
万字长文 | Sora技术解析报告

来源:NewBeeNLP 本文约10000字,建议阅读15分钟
本文介绍了Sora技术解析报告。

论文标题:Sora: A Review on Background, Technology, Limitations, and Opportunities of Large Vision Models
论文链接:https://arxiv.org/pdf/2402.17177.pdf
背景

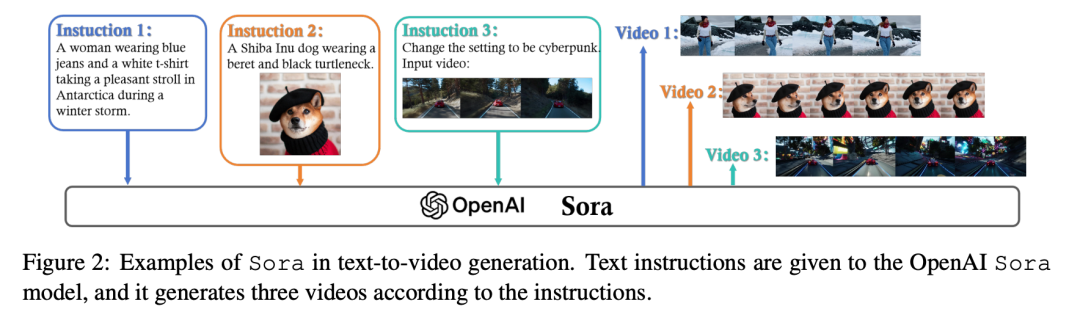
技术推演
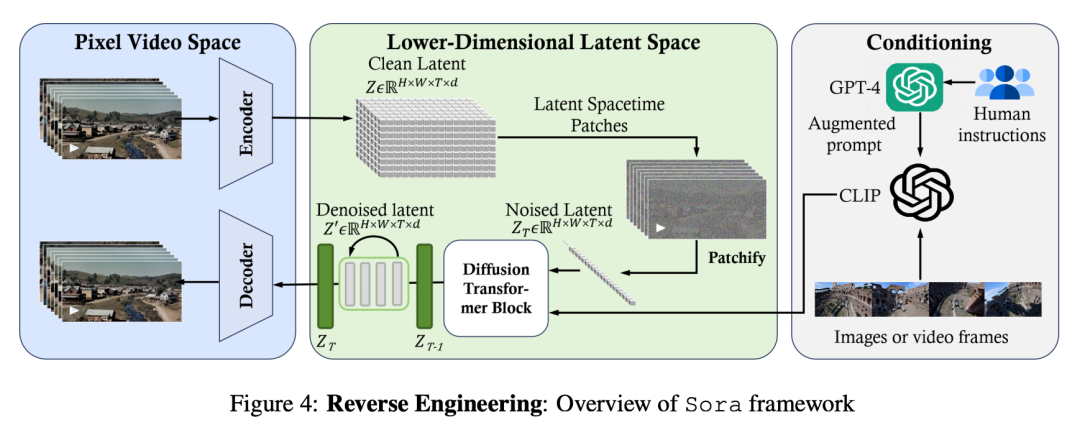




