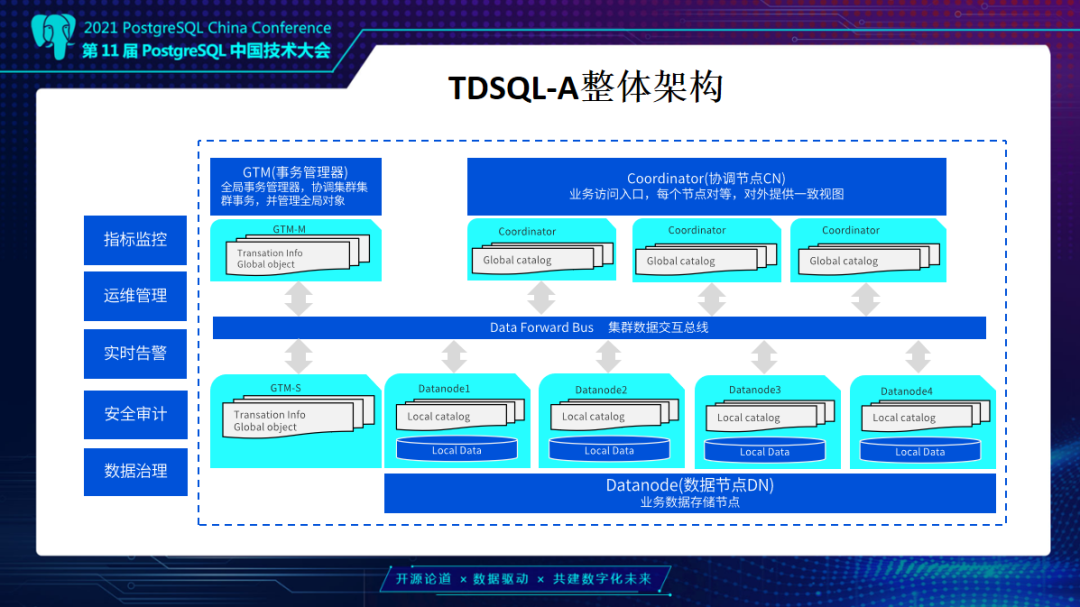
数据存储和计算节点我们称为Datenode,Datenode节点经过TDSQL-A构架优化,支持超过1000个节点以上的集群部署,支持10PB级别以上的用户数据量。同时在计算时,会尽可能把所有计算都通过智能的优化器规划推到DN节点上做计算。
TDSQL-A整体构建演进。由于用户数据量持续增大,需要面临最大挑战是在大规模集群下大数据访问量和复杂查询场景。例如TPC-DS这类复杂的用户场景,它的query是带有复杂的子查询场景及with语句的。在这种情况下多表关联会比较多,在分布式系统下会有多层重分布。
按照之前早期构架,在执行时碰到RemoteSubplan算子的时候才会往下发整体的下一步查询计划,如果查询中重分布的层次比较多,每一层DN都会认为自己是一个发起者,会导致大量多层进程连接和网络连接消耗。
做一个比较简单的计算,如果200个DN节点有100个并发查询,每个查询是5个数据重分布,计算将会有超过10万个连接数。这个问题在集群规模达到上千个节点后会更加严重,这也是整个MPP在大规模情况下的通用问题。
而TDSQL-A针对性地做了比较大的改造,首先整体执行框架进行了重构,TDSQL-A查询计划统一在CN上去做规划。当查询计划生成后,会根据Remote Subplan或需要做数据重分布这些节点,对查询计划做一个划分。不同层次会统一由CN节点到DN节点去建立相应DProcess进程,相当于有一个统一的CN协调者来管理所有进程和连接数,这样就会比较可控地去建立所需最小进程数和相应连接。同时不同进程间也可以去进行异步启动,加速复杂查询的直接效率。
实际上这里还不够,虽然进程数比较可控,但同时连接数还是一个问题,例如集群规模非常大,超过1000个节点以后,连接数膨胀还是很严重。而对于超大规模集群我们是引入了数据转发节点。数据转发节点会在每台物理机进行部署,如果有混布场景也是一个数据转发节点,会负责这台机器上所有DN或CN之前的数据交互。这样对于一个大规模计算集群,实际上网络连接数就会比较可控,因为网络会走到数据转发节点上,而机器上的DN节点或者CN节点会通过共享内存和数据转发节点进行交互。这里还有一个额外优化,如果在同一台机器有混布的情况下,相同机器上的DN交互可以不走网络,直接走共享内存做一个直接转发。
