
BatchNorm的避坑指南(下)
 点蓝色字关注“机器学习算法工程师”
点蓝色字关注“机器学习算法工程师”
设为星标,干货直达!
Batch from Different Domains
包含BatchNorm的模型训练过程包含两个学习过程:一是模型主体参数是通过SGD学习得到的(SGD training),二是全局统计量是通过EMA或者PreciseBN从训练数据中学习得到(population statistics training)。当训练数据和测试数据分布不同时,我们称之为domain shift,这个时候学习得到的全局统计量就可能会在测试时失效,这个问题已经有论文提出要采用Adaptive BatchNorm来解决,即在测试数据上重新计算全局统计量。这里还是以ResNet50为例(SGD batch size为1024,NBS为32),用ImageNet-C数据集(ImageNet的扰动版本,共三种类型:contrast,gaussian noise和jpeg compression)来评估domain shift问题,结果如下:
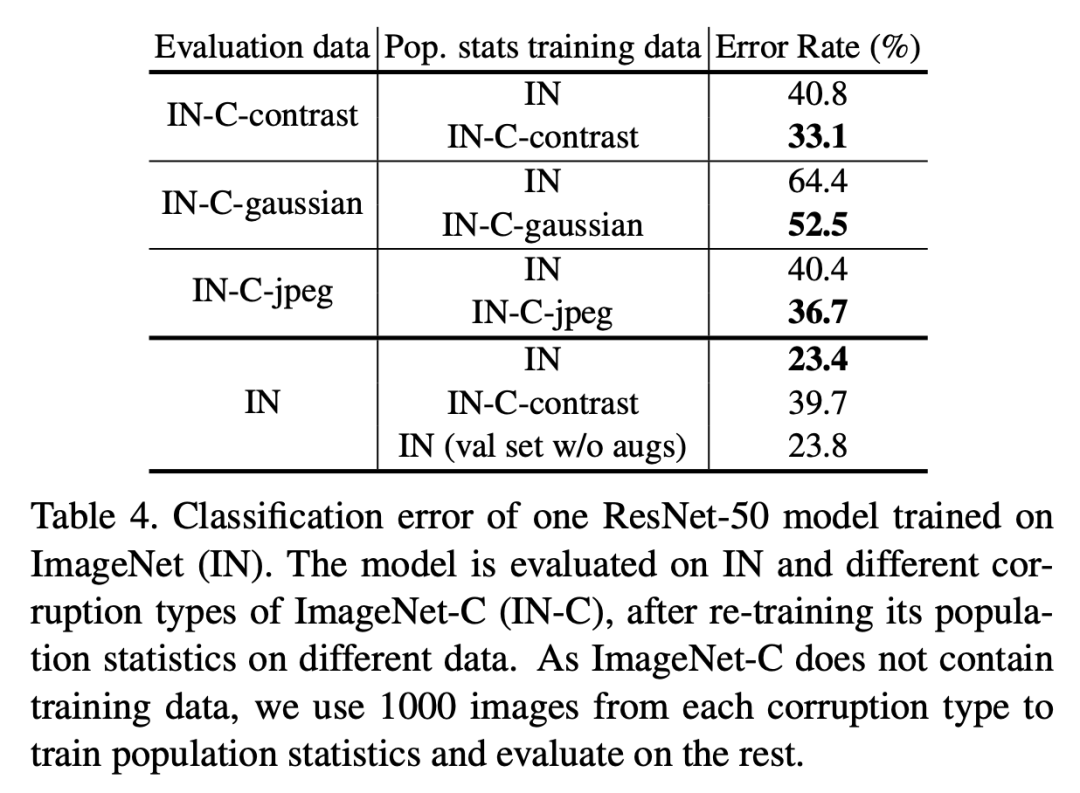
从表中可以明显看出:当出现domain shift问题后,采用Adaptive BatchNorm在target domain数据集上重新计算全局统计量可以提升模型效果。不过从表最后一行可以看到,如果在ImageNet验证集上重新计算统计量(直接采用inference-time预处理),最终效果要稍微差于原来结果(23.4 VS 23.8),这可能说明如果不存在明显的domain shift,原始处理方式是最好的。
除了domain shift,训练数据存在multi-domain也会对BatchNorm产生影响,这个问题更复杂了。这里以RetinaNet模型来说明multi-domain的出现可能出现的问题。RetinaNet的head包含4个卷积层以及最终的分类器和回归器,其输入是来自不同尺度的5个特征(),这可以kan'chehead在5个特征上是共享的,默认head是不包含BatchNorm,当我们在每个卷积后加上BatchNorm后,问题就变得复杂了。首先,首先就是训练过程mini-batch统计量的计算,明显有两种不同处理方式,一是对不同domain的特征输入单独计算mini-batch统计量并单独归一化,二是将所有domain的特征concat在一起,计算一个mini-batch统计量来归一化。这两种处理方式如下所示:
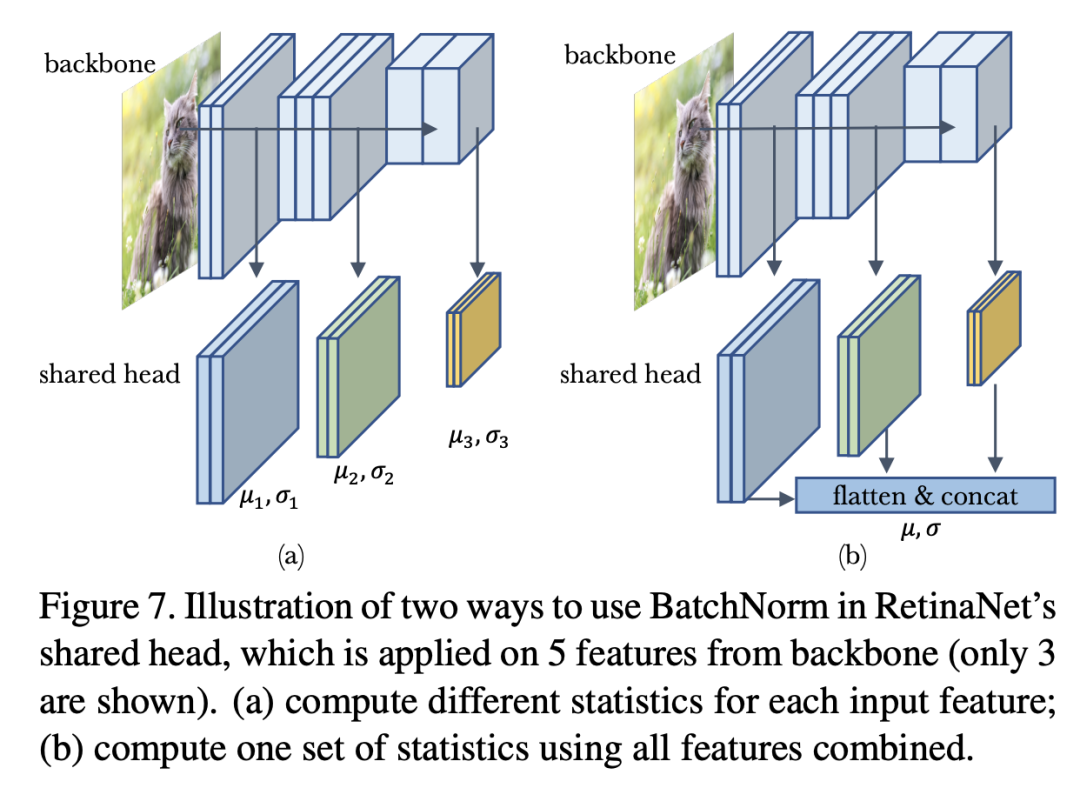
这里记SGD训练过程中的两种方式分别为domain-specific statistics和shared statistics。对于学习全局统计量,同样存在对应的两种方式,即每个domain的特征单独学习一套全局统计量,还是共享一套全局统计量。对于BatchNorm的affine transform layer也存在两种选择:每个domain一套参数还是共享参数。不同组合的模型效果如下表所示:

从表中结果可以总结两个结论:(1)SGD training和population statistics training保持一致非常重要,此时都可以取得较好的结果(行1,行4和行6);(2)affine transform layer无论单独参数还是共享基本不影响结果。这里的一个小插曲是如果直接在head中加上BatchNorm,其实对应的是行3,其实这是因为不同尺度的特征是序列处理的,这就造成了SGD training其实是domain-specific的,此时效果就较差,所以大部分实现中要不然不用norm,要不然就用BatchNorm。不同组合的实现代码如下:
# 简单地加上BN,注意forward时,不同特征是串行处理的,那么SGD training其实是domain-specific的,
# 但是只维持一套全局统计量,所以测试时又是共享的
class RetinaNetHead_Row3:
def __init__(self, num_conv, channel):
head = []
for _ in range(num_conv):
head.append(nn.Conv2d(channel, channel, 3))
head.append(nn.BatchNorm2d(channel))
self.head = nn.Sequential(∗head)
def forward(self, inputs: List[Tensor]):