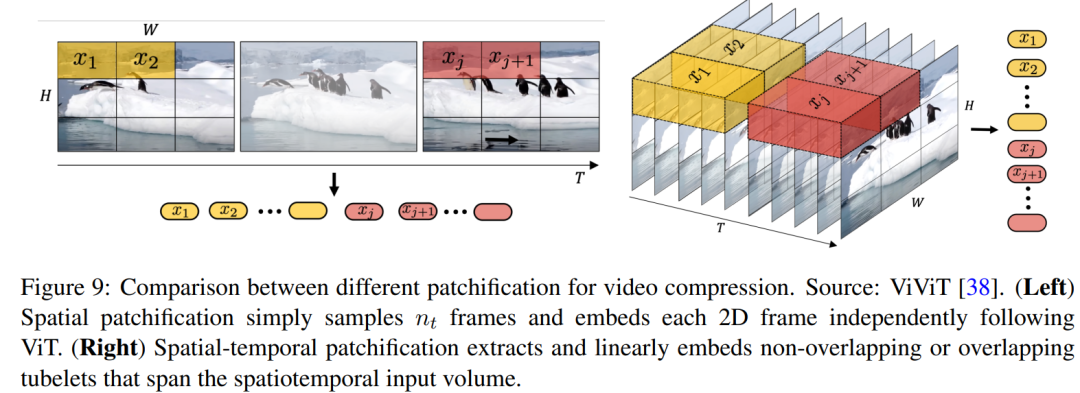
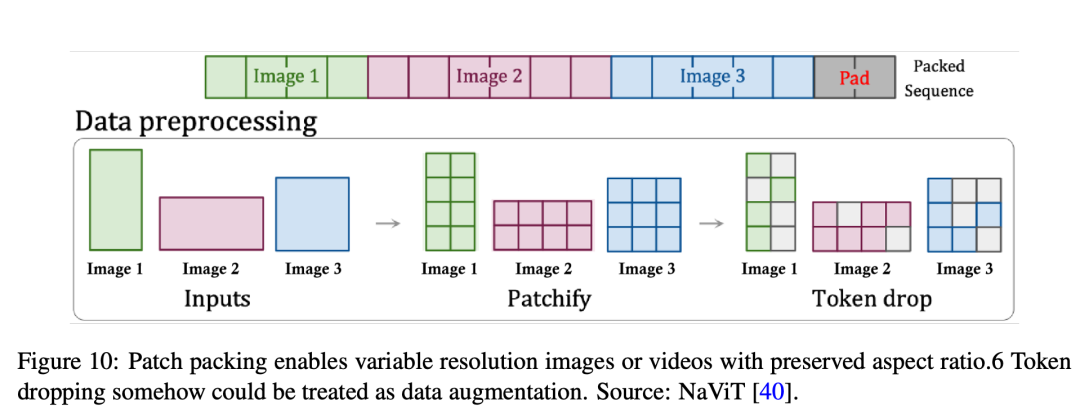
建模
-
图像 DiT

