
Pandas实例 - 怎样计算每个学生成绩最相似的10个学生
本文来自粉丝的一个需求,怎样计算每个学生成绩相近的10个学生?
需求

他的Excel表格是这个样子:
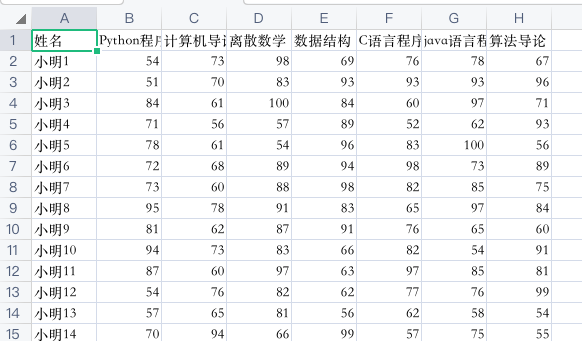
包含每个学生的姓名,以及多个科目的成绩。
怎么用Pandas实现呢?
解题思路
Pandas解题思路:
1、使用笛卡尔积的方式,得到 每个学生 和 另外所有学生的 关联行
每个学生都要与其他所有行进行交叉关联,比如有100个学生,那应该得到100*100 = 1W行结果
2、对于关联行,使用df.apply(function)的方法,计算两两相似度;
本步骤是为了计算每个学生和其他学生的 相似度
3、使用groupby + top n的方式,计算每个学生成绩最相近的10个学生
步骤0:读取数据
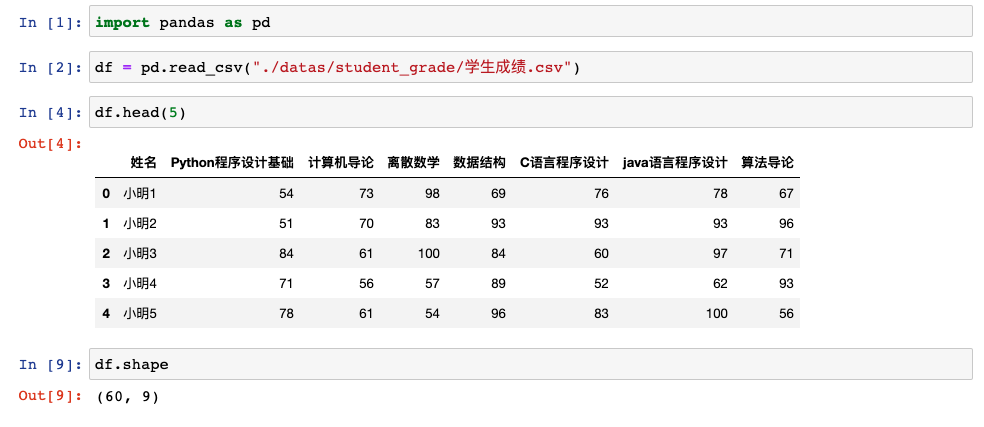
大家注意,这里的原始数据是60行;
步骤1:实现笛卡尔积
即实现每个学生与其他所有学生的关联。这里的技巧,是先添加一个一模一样的数字列,用此作为关联列进行merge即可
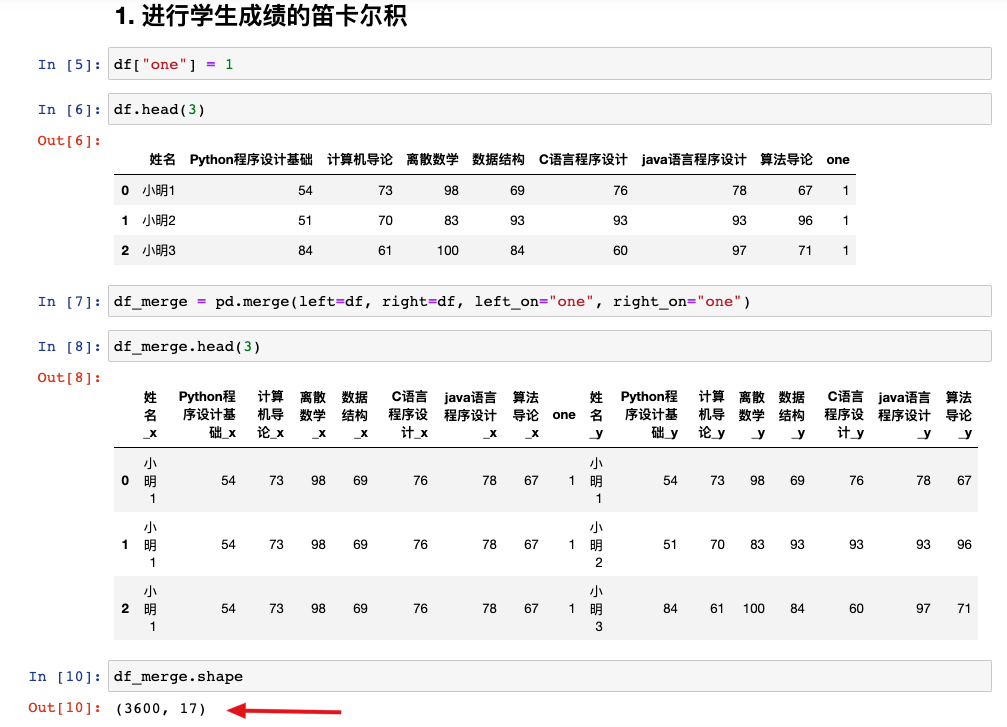
我们看到,这里的结果行数是3600,也就实现了60个学生的两两交叉。
步骤2:实现每个学生的相似度计算
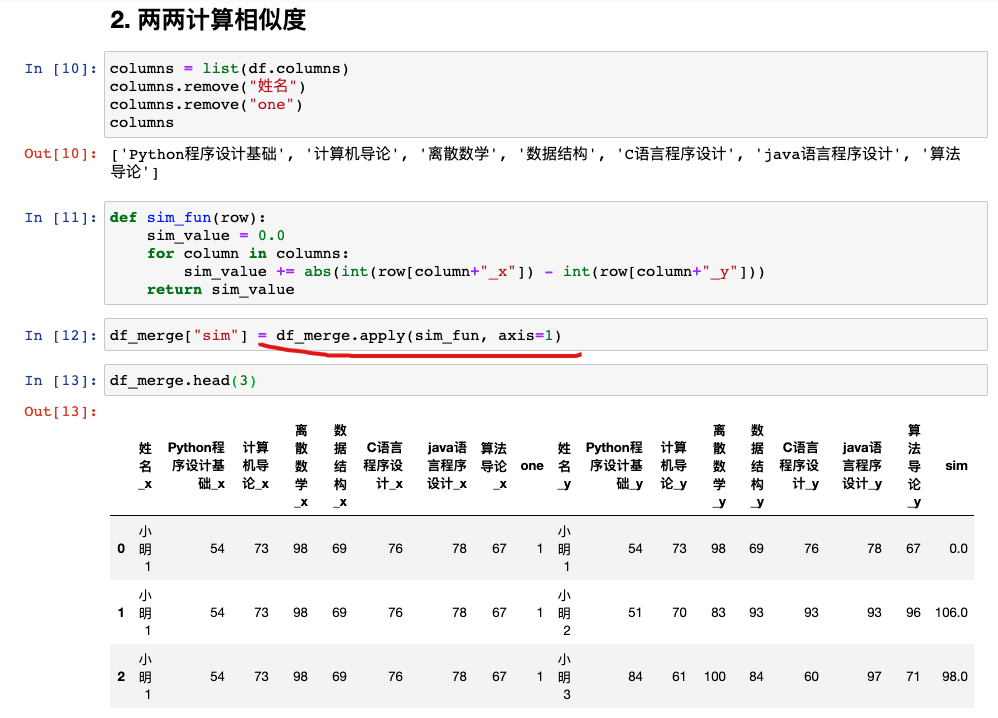
大家注意这里的用法,df.apply,可以按行回调一个函数进行处理

