当今的数据集越来越大,台式机的内存甚至都装不下,更不用说你的笔记本电脑了,尽管如此,在大数据时代,我们总是避免不了要使用大数据集,于是Vaex诞生了。Vaex是一个高性能Python库,可以可视化和探索大型表格数据集,它可以在 N 维网格上计算每秒超过十亿(10^9)个对象 / 行的统计信息,例如均值、总和、计数、标准差等, 磁盘上大小超过100GB的数据,用Vaex只需要0.052秒就可以打开。使用直方图、密度图和三维体绘制完成可视化,从而可以交互式探索大数据。Vaex 使用内存映射、零内存复制策略获得最佳性能(不浪费内存)。基于Python数据科学站(例如Panda、Scikit-Learn、arrow、xgboost、lightgbm),标准API易于采用。为Jupyter环境量身定制。
电脑运算,结合了内存映射,复杂的表达系统和快速核外算法。有效地可视化和探索大型数据集,并在一台机器上构建机器学习模型。
基准测试,每秒可视化10亿个样本。与标准实现相比,PCA转换速度提高了10倍,可在2分钟内处理10亿个样本。完全超出核心。
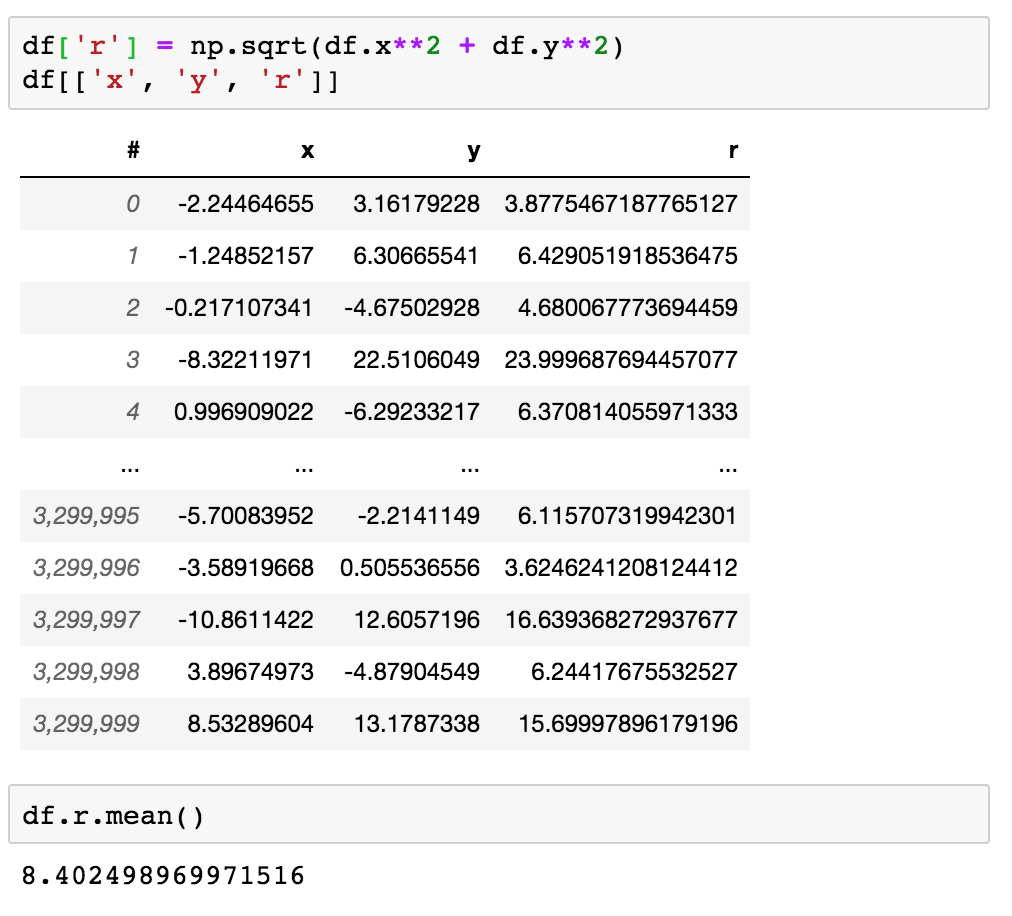
Vaex不仅仅是Panda的替代品。尽管在执行诸如的表达式时,它具有类似于panda的API用于列访问np.sqrt(ds.x**2 + ds.y**2),但不会进行任何计算。而是创建一个vaex表达式对象,并在打印输出时显示一些预览值。