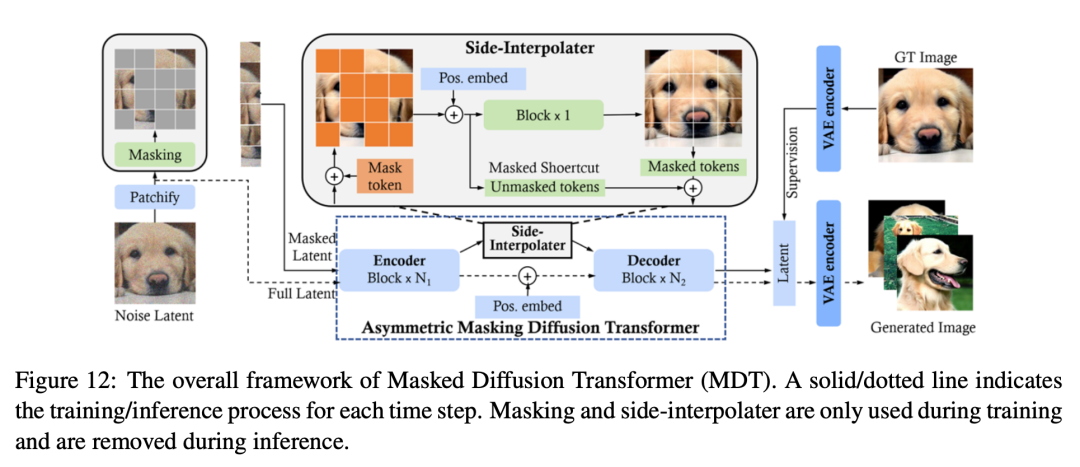
-
视频 DiT
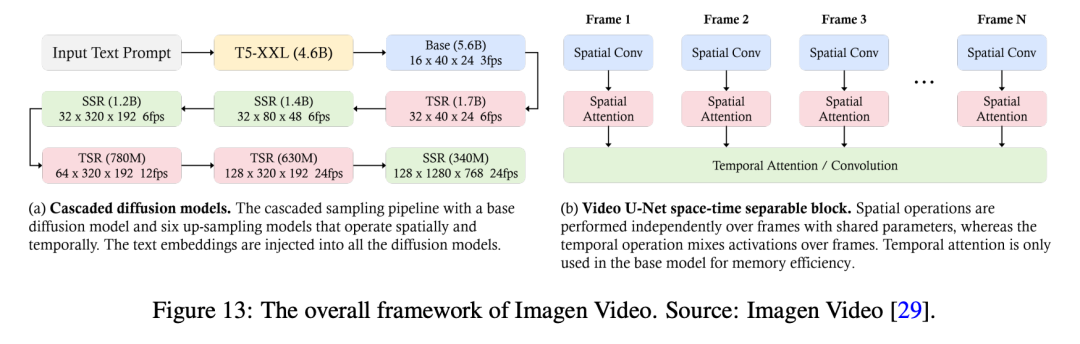
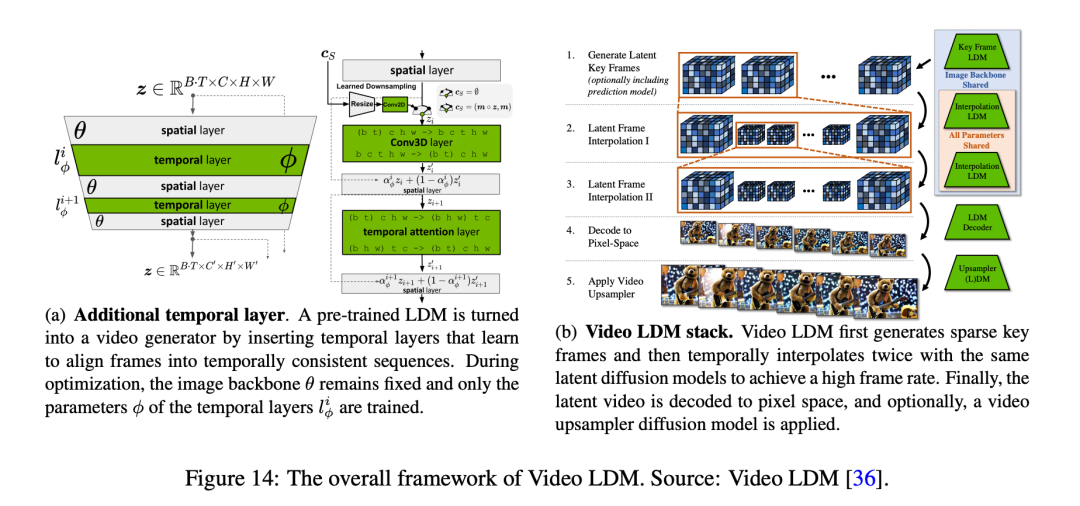
语言指令跟随
提示工程
-
文本提示

