
一文图解卡尔曼滤波(Kalman Filter)

极市导读
本文使用一系列图示,清晰地介绍了卡尔曼滤波的背景和解决实际问题的过程。图文并茂,值得一看。>>加入极市CV技术交流群,走在计算机视觉的最前沿
1 背景
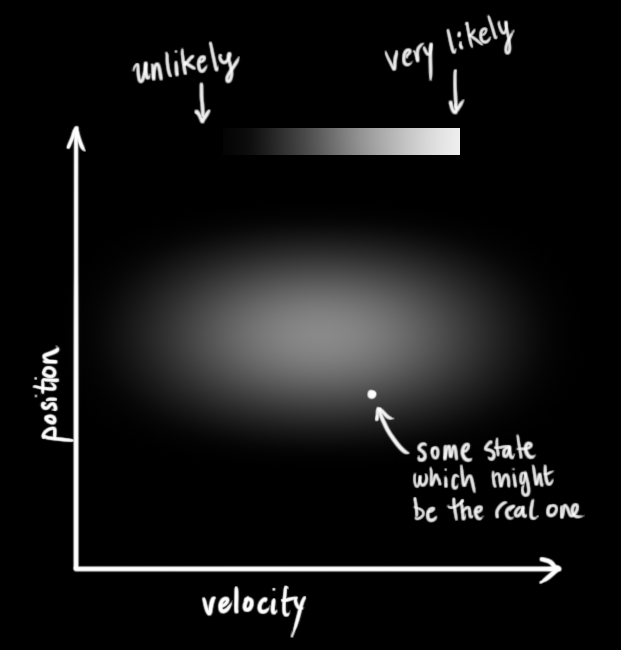
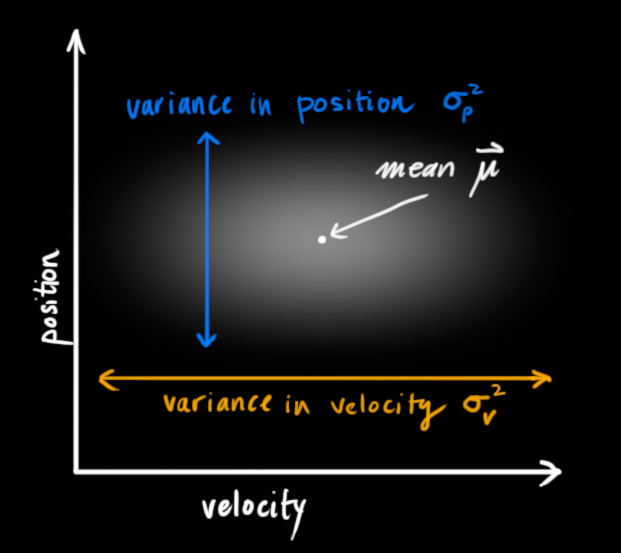
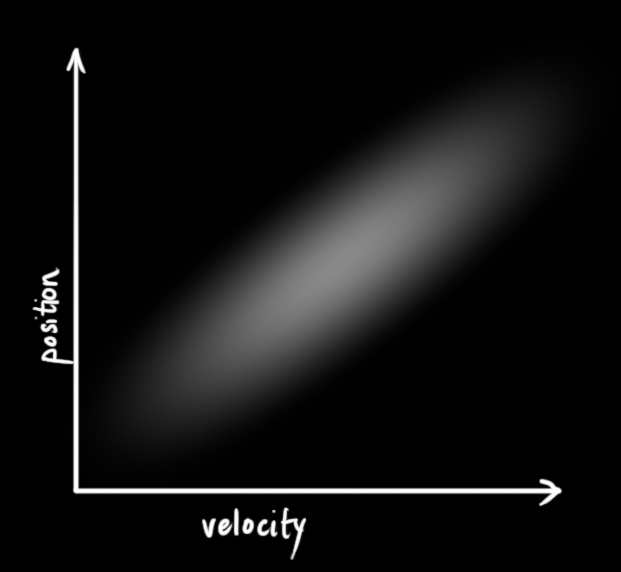
