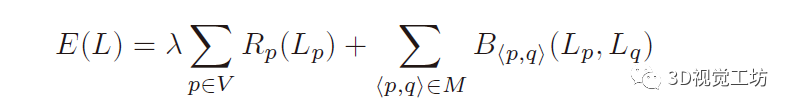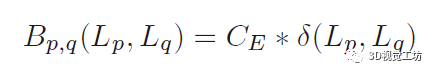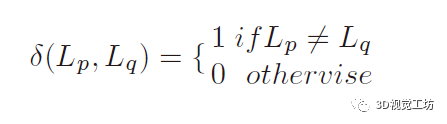从传统到深度学习:浅谈点云分割中的图结构
共
3081字,需浏览
7分钟
·
2021-07-19 04:09
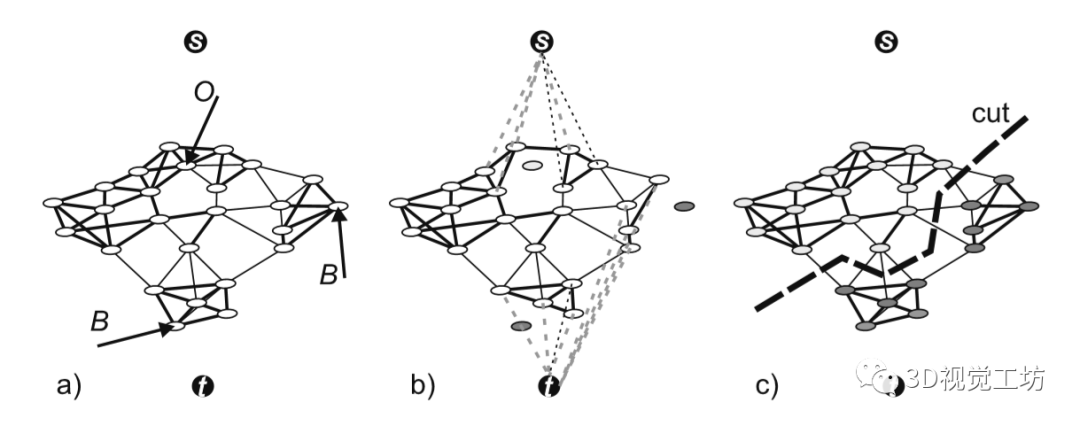
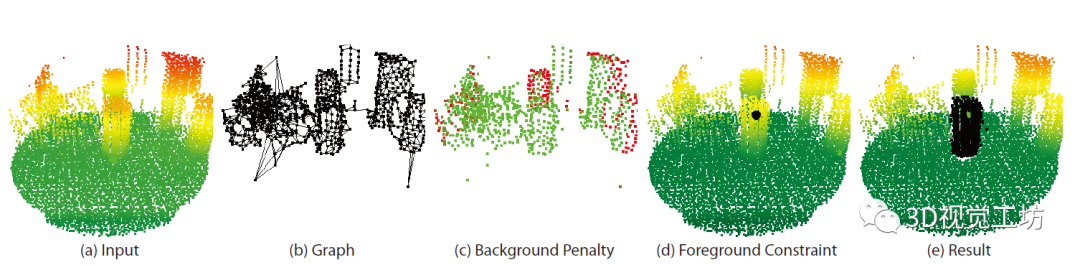
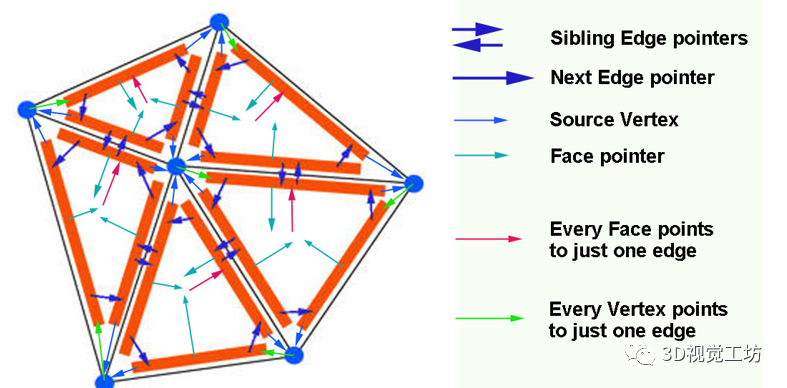
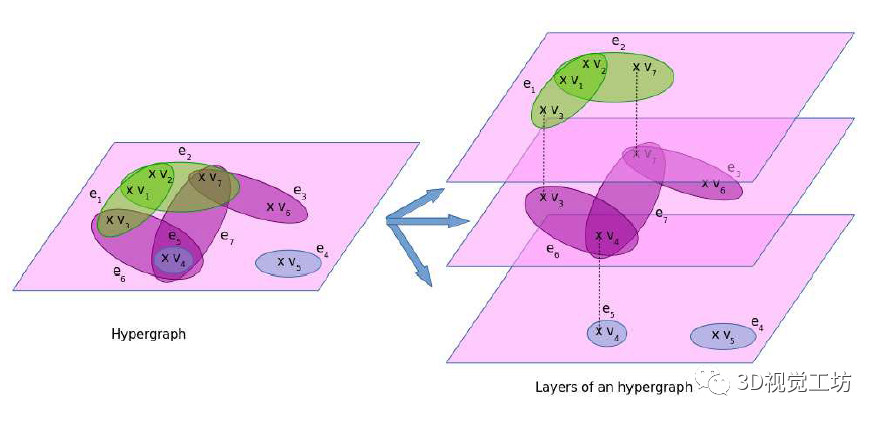
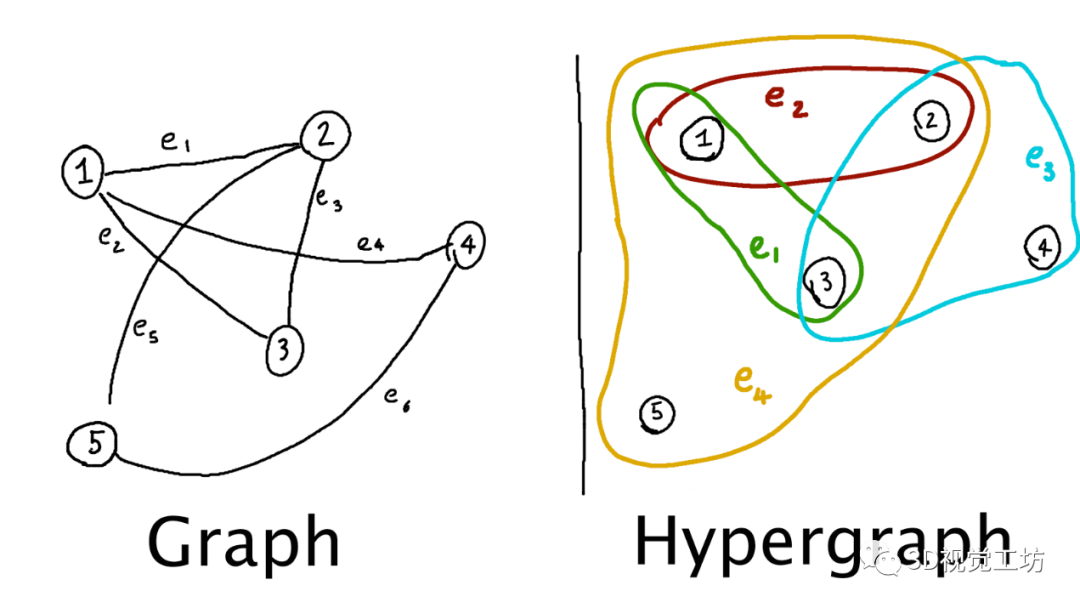
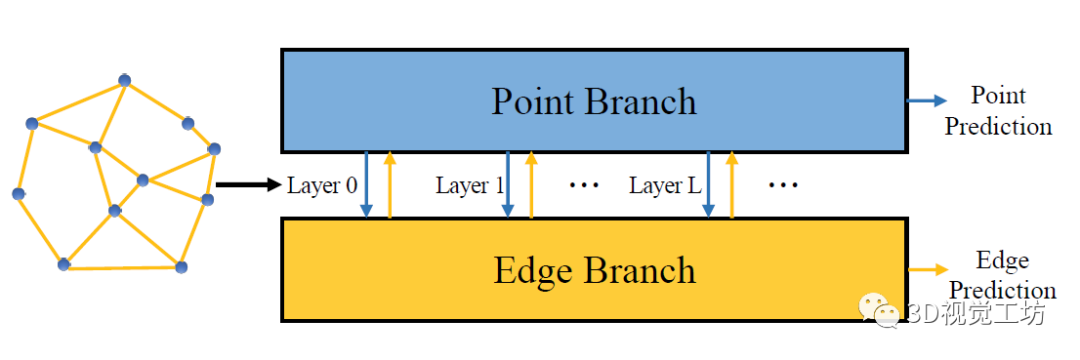
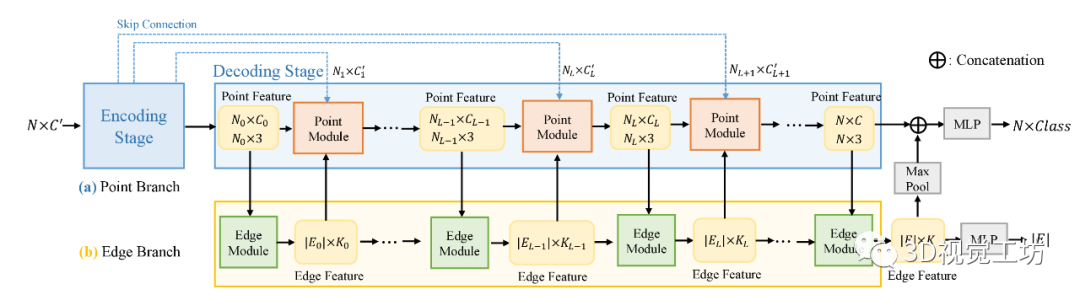
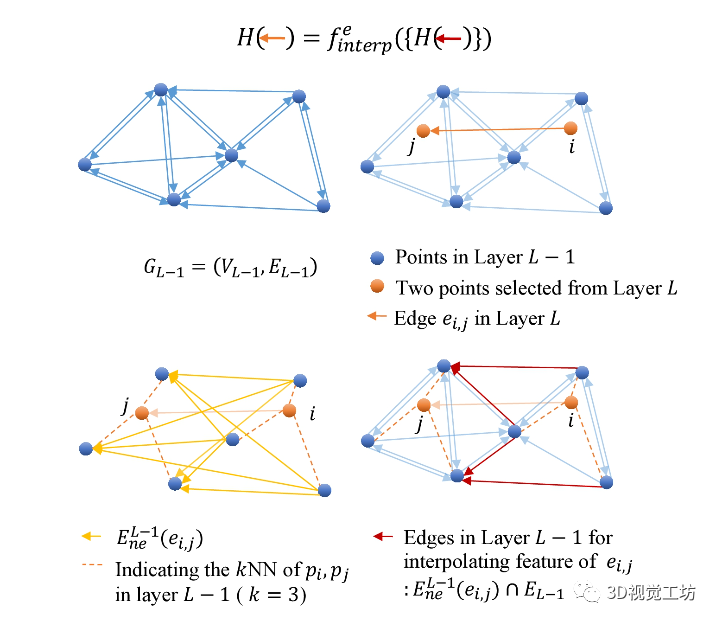
随着3D扫描技术的进步,如何将点云的前景和背景正确分离成为点云处理的一个具有挑战性的问题。具体来说,就是给定一个对象位置的估计,目标是识别属于该对象的那些点,并将它们与背景点分开。除了将前景与背景分离的基本任务外,分割还有助于定位、分类和特征提取。根据人类视觉感知的原理,一个典型的2D图像的图割问题如图1所示。图1 一个典型的图拓扑结构和分割示例。顶点(白点)在这里与5个最近的近邻点相连。边的成本由边的粗细反映。a)对象点和箭头所指向的背景点。b)种子点被相应的终端替换,新创建的终端边继承先前连接的种子点权重。c)图分割。浅灰色的顶点为前景对象,深灰色的是背景对象。利用分割技术来识别空间上不均匀的连续区域,识别和图像索引等更高层次的问题也可以利用匹配中的分割结果,但在3D点云中分割对象的问题是具有挑战性的。