-
图像提示
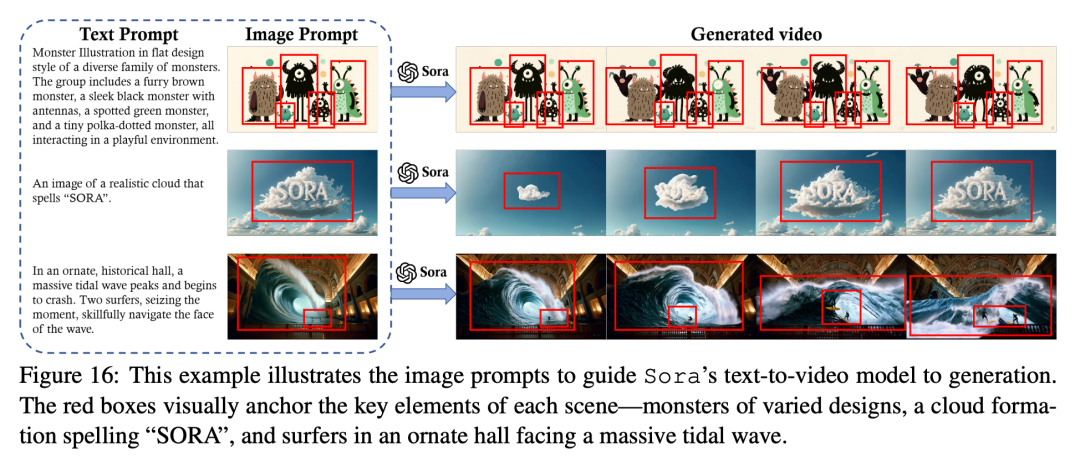
-
视频提示
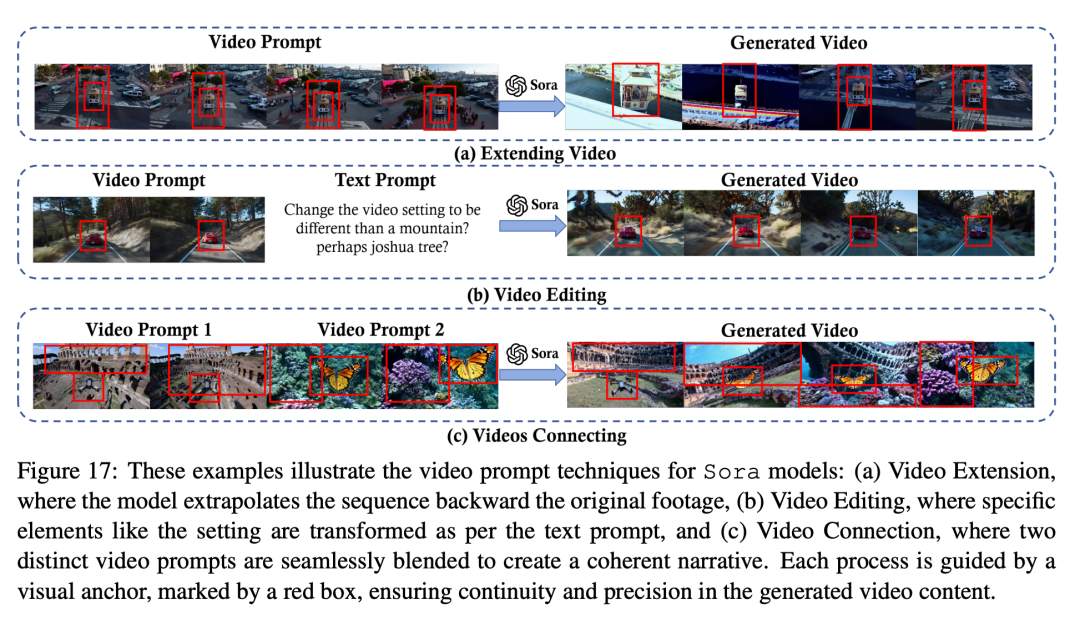
应用

-
提高模拟能力:对 Sora 进行大规模训练,是因为它能够出色地模拟物理世界的各个方面。尽管没有明确的三维建模,但 Sora 通过动态摄像机运动和远距离连贯性表现出三维一致性,包括物体持久性和模拟与世界的简单交互。此外,Sora 还能模拟类似 Minecraft 的数字环境,在保持视觉保真度的同时由基本策略控制,这一点非常有趣。这些新出现的能力表明,可扩展视频模型可以有效地创建人工智能模型,以模拟物理和数字世界的复杂性。 -
提高创造力:想象一下,通过文字勾勒出一个概念,无论是一个简单的物体还是一个完整的场景,都能在几秒钟内呈现出逼真或高度风格化的视频。Sora 可以加速设计过程,更快地探索和完善创意,从而大大提高艺术家、电影制作人和设计师的创造力。 -
推动教育创新:长期以来,视觉辅助工具一直是教育领域理解重要概念不可或缺的工具。有了 Sora,教育工作者可以轻松地将课堂计划从文字变成视频,吸引学生的注意力,提高学习效率。从科学模拟到历史剧,可能性是无限的。
-
增强可访问性:提高视觉领域的可访问性至关重要。Sora 通过将文字描述转换为可视内容,提供了一种创新的解决方案。这种功能使包括视觉障碍者在内的所有人都能积极参与内容创建,并以更有效的方式与他人互动。因此,它可以创造一个更具包容性的环境,让每个人都有机会通过视频表达自己的想法。 -
促进新兴应用:Sora 的应用领域非常广泛。例如,营销人员可以用它来制作针对特定受众描述的动态广告。游戏开发商可以利用它根据玩家的叙述生成定制的视觉效果甚至角色动作。
局限性
编辑:王菁
评论