通过数据转发节点的引入整个集群规模就可以有一个比较线性和扩展能力,按照N个节点和M层Join来计算,不管你的产品多复杂它只有N*(N-1)个网络连接数,整体由FN节点去规划。很好地去解决MPP场景下,超大规模集群如何保持高并发和复杂查询场景下网络连接问题。
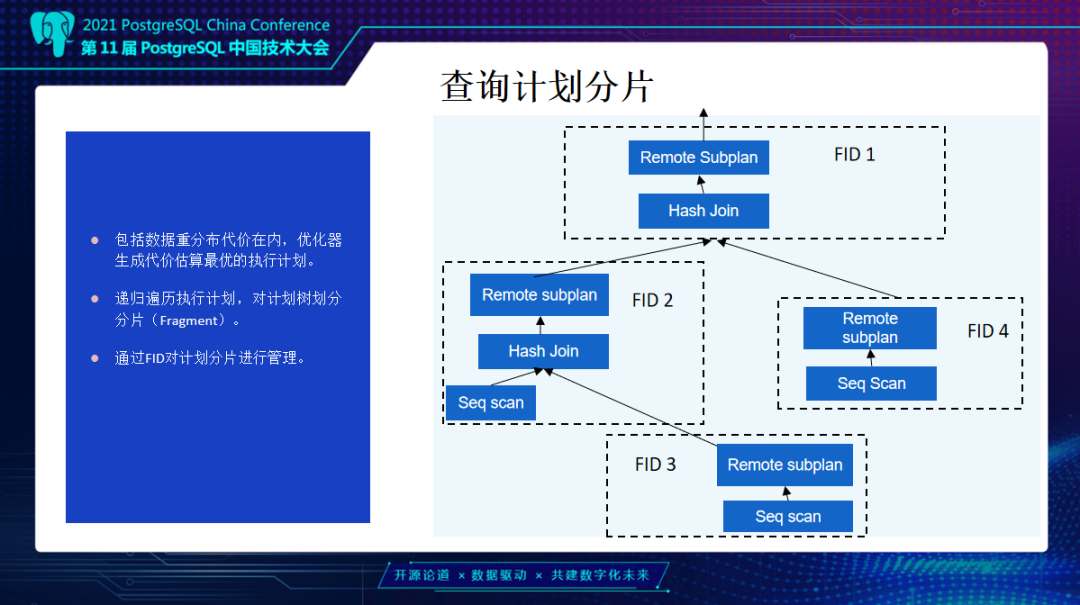
上面介绍改造之后整个查询计划分片也会比较明确。包括重分布代价在内,优化器会考虑到分布式场景中数据转发的网络开销,基于代价模型去做自动查询优化。在CN生成查询计划后会递归遍历整个执行计划树,把整个查询计划分成多个Fragment。从上面开始向下看,上面是更靠近CN节点,就是Fragmentid 1,这里缩写是FID 1,这样每次碰到Remote subplan节点时相当于需要拆分成一个新的Fragment。同一个Fragment会在每一个参与计算的DN统一去建立这样一层进程。中间是通过FN节点去进行网络传输。右边是一个比较简单的标准查询计划两个Hash Join,通过不同Fragment去分层的进行异步计算。
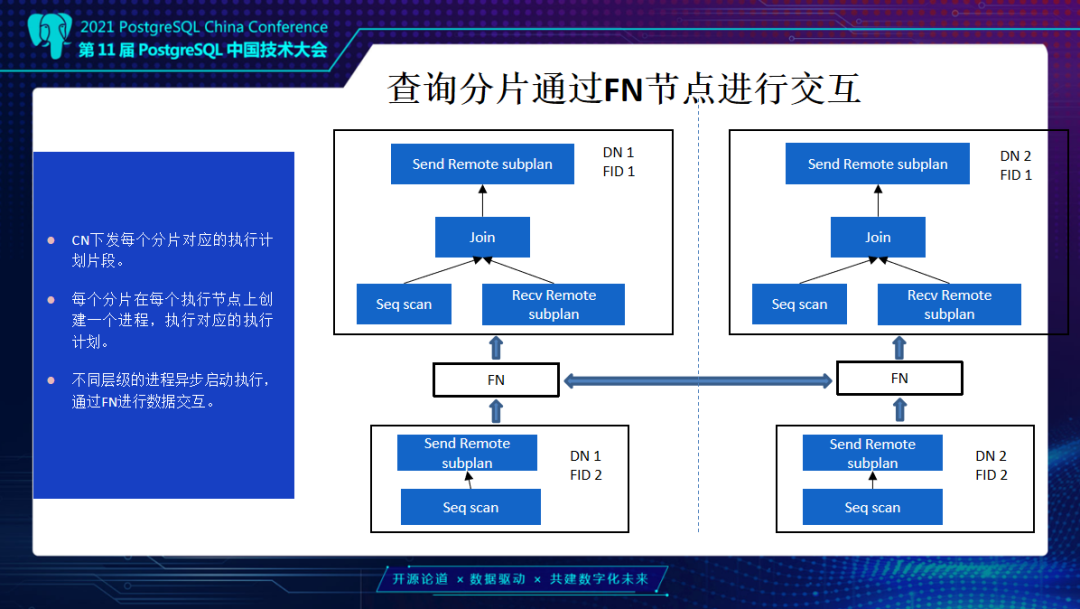
这一页主要介绍通过FN节点做一个整体数据转发,当有两个DN节点时,相当于同个Fragment会在不同DN节点建立相同进程,统一进行分布式计算,这里所有的计算也都是通过优化器去做一个相应的下推。
我们的自研列式存储,例如用户有一些星型数据模型或者一些表列数较多而实际参与计算的列比较少,这种情况很多都需要列裁剪去做执行优化,如果没有列存整体效果会比较差。通过列存尽可能减少磁盘IO扫描和相关的计算层计算裁剪。这样整体在海量数据下计算量消耗降低会比较明显。其实做优化最高效方法还是通过优化执行计划去做计算裁剪,第二步才是在必要相同计算量前提下去进行执行优化,不管是你的算子优化,还是机器资源物理层优化。最开始都要从执行计划角度去做,所以列存是非常重要的。
前面有提到我们的列存表和行存表一样,都使用了基于timestamp的分布式提交协议,所以整体行列之间可以保持混合查询事务一致性。同时用户也可以在同一个库或同一个实例里,去根据业务场景针对不同特征建立行存表和列存表,可以自动在查询计划中选择更好的access path。
这是自研列式存储格式的简单介绍,每一张列式存储表,都有一张对应的元数据registry表,去记录它存储状态和更新的状态信息。