使用表达式系统,vaex仅在需要时执行计算。同样,数据也不必是本地的:表达式可以通过发送的方式,统计信息可以远程计算,这是vaex-server程序包提供的。我们还可以将表达式添加到DataFrame中,从而生成虚拟列。虚拟列的行为类似于常规列,但不占用任何内存。Vaex在实列和虚列之间没有区别,
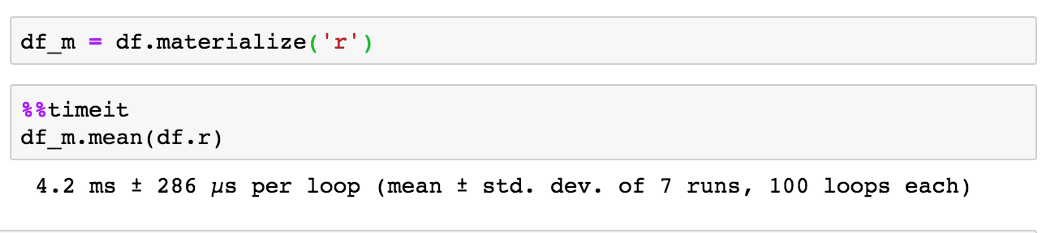
如果表达式在运行时真的很复杂怎么办?通过使用Pythran或Numba,我们可以使用手动实时(JIT)编译来优化计算。

远程数据帧甚至支持JIT版本的表达式,担心RAM不够?你还可以选择以RAM为代价挤出额外的性能。
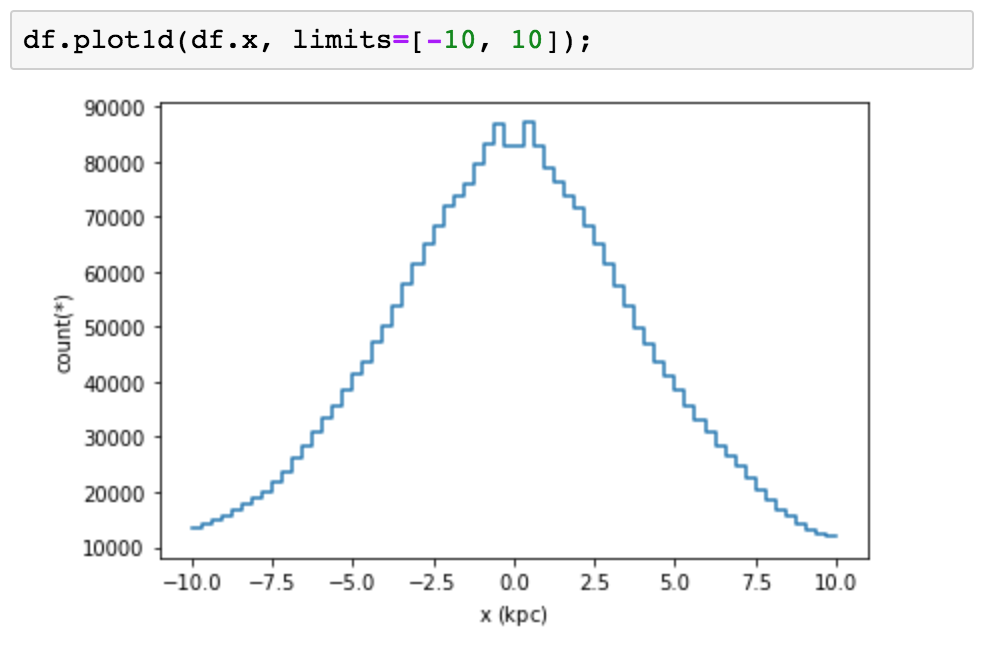