例如前景通常与背景高度纠缠在一起,另外真实世界的数据具有大量噪点,采样不均匀等特点,例如地面扫描的点密度在扫描方向上较为密集,而周围较为稀疏;机载扫描对几乎垂直的表面采样则很差。此外,受设备自身技术参数的影响,使用不同设备采集得到的点云数据会导致不同物体之间的采样率存在相当大的差异,并且通常出现在同一物体的不同表面。受到计算机视觉和计算机图形学中图割技术的启发,众多学者将基于图切割的方法应用于点云的前景和背景分离,从而将3D表面分解为多个部分。虽然点云中的图割方法是图像技术的扩展。但与图像技术明显不同,颜色或纹理信息一般不在点云的图割问题中使用,并且与大多数计算机图形分割问题不同,点云处理的输入端是表示带有大量自然噪点的场景点云,而不是具有光滑表面的单个对象模型。传统点云方法中基于最小图割的分割方法通常在点云上创建一个最近邻图来实现,定义一个惩罚函数来判断平滑分割,其中前景与背景采用弱连接,并用最小切割最小化该函数。一个通用的表示即:用G=<V,E>表示要分割的点云,V和E分别是顶点(vertex)和边(edge)的集合。普通的图由顶点和边构成,如果边的有方向的,这样的图被则称为有向图,否则为无向图,且边是有权值的,不同的边可以有不同的权值,分别代表不同的物理意义。同时,每条边都有一个非负的权值,也可以理解为cost,这里的cost函数是需要人为定义的。一个cut(割)就是图中边集合E的一个子集C,那这个割的cost(表示为|C|)就是边子集C的所有边的权值的总和。一般可以用类似下面公式的一个能量函数E(L)描述点云图割问题。能量函数定义为:L = {Lp|p∈V}是点云V的label。系数λ≥0用来指定区域项Rp()与边界属性项B <p,q>的相对重要性。将来自V的所有N个最近邻对定义为集合M。以上部分可以说是老生常谈,其实最重要的是如何解决这个优化问题。