
干货|了解机器学习常用数据预处理
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达

在现实背景中,我们的数据集往往存在各种各样的问题,如果不对数据进行预处理,模型的训练就无法开始。
在对数据进行预处理阶段我们往往要解决一下问题
数据中存在缺失值
连续特征是否要离散化
离散特征的编码
特征量纲不同,不具可比性
由于各种各样原因,现实中的许多数据集包含缺失数据,这样的数据是无法直接用于训练的,因此我们需要对缺失值进行处理。
最简单粗暴的方法就是把含有缺失值的样本丢弃,这样可以避免人为填充带来的噪声。这样做可能会丢失一些很重要的信息,特别是数据量不多或者数据价值很高的数据来说,直接丢弃就太浪费了。因此我们可以旋转某种合适的策略对缺失值进行适当的填充。
一般来说,我们可以使用平均值、中值、分位数、众数等替代。如果想要更好的填充效果,可以考虑利用无缺失值的数据建立模型,通过模型来选择一个最适合的填充值,但如果缺失的属性对于模型可有可无,那么得出来的填充值也将不准确。我们还可以使用KNN来选择最相似的样本进行填充。除此以外,缺失信息也可以作为一种特殊的特征表达,例如人的性别,男、女、不详可能各自有着不同的含义。
特征可以被分为连续特征和离散特征,但有些时候我们可以会将连续特征离散化,例如,如果我们只关心年龄是否大于18,那么我们会将该特征二值化。这样不仅可以使得数据变得稀疏降低过拟合的情况,还可以加快学习的速度,并且令模型对异常数据不那么敏感。离散化方法分为有监督和无监督两类。
等宽、等频的离散化方法是无监督方法的典型代表,根据使用者给定的宽度或频数将连续的区间划分成小的区间的方法对分布不均匀的数据不适用,对异常点比较敏感。无监督离散化方法中还有基于聚类分析的离散化,它通过对某一特征的值进行聚类,由此得到离散区间的划分。
有监督离散化的方法有基于熵的离散化方法,它是一种自顶向下分裂的离散化方法,它根据信息熵在所有可能的区间断点中选取最优的划分。
特征虽然分为连续特征和离散特征,但是计算机都是将所有特征作为连续特征处理,因此如果我们想使用离散特征,必须对离散特征进行独热编码或哑编码。假设我们把年龄划分为[0,20),[20,40),[40,60),[60,+∞)四个区间并用0,1,2,3表示。使用独热编码特征会被编码为
| [0,20) | 1 | 0 | 0 | 0 |
|---|---|---|---|---|
| [20,40) | 0 | 1 | 0 | 0 |
| [40,60) | 0 | 0 | 1 | 0 |
| [60,+∞) | 0 | 0 | 0 | 1 |
如果是哑编码则会编码为
| [0,20) | 1 | 0 | 0 |
|---|---|---|---|
| [20,40) | 0 | 1 | 0 |
| [40,60) | 0 | 0 | 1 |
| [60,+∞) | 0 | 0 | 0 |
具体选择哪种编码可以参照知乎中王赟的回答
如果你不使用regularization,那么one-hot encoding的模型会有多余的自由度。这个自由度体现在你可以把某一个分类型变量各个值对应的权重都增加某一数值,同时把另一个分类型变量各个值对应的权重都减小某一数值,而模型不变。在dummy encoding中,这些多余的自由度都被统摄到intercept里去了。这么看来,dummy encoding更好一些。
如果你使用regularization,那么regularization就能够处理这些多余的自由度。此时,我觉得用one-hot encoding更好,因为每个分类型变量的各个值的地位就是对等的了。”
归一化和标准化都可以使特征无量纲化,归一化使得数据放缩在[0,1]之间并且使得特征之间的权值相同,改变了原数据的分布,而标准化将不同特征维度的伸缩变换使得不同度量之间的特征具有可比性。同时不改变原始数据的分布。常见的归一化方法有min-max标准化和z-score标准化。
min-max标准化根据特征的最大最小值将数据放缩到[0,1]之间
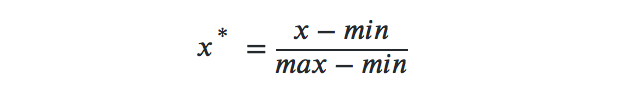
z-score标准化利用数据的均值和标准差将数据变为标准正态分布
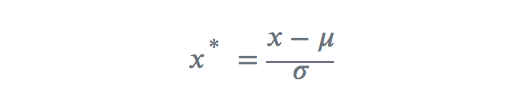
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~