进行有意义的绘图和可视化是了解数据的最佳方法。。但是,当你的DataFrame包含10亿行时,制作标准散点图不仅会花费很长时间,而且会导致毫无意义且难以理解的可视化。让我们看看这些想法的一些实际例子。我们可以使用直方图可视化单个列的内容。
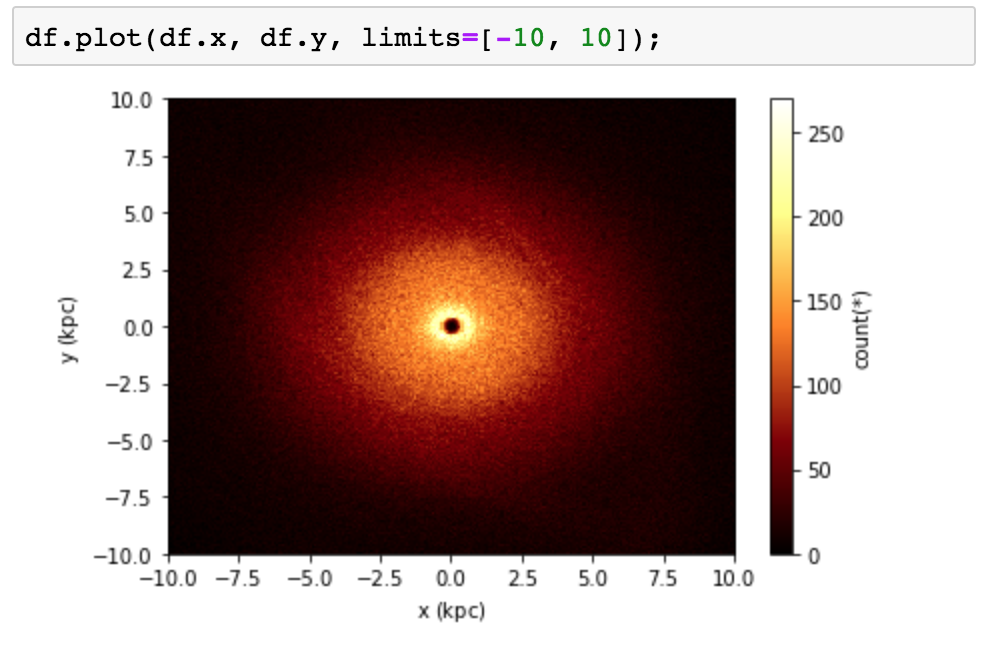
可以将其扩展为两个维度,从而生成热图。我们可以像典型的热图那样简单地计算落入每个样本中,而不是计算平均值,取总和的对数或几乎任何自定义统计量。
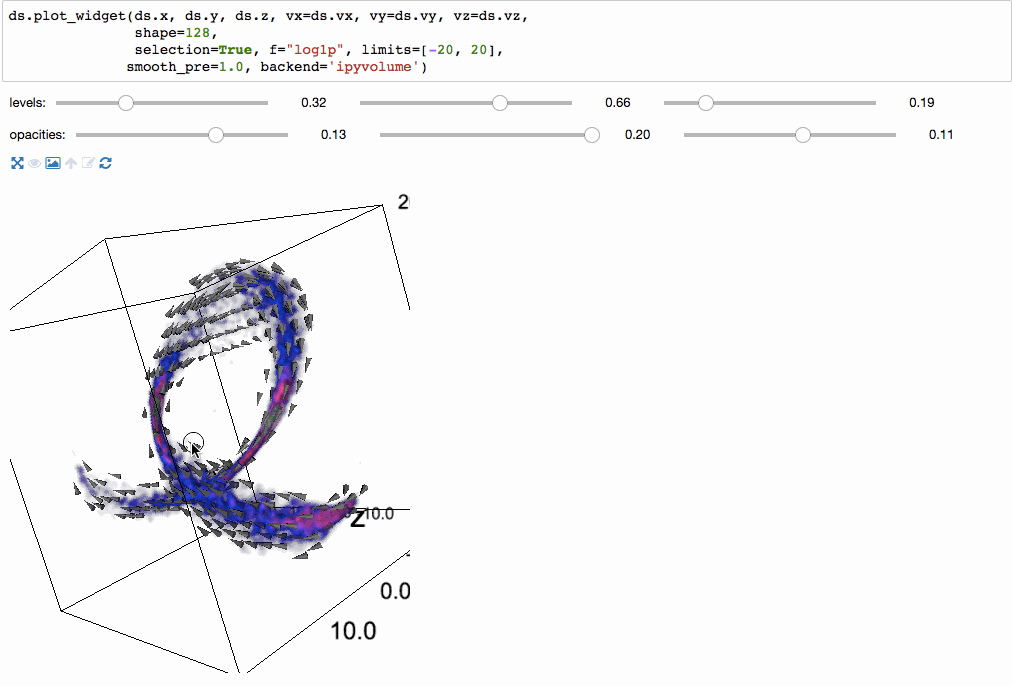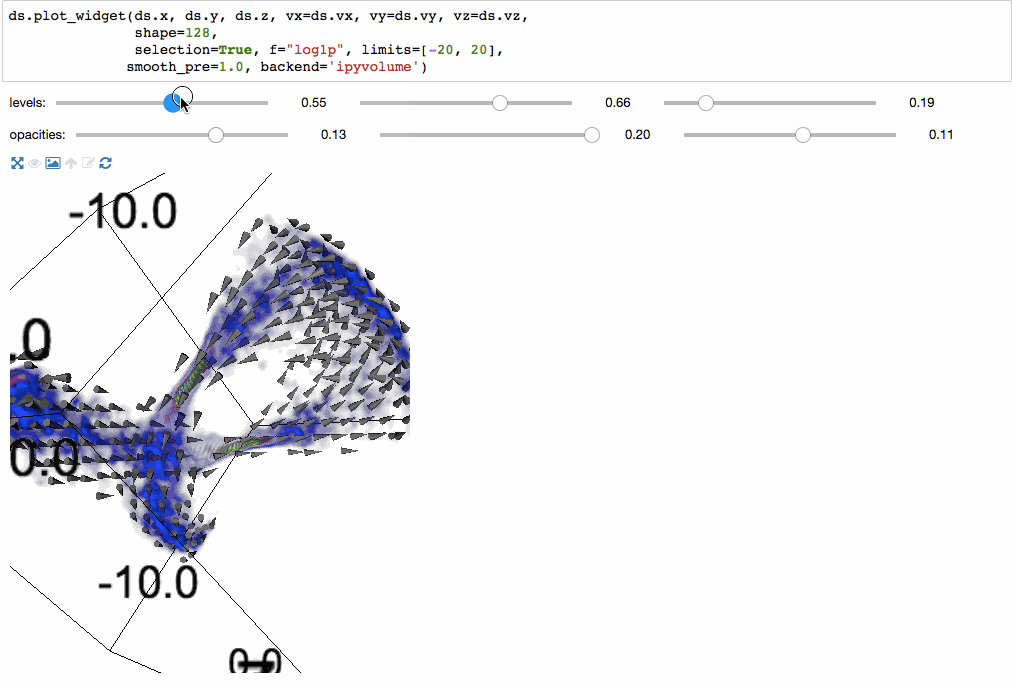