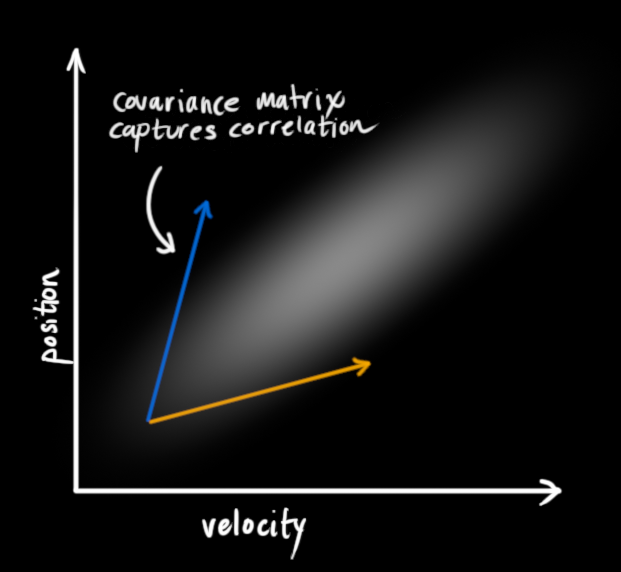
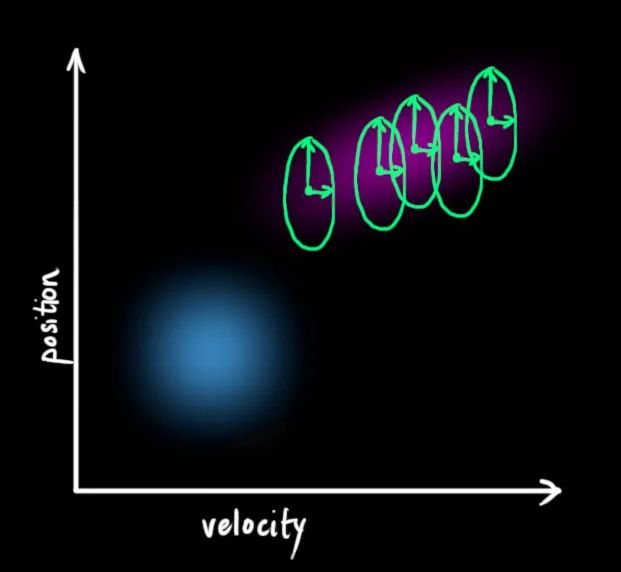
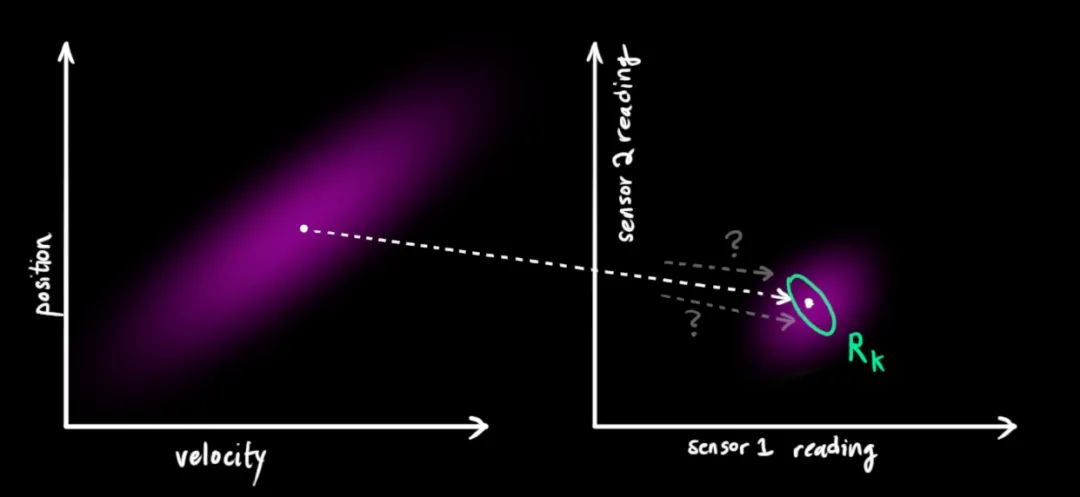
这种情况是很容易发生的,例如,如果速度很快,我们可能会走得更远,所以我们的位置会更大。如果我们走得很慢,我们就不会走得太远。
2 状态预测
问题的矩阵形式表示


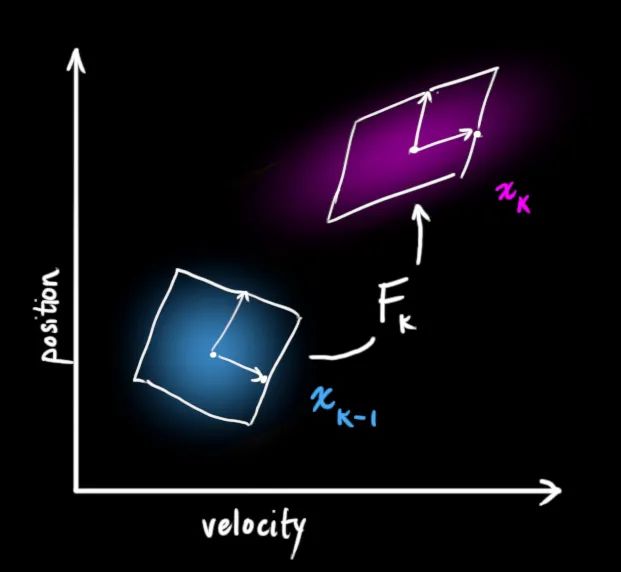