某些情况下该问题为一个NP-hard问题,感兴趣的朋友可以去了解一下该问题的求解方法,可以先从一个简单的二元优化问题入手。随着相关学者的进一步深入,后续又出现了新的图结构,比如下面的这种半边图结构。该图结构将多边形存储为顶点的双向链表可以方便地支持算法中处理多边形所需的许多操作。例如,当将两个跨切线的凸多边形组合成一个更大的凸多边形时(例如在需要进行分而治之的凸包算法中),处理速度将变得非常快。这种半边数据结构也称作双连接边列表(DCEL),是一种数据结构,用于表示平面图在平面中的嵌入,以及3D中的多面体。这种数据结构提供了对象(顶点、边、面)相关联的拓扑信息。再比如上图所示的超图(Hypergraph),一个(无向)超图H=(V,E)在n个顶点(或顶点)的有限集合V = {v1 , v2, ... ,vn}上被定义为p个超边的集合E={e1,e2, ...,ep}。其中每个超边都是V的非空子集。设H=(V,E)是一个超图,w是一个权重,使得每个超边e∈E映射到一个实数w(e)。超图Hw = (V,E,w)被称为加权超图。简单的来说,相比较普通图而言,它的一个边(edge)只能和两个顶点连接;而对于超图来讲,人们定义它的边(这里叫超边,hyperedge)可以和任意个数的顶点连接。一个图和超图的示意图如图5所示:随着深度学习技术的发展,研究人员的工作重心又转向了如何将图结构部署到深度学习网络当中去,一个典型的例子是2019年ICCV的一篇文章《Hierarchical Point-Edge Interaction Network for Point Cloud Semantic Segmentation》。在这篇文章中,作者提出了一种边分支结构,从而为point branch提供上下文信息;同时,作者还利用分层图结构,实现一个由粗到细的信息生成过程。图6 所提框架的简单说明。点分支和边缘分支一起用来预测语义标签。