
【机器学习】PyCaret!又一个神仙的自动机器学习库!
作者:时晴
PyCaret这个开源工具,用起来可谓简单至极,少量代码就可以搭建各种端到端的模型,废话不多说,直接看实战。
PyCaret安装:
# install slim version (default)pip install pycaret# install the full versionpip install pycaret[full]
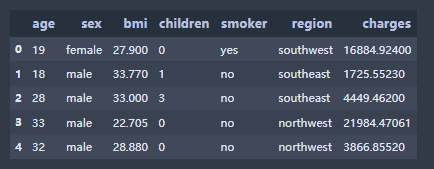
先用PyCaret自带的'insurance'数据集作为例子,我们看下数据:
# read data from pycaret repofrom pycaret.datasets import get_datadata = get_data('insurance')
数据预处理

该步骤是使用PyCaret构建任何模型强制要做的一步:
# initialize setupfrom pycaret.regression import *s = setup(data, target = 'charges')
执行完上述代码后,不仅自动推断了各个特征的类型,还问你是否推断正确。
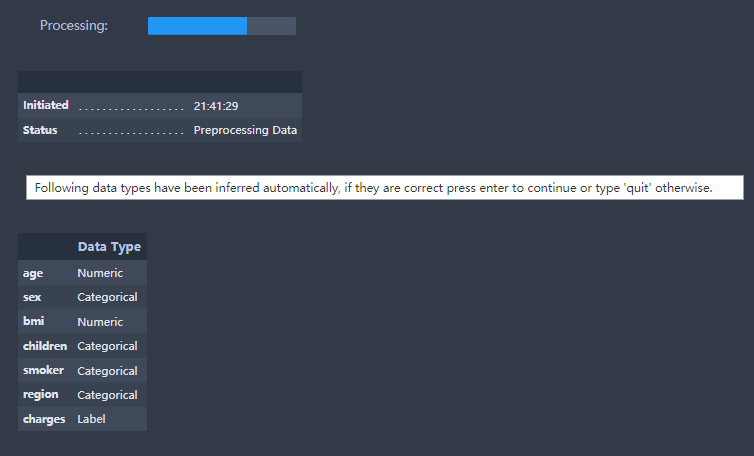
直接continue,会弹出setup的分析结果,如下图所示:
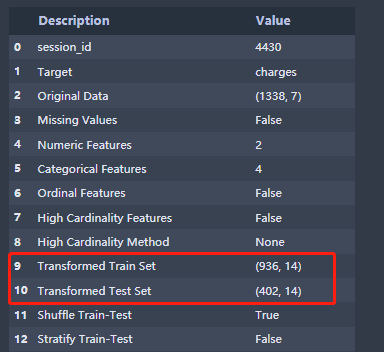
从上图红框中,我们惊喜的发现连训练集测试集都帮忙我们拆分好了,并行已经帮我们把训练数据shuffle好了。当然我们可以自定义拆分比例,如下所示:
setup(data = insurance, target = 'charges', train_size = 0.5)也可以对数据进行scale:
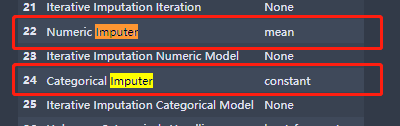
setup(data = pokemon, target = 'Legendary', normalize = True)会默认帮你把连续值,离散值的缺失值处理掉:
可以对数据进行分桶,只需要加上参数bin_numeric_features :