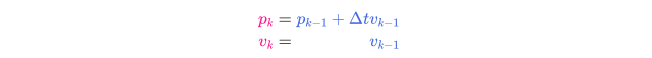
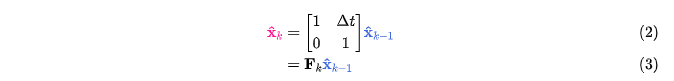
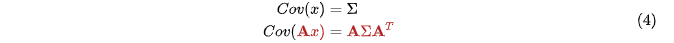
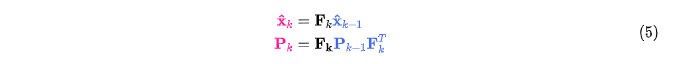
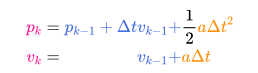
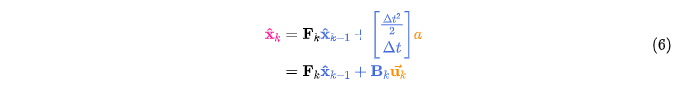

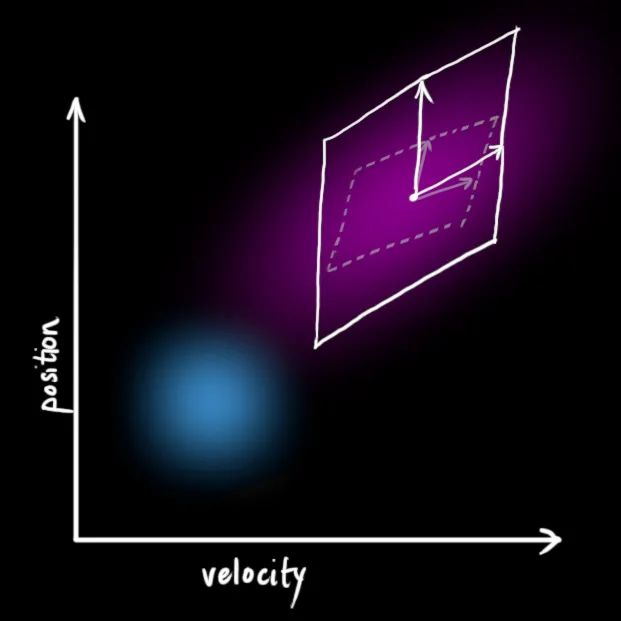
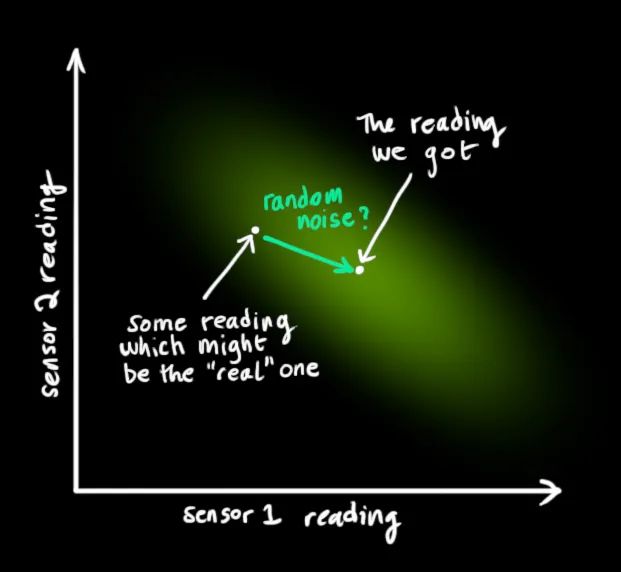
3 状态更新
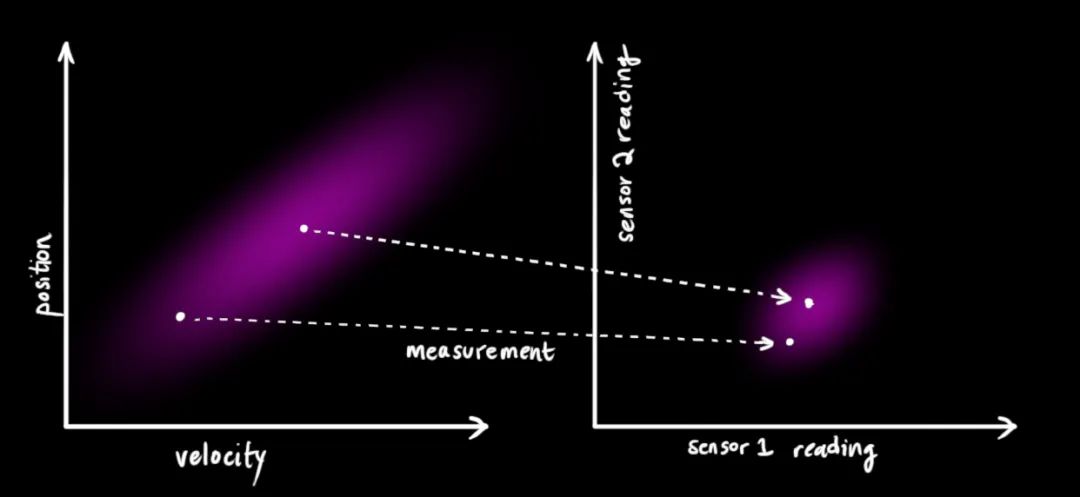
利用测量进一步修正状态
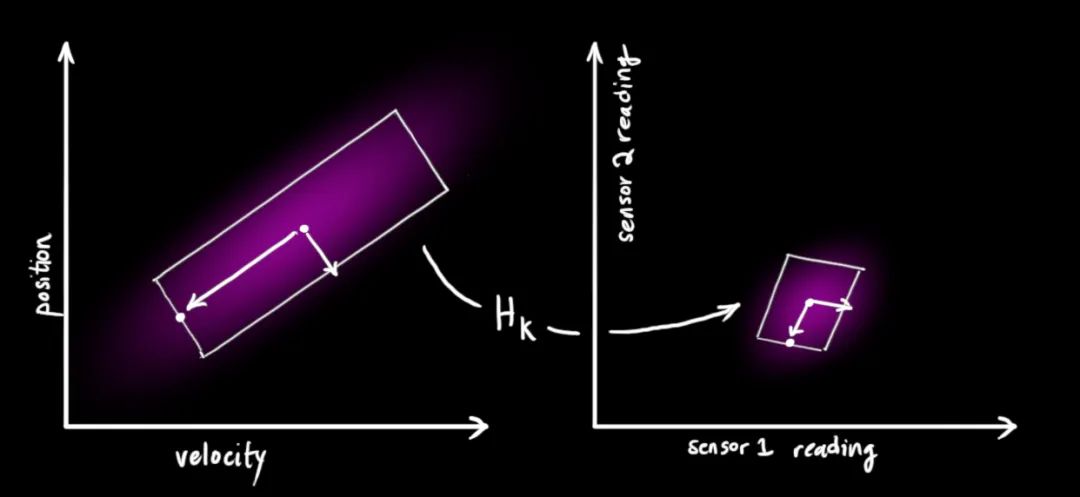
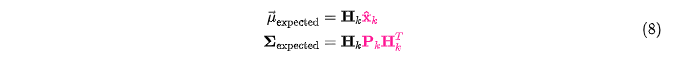
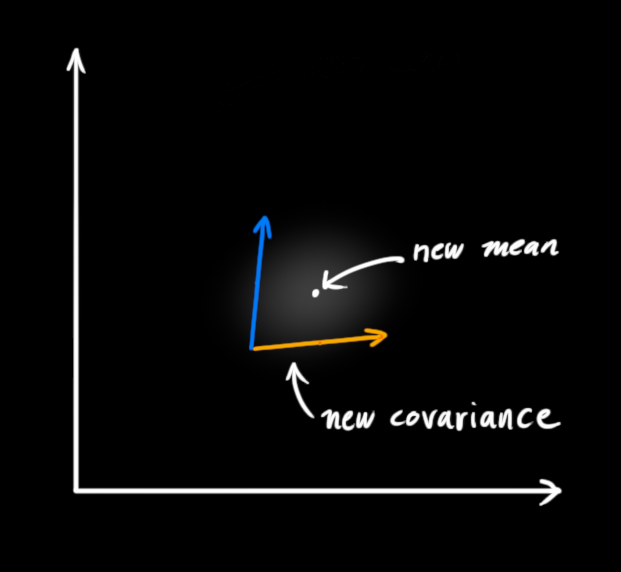