我们的物理文件结构最小单元叫Silo,就是一个谷仓的概念,一个Silo是一个数据块列式分布的紧凑排列。这样一个Silo里面展开,会有相应的右边这些信息,除了头部信息,最上面还会有一个checksum保证数据校验的正确性,后面有标记位去加速数据访问和filter效果以及null bitmap,最后是具体的数据。
介绍一下列存储延迟扫描优化,例如有一个查询,在同一张表上有多个Predicate条件,比如10列有3列带有Predicate。按照常见的做法,这些虽然是列存储,但需要的这些列还是会提前扫描去做一个整体物化,再做一个Predicate。这种延迟扫描其实可以做更优,因为它可能对两个或三个Predicate中间层级选择率比较明显。可以先扫第一列,第一列扫完后它可能已经通过Predicate过滤掉很多数据,这时再去扫第二列或第三列时,或后面其它数据列,都可以通过ctid扫后面需要的一些数据。如果列比较多或过滤效果比较好,它会减少扫描的数据量。这是基于列存储不同列的物理文件隔离去做一个前提,因为这种情况下才能减少真正扫描量,而不是增加reaccess的问题。
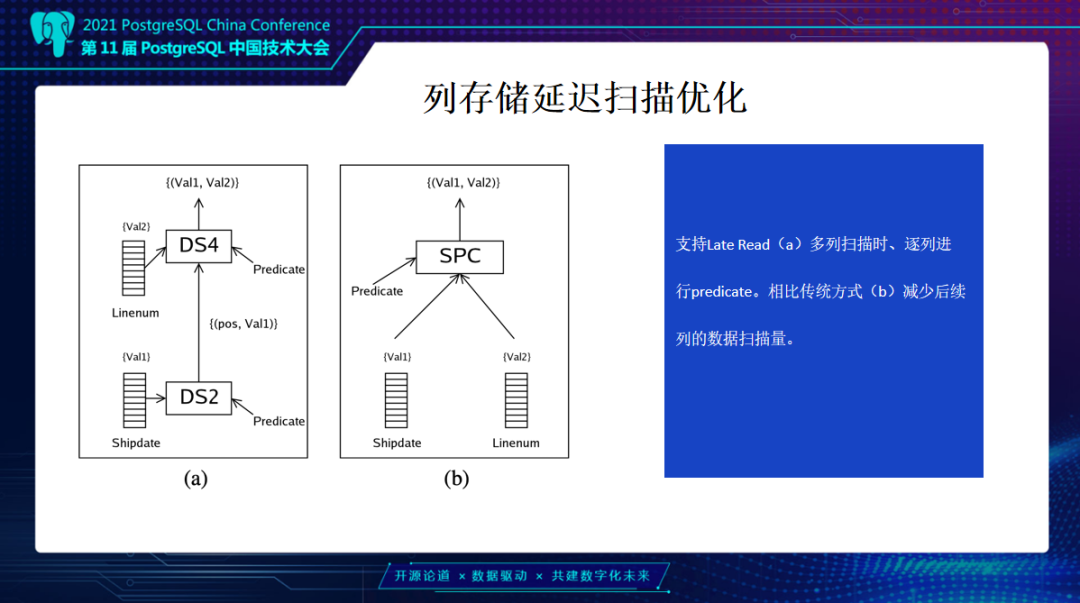
上面介绍了每一个Silo的格式,我们会尽量放更多的数据在一个Silo里,增加它的数据压缩能力。另外要引入相关压缩能力算法提高整体存储效能,降低用户存储成本。
这里有两层,首先是通用的透明压缩,透明压缩会使用LZ4或Zstd算法,针对特定数据类型会加轻量级压缩能力。同时对于不同类型我们也有不同压缩最优推荐,这是具象化到产品里的能力,用户只需要选择low、middle,或者是high,例如你希望压缩low,我们会自动替你选择相应的压缩算法。
比如整数类型,如果是low我们用Delta+RLE,middle和high就会加上Lz4或Zstd类似透明压缩。而针对Numeric也有深度优化,这里是列存压缩存储,如果你已经选择压缩,实际上它会自动转成int类型。这样不仅是存储空间节省,在你计算同时也能很快的做向量化计算能力。
介绍一下我们基于列存储和执行框架优势去深入挖掘执行引擎上的能力。首先是一个多层级并行能力,在这里分为几个层面,一个是分布式多节点和多进程执行能力,这里由FN转发能力或优化器自动规划能力去决定,当然也是由MPP整体构架来决定的。中间一层,因为现在代码整体是基于PG10来做的,但实际上我们合入了很多更新,例如PG12、PG13里的能力或并行能力,包括优化器里针对这些场景,比如说partitoin-wise Join的能力都有引入。