return [self.head(i) for i in inputs]
# 如果要共享,那么在forward时对特征进行concat来统一计算并归一化
class RetinaNetHead_Row1(RetinaNetHead_Row3):
def forward(self, inputs: List[Tensor]):
for mod in self.head:
if isinstance(mod, nn.BatchNorm2d):
# for BN layer, normalize all inputs together
shapes = [i.shape for i in inputs]
spatial_sizes = [s[2] ∗ s[3] for s in shapes]
x = [i.flatten(2) for i in inputs]
x = torch.cat(x, dim=2).unsqueeze(3)
x = mod(x).split(spatial_sizes, dim=2)
inputs = [i.view(s) for s, i in zip(shapes, x)]
else:
# for conv layer, apply it separately
inputs = [mod(i) for i in inputs]
return inputs
# 另外一种简单的处理方式是每个特征采用各自的BN
class RetinaNetHead_Row6:
def __init__(self, num_conv, channel, num_features):
# num_features: number of features coming from
# different FPN levels, e.g. 5
heads = [[] for _ in range(num_levels)]
for _ in range(num_conv):
conv = nn.Conv2d(channel, channel, 3)
for h in heads:
# add a shared conv and a domain−specific BN
h.extend([conv, nn.BatchNorm2d(channel)])
self.heads = [nn.Sequential(∗h) for h in heads]
def forward(self, inputs: List[Tensor]):
# end up with one head for each input
return [head(i) for head, i in
zip(self.heads, inputs)]
对于行2和行4,可以通过训练好的行1和行3模型重新在训练数据上计算domain-specific全局统计量即可,在实现时,可以如下:
class CycleBatchNormList(nn.ModuleList):
"""
A hacky way to implement domain-specific BatchNorm
if it's guaranteed that a fixed number of domains will be
called with fixed order.
"""
def __init__(self, length, channels):
super().__init__([nn.BatchNorm2d(channels, affine=False) for k in range(length)])
# shared affine, domain-specific BN
self.weight = nn.Parameter(torch.ones(channels))
self.bias = nn.Parameter(torch.zeros(channels))
self._pos = 0
def forward(self, x):
ret = self[self._pos](x)
self._pos = (self._pos + 1) % len(self)
w = self.weight.reshape(1, -1, 1, 1)
b = self.bias.reshape(1, -1, 1, 1)
return ret * w + b
# 训练好模型,我们可以重新将BN层换成以上实现,就可以在训练数据上重新计算domain-specific全局统计量
RetinaNet面临的其实是特征层面的multi-domain问题,而且每个batch中的各个domain是均匀的。如果是数据层面的multi-domain,其面临的问题将会复杂,此时domain的分布比例也是多变的,但是总的原则是尽量减少不一致性,因为consistency is crucial。