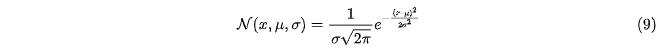

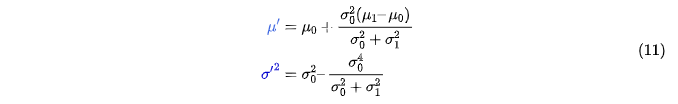

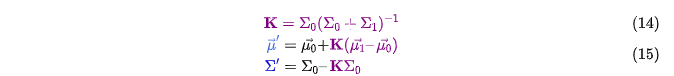
公式汇总
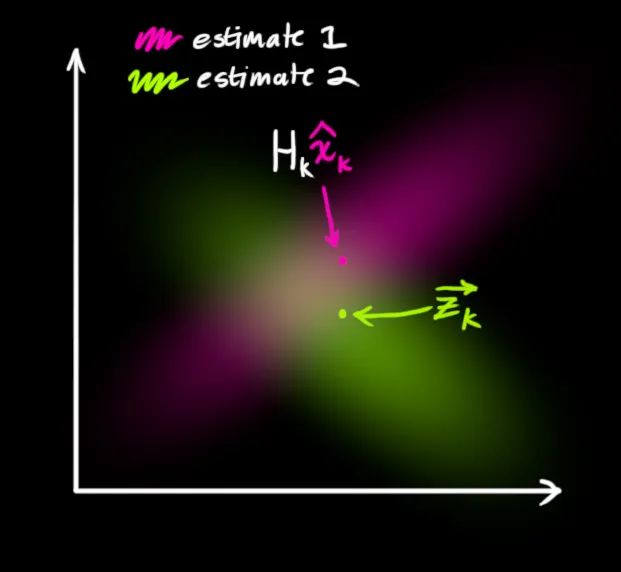
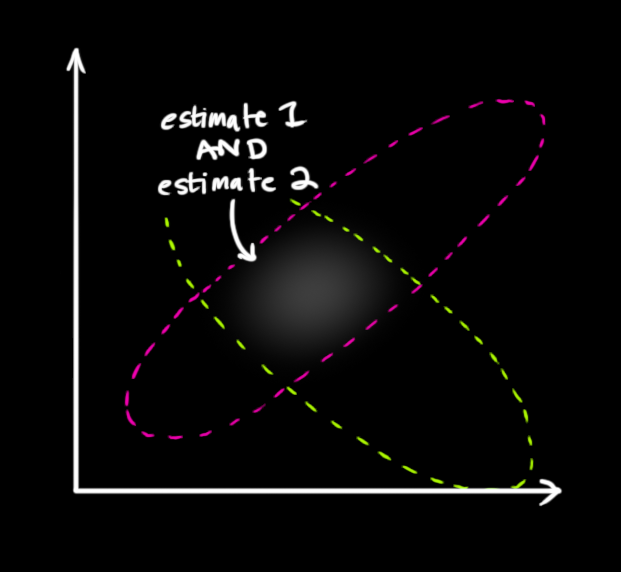