在中间这一层算子的并行计算能力情况下也会有比较好的效果,同时我们自己针对多种场景,比如FN能力在并行过程中遇到的一些问题,做了深入的处理。整体在基于MPP框架,超大规模MPP框架下同时对算子级进程做了深度优化。另外一个最底层的在SIMD并行指令层面进行深入的优化。
前面介绍了基于列存我们做了很多深入优化,比如前面提到的LateRead延迟扫描能力,实际上在计算层我们也有基于列存延迟物化能力,可以理解为统一把列存的特性在计算层优化到极致。
延迟物化这里介绍下,比如一个query里面有hashjoin,一般的做法是,下面Scan层会把所有的列或数据都扫进来,再去做Join计算,这是一个通用性场景。实际上如果在Join选择率比较好的情况下,对于不参与Join condition的这些列,物理扫描的那些数据列可以通过Join之后再去扫描,因为是列存储,可以Join之后再把列进行补全,这样Join在选择率很好的情况下可以减少大量的磁盘IO和网络消耗。
这里有一个简单计算,一个有20亿条数据选择率百分之一的join场景,可能会减少7.4G的无效数据传输和无效数据扫描,这个效果非常明显。类似场景下我们做了延迟物化的整体优化,在最开始扫描的时候只需要扫Join condition需要的列去做Join,Join结束后再把剩下的列数据再补全。
TDSQL-A执行引擎优化
在这里我们深入研究,一个是执行引擎框架,另外是基于优化器CBO里自动形成延迟物化相关的执行计划。如果大家对优化器比较熟会知道在这里PG的代价模型是很先进的,目前是自底向上的动态规划过程,相比于一些新的优化器使用cascade model,通用优化效果其实各有优劣。前面提到并行算子在我们合入了PG12、PG13以后,整个优化器里也引入了并行执行CBO能力。延迟物化也是持续在上面做一个优化,也就是path生成的过程中它是可以通过restriction去算出最开始扫描时只需要扫的那些列。这样生成path时只需要去构架一个辅助信息,去标记一下哪些列是需要提前物化,哪些列是可以进行延迟物化的。
这里实际有很多细化问题,例如延迟物化常见问题,如果有更多算子导致reaccess的场景,效果可能会下降,这在CBO里都有考虑。例如Hashjoin的落盘情况下以及RemoteSubplan都可能会有乱序问题,在这里我们都有相应的考虑在里面,所以整体会是一个基于CBO比较智能的延迟物化能力。