Information Leakage within a Batch
BatchNorm面临的另外一个挑战,就是可能出现信息泄露,这里所说的信息泄露指的是模型学习到了利用mini-batch的信息来做预测,而这些其实并不是我们要学习的,因为这样模型可能难以对mini-batch里的每个sample单独做预测。
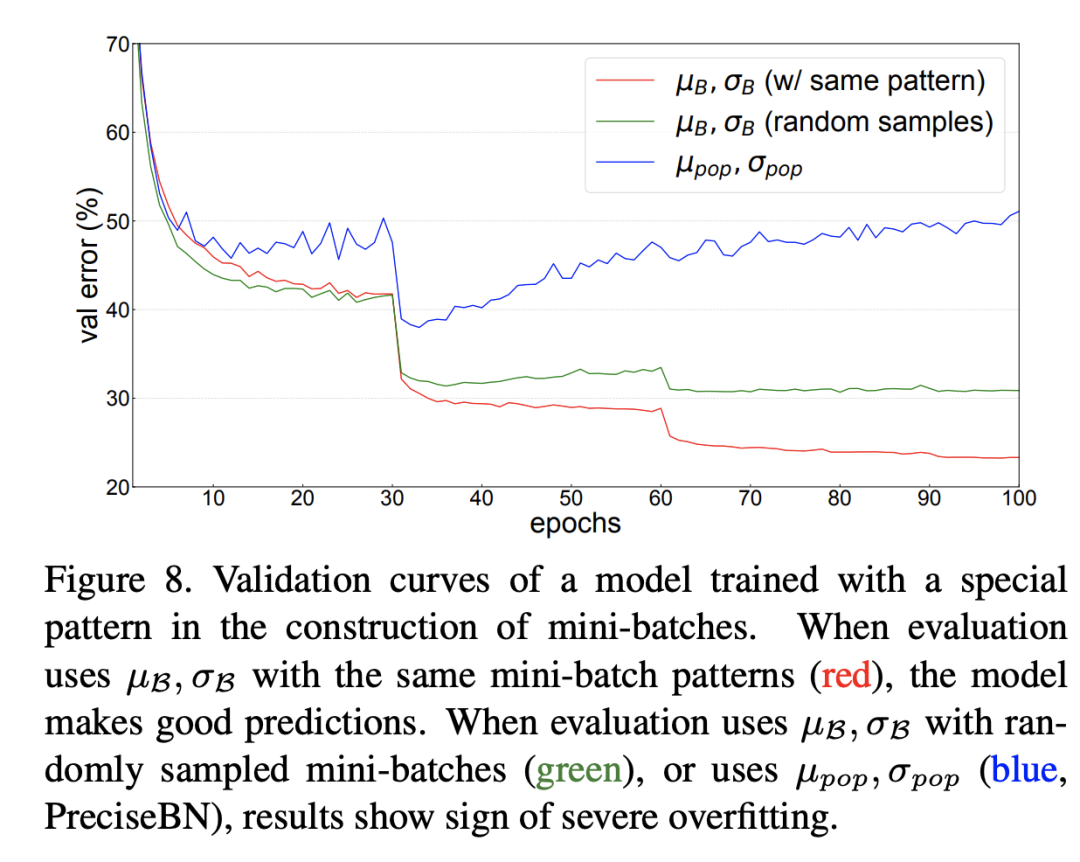
比如BatchNorm的作者曾做过这样一个实验,在ResNet50的训练过程中,NBS=32,但是保证里面包含16个类别,每个类别有2个图像,这样一种特殊的设计要模型在训练过程中强制记忆了这种模式(可能是每个mini-batch中必须有同类别存在),那么在测试时如果输入不是这种设计,效果就会变差。这个在验证集上不同处理结果如上所示,可以看到测试时无论是采用全局统计量还是random mini-batch统计量,效果均较差,但是如果采用和训练过程同样的模式,效果就比较好。这其实也从侧面说明保持一致是多么的重要。
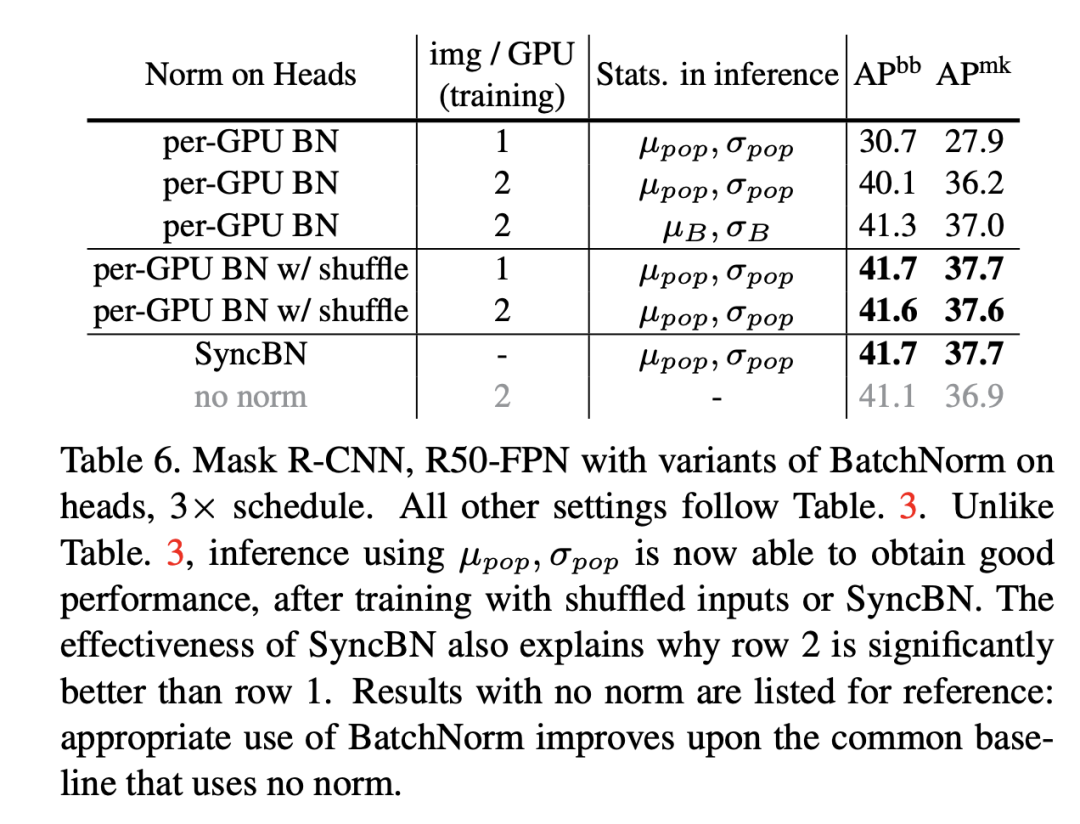
前面说过,如果在R-CNN的head加入BatchNorm,那么在测试时采用mini-batch统计量会比全局统计量会效果更好,这里面其实也存在信息泄露的问题。对于每个GPU只有一个image的情况,每个mini-batch里面的RoIs全部来自于一个图像,这时候模型就可能依赖mini-batch来做预测,那么测试时采用全局统计量效果就会差了,对于每个GPU有多个图像时,情况还稍好一些,所以原来的结果中单卡单图像效果最差。一种解决方案是采用shuffle BN,就是head进行处理前,先随机打乱所有卡上的RoIs特征,每个卡分配随机的RoIs,这样就避免前面那个可能出现的信息泄露,head处理完后再shuffle回来,具体处理流程如下所示:
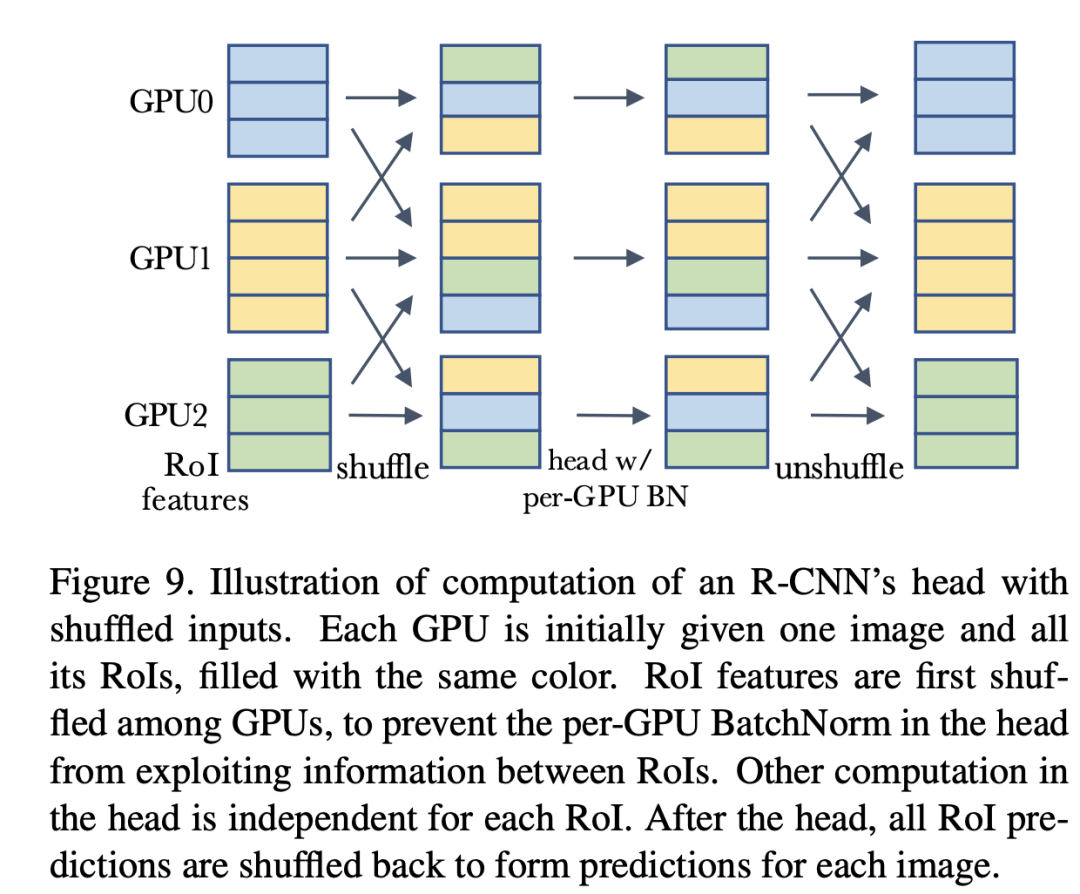