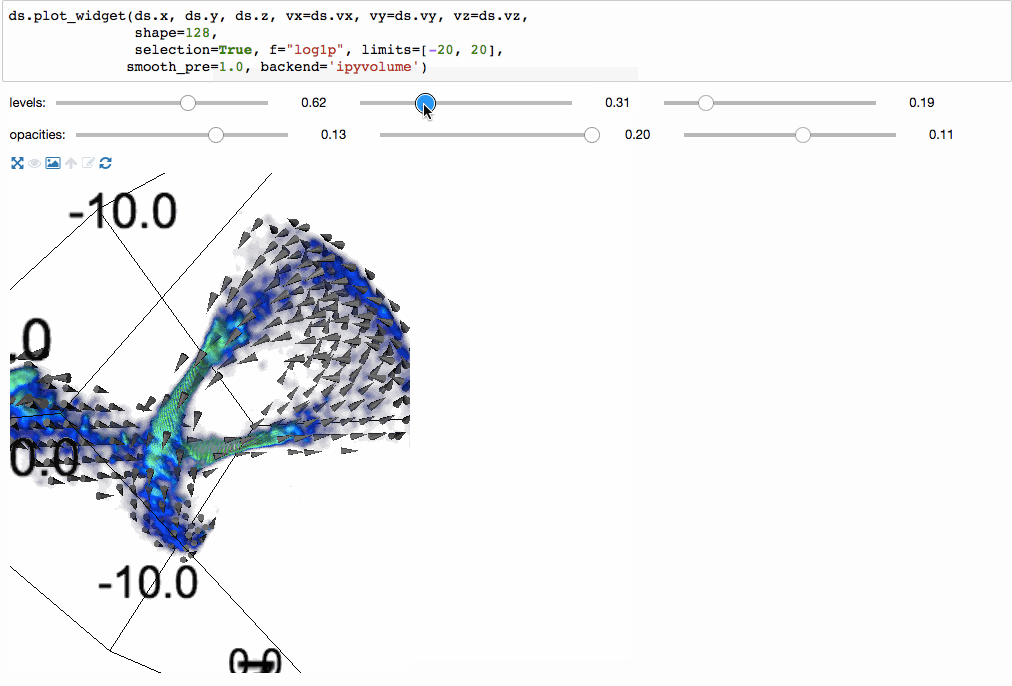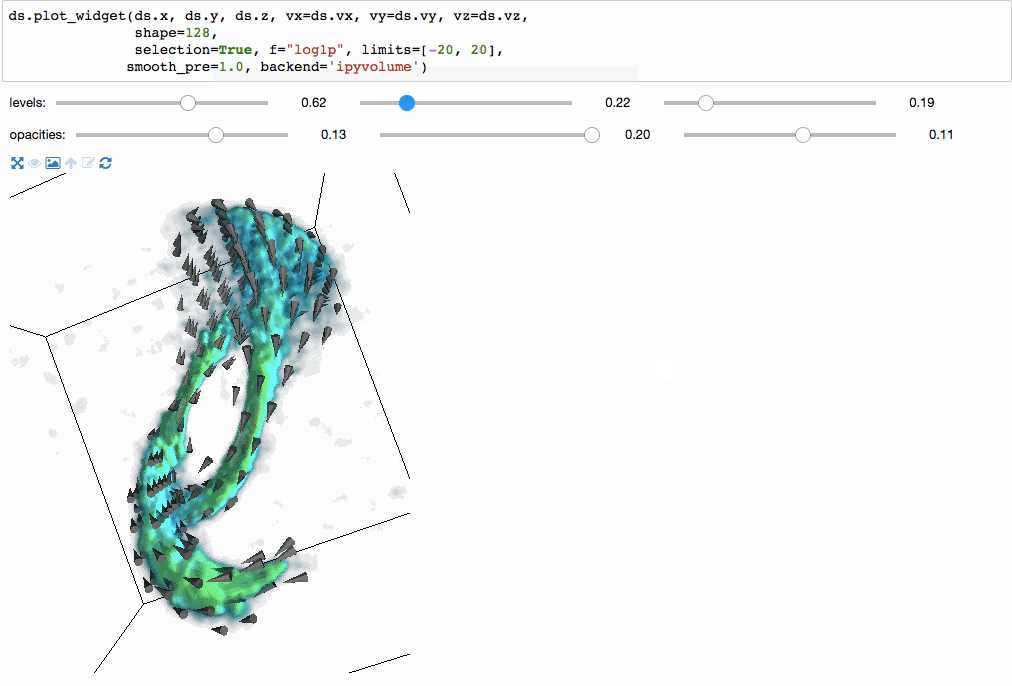
我们甚至可以使用ipyvolume进行3维体积渲染。
Vaex 官方网站:https://vaex.io/
文档:https://docs.vaex.io/
GitHub:https : //github.com/vaexio/vaex
PyPi:https://pypi.python.org/pypi/vaex/
来源:开源最前线(ID:OpenSourceTop)
版权申明:内容来源网络,版权归原创者所有。除非无法确认,我们都会标明作者及出处,如有侵权烦请告知,我们会立即删除并表示歉意。谢谢!