这里我多加了一步,把每个学生自己和自己关联的行去掉。
步骤3:计算每个学生最相近的10个学生
其实就是实现group by + top n的效果

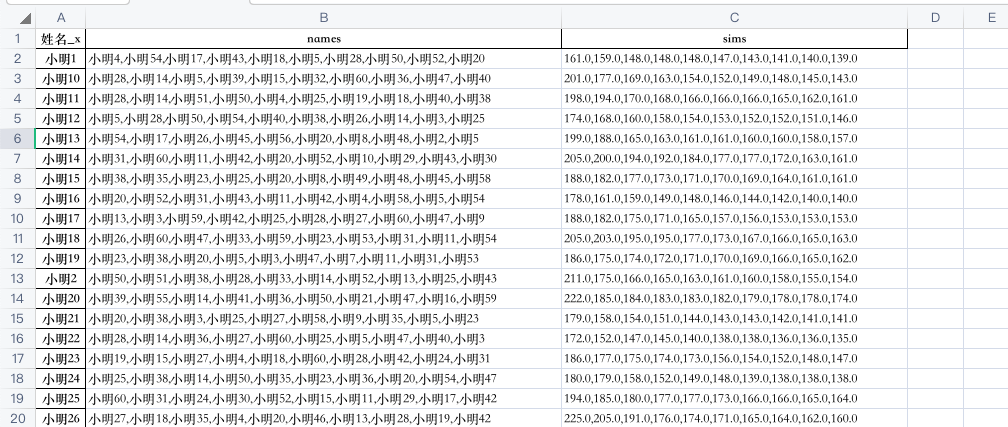
看下结果Excel文件
结果有3列,每个学生,以及他最相似的学生列表以及相似度值
视频讲解
代码地址:
https://github.com/peiss/ant-learn-pandas
打开github后,第46集
如果本文对你有帮助,感谢点赞和再看^_^
评论