setup(data = income, target = 'income >50K', bin_numeric_features = ['age'])需要进行特征筛选的话,也只需要加一个参数feature_selection = True:
setup(data = diabetes, target = 'Class variable', feature_selection = True)同样,一个参数连异常值都帮你移除了remove_outliers = True:
setup(data = insurance, target = 'charges', remove_outliers = True)还有各种各样的预处理操作,大家可以参考官方文档。
https://pycaret.org/preprocessing/
模型训练
直接看下我们可以用哪些模型:
# check all the available modelsmodels()
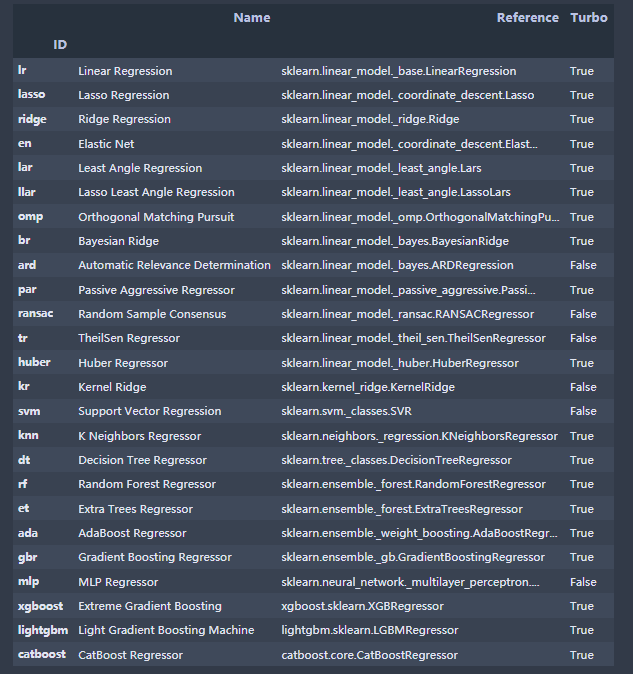
真的是应有尽有,大部分炼丹师其实只看到了最下面3个,xgb,lgb,cbt。
模型训练
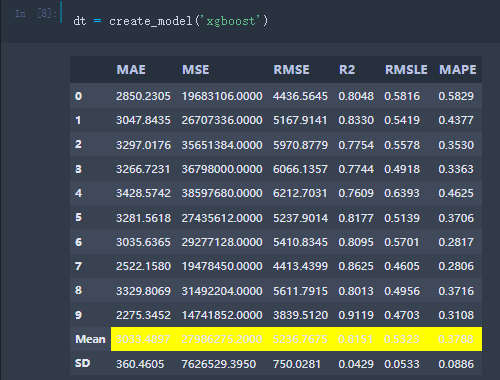
那么我们就用xgb跑下吧:
# train decision treedt = create_model('xgboost')
然后啥都不用写,测试集上各个mertic就显示出来了:
模型融合是大家最常用的,也只需要一行代码:
# train multiple modelsmultiple_models = [create_model(i) for i in ['dt', 'lr', 'xgboost']]
要比较各个模型,也只需要一行代码:
# compare all modelsbest_model = compare_models()
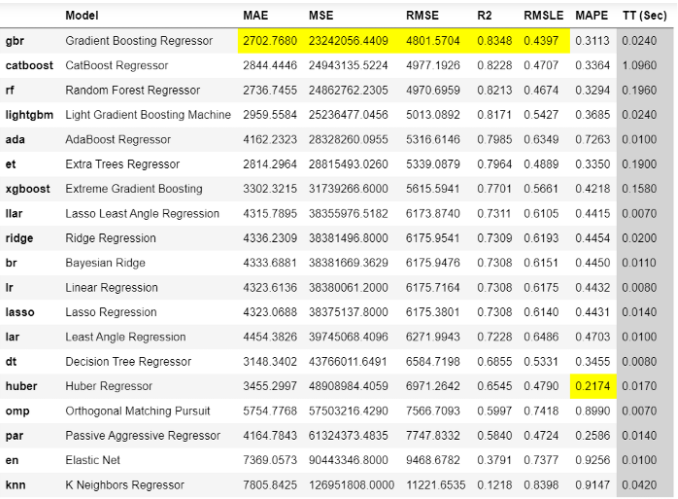
模型预估:
predictions = predict_model(best_model, data = data2)所以,大家数数看,我们一共才写了几行代码,就把模型预处理、训练、验证、融合、预估全完成了?做表格类数据模型真的是太方便了。
往期精彩回顾 本站qq群851320808,加入微信群请扫码:
评论