前面多个点提到了向量化执行引擎整体设计,向量化和SIMD是一个更核心方向。在这里我们自研了整套向量化执行引擎,可以支持TPC-DS及更复杂的查询场景,让复杂查询全都执行在向量化执行引擎上面。
在Hash Agg或者表达式计算等场景下,我们会去做针对列存储和向量化技术做联合优化,比如numeric转换成定长类型。同时还去针对向量化内存结构 做了深入优化,比如说SIMD和向量化效果到底能有多少,其实和数据编排有非常大关联性。更好的数据编排以及算子实现可以减少CPU Cache miss。在这里我们花了比较多的精力在内存编排上。这些都是原生在内核里去实现。同时在算子上也是自己去单独拉出一套向量化执行引擎算子,在SIMD场景下针对算子细节和其他典型场景都有SIMD指令引入,保证在多个层次上,从数据编排的基础到算子核心,再到SIMD整体都进行了深入优化。
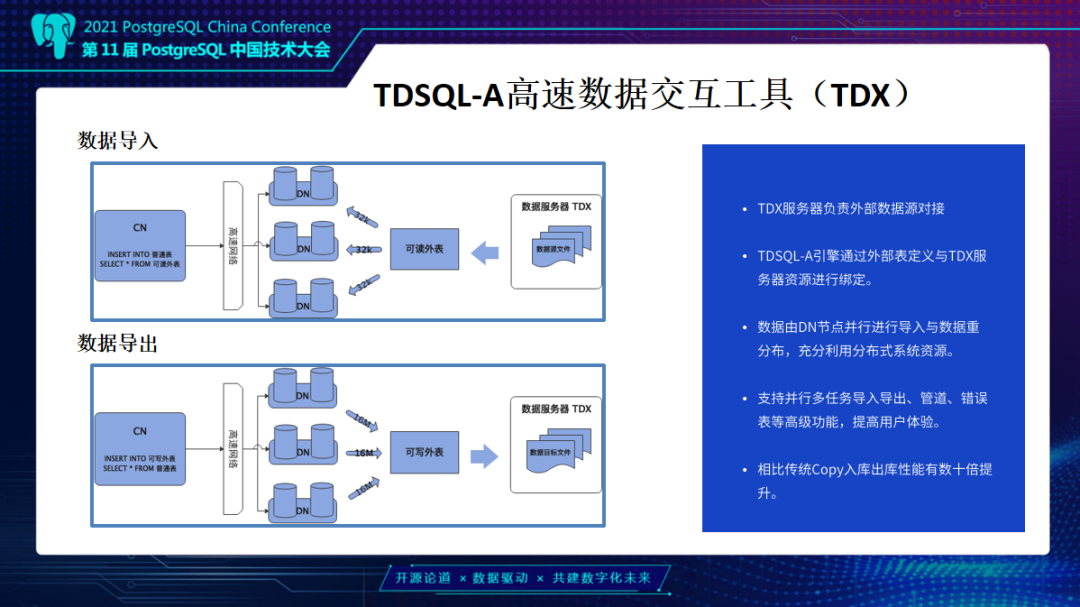
同时做为分析型产品,可能更多在交易系统后端链路上,需要去接入不同数据源保证可以有更多的适应性场景,如果沿用原有的Copy模式性能就会比较差。
所以我们针对分布式MPP场景去做了高速数据交互工具TDSQL-TDX,这是借助一个数据服务器,让TDX统一去处理DN的数据请求,DN去访问TDX取到切分的数据分片,就可以达到基于DN个数并行的进行数据交互。
另外这个工具也支持数据导出,相比传统用的Copy模式有数十倍的提升。另外我们也将持续对TDX工具进行优化,支持更多生态。
未来规划
前面介绍了很多构架升级包括一些细化能力,当然我们还有更多的点可以继续深入细化。例如在SIMD覆盖场景上增强,深入对列存储格式编排和向量化执行引擎做深度优化还有更进一步的空间。同时也希望继续可以和PG生态做一个持续融合,比如并行或其它的算子能力,都将持续融合PG社区能力,同时也会考虑整体把code base去进行持续升级。
最后一个点是Oracle兼容能力,实际内核能力上TDSQL PostgreSQL版整体Oracle兼容能力是非常强的,我们也会持续在相关能力融合和能力进行提升。对于国产MPP或类似Oracle替代场景,因为Oracle不仅是做为交易型,可能很多厂商都是混合场景,而我们做为一个MPP也可以支持Oracle兼容能力,可以打开更多的适应性场景。
﹀
﹀
﹀

揭秘TDSQL-A:兼容Oracle的同时支持海量数据交互

十问十答,带你全面了解TDSQL-A核心优势
↓↓点击阅读原文,了解更多优惠