这个具体的代码实现见mask_rcnn_BNhead_shuffle.py。其实在MoCo中也使用了shuffle BN来防止信息泄露。另外还是可以采用SyncBN来避免这种问题。具体的对比结果如下所示,可以看到采用shuffle BN和SyncBN均可以避免信息泄露,得到较好的效果。注意shuffle BN的 cross-GPU synchronization要比SyncBN要少,效率更高一些。
另外一个常见的场景是对比学习中信息泄露,因为对比学习往往需要对同一个图像做不同的augmentations来作为正样本,这其实一个sample既当输入又当目标,mini-batch可能会泄露信息导致模型学习不到好的特征。MoCo采用的是shuffle BN,而SimCLR和BYOL采用的是SyncBN。另外旷视提出的Momentum^2 Teacher来采用moving average statistics来防止信息泄露。
总结
一个简单的BatchNorm,如果我们使用不当,往往会出现一些让人意料的结果,所以要谨慎处理。总结来看,主要有如下结论和指南:
模型在未收敛时使用EMA统计量来评估模型是不稳定的,一种替代方案是PreciseBN; BatchNorm本身存在训练和测试的不一致性,特别是NBS较少时,这种不一致会更强,可用的方案是测试时也采用mini-batch统计量或者采用FrozenBN; 在domain shift场景中,最好基于target domain数据重新计算全局统计量,在multi-domain数据训练时,要特别注意处理的一致性; BatchNorm会存在信息泄露的风险,这处理mini-batch时要防止特殊的出现。
参考
Rethinking "Batch" in BatchNorm
detectron2/projects/Rethinking-BatchNorm
推荐阅读
谷歌AI用30亿数据训练了一个20亿参数Vision Transformer模型,在ImageNet上达到新的SOTA!
"未来"的经典之作ViT:transformer is all you need!
PVT:可用于密集任务backbone的金字塔视觉transformer!
涨点神器FixRes:两次超越ImageNet数据集上的SOTA
不妨试试MoCo,来替换ImageNet上pretrain模型!
机器学习算法工程师
一个用心的公众号