文章的主要贡献就是探究局部区域中点之间的语义关系并利用上下文信息,作者显式地在点与它们的上下文邻居之间建立边缘,并建立具有辅助边缘损失的分层边缘分支,如图6所示。具体来说,除了PointNet ++中的编码器-解码器点分支之外,所提出的新边缘分支还接受来自不同层的点特征,并逐步生成边缘特征,然后将其馈送到点分支以在局部图中融合信息。对于每个点,相应的边缘特征提供局部固有的几何和区域语义信息以增强点表示。图7 总体架构。N表示原始点云中的点数。N的下标是层索引。较大的索引表示具有更多点的图层。C表示点要素通道的数量。K表示边缘特征通道的数量。E表示边集。边缘特征是从最粗糙的层0开始编码的,并逐渐被后来的层的点特征所精炼。不同层中的边缘要素也参与相应的点模块以提供上下文信息。图8 边缘向上采样的演示。i,j为经过点模型新增加的点,通过寻找i,j的共同近邻来作为新增边的特征。图中第三副就是i近邻点的特征边,第四幅图中红色的边就是两个点近邻共同拥有的边。关于点云中的图结构还有很多相关paper,感兴趣的小伙伴下来可以自己查找学习。初衷
3D视觉工坊是基于优质原创文章的自媒体平台,创始人和合伙人致力于发布3D视觉领域最干货的文章,然而少数人的力量毕竟有限,知识盲区和领域漏洞依然存在。为了能够更好地展示领域知识,现向全体粉丝以及阅读者征稿,如果您的文章是3D视觉、CV&深度学习、SLAM、三维重建、点云后处理、自动驾驶、三维测量、VR/AR、3D人脸识别、医疗影像、缺陷检测、行人重识别、目标跟踪、视觉产品落地、硬件选型、求职分享等方向,欢迎砸稿过来~文章内容可以为paper reading、资源总结、项目实战总结等形式,公众号将会对每一个投稿者提供相应的稿费,我们支持知识有价!投稿方式
邮箱:vision3d@yeah.net 或者加下方的小助理微信,另请注明原创投稿。
点赞
评论
收藏
分享

手机扫一扫分享
举报
点赞
评论
收藏
分享
手机扫一扫分享
举报