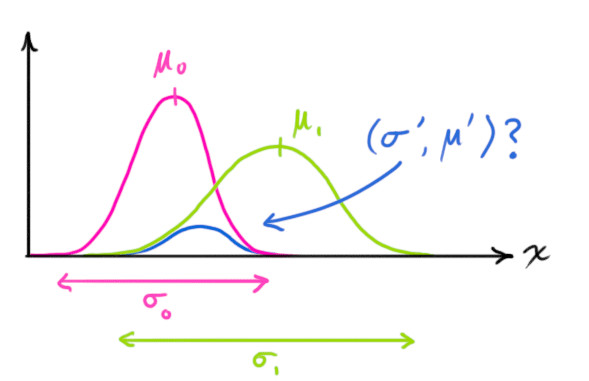
我们有两个高斯分布,一个是我们预测的观测,另外一个是实际的观测(传感器读数),我们将这两个高斯分布代入公式(15)中就可以得到二者的重叠区域:
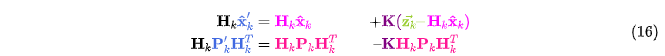

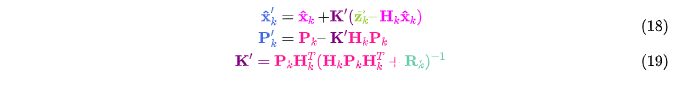
4 图说
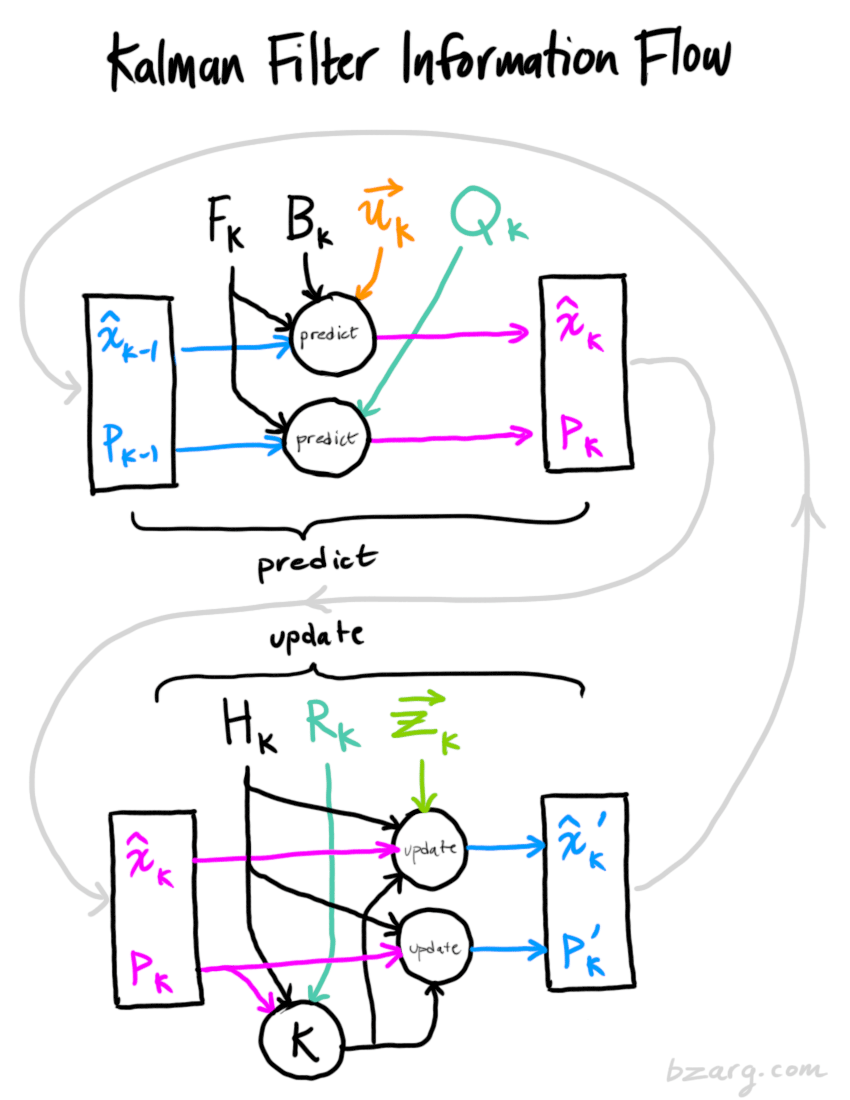
5 总结
参考资料
推荐阅读

评论