
深入探索云原生流水线的架构设计
共 5531字,需浏览 12分钟
·
2022-05-11 01:40
本文约 4400 字,预计阅读时间:12 分钟
支持各种任务运行时,包括 K8s Job、K8s Flink、K8s Spark、DC/OS Job、Docker、InMemory 等?
支持快速对接其他任务运行时?
支持任务逻辑抽象,并且快速地开发自己的 Action?
支持嵌套流水线,在流水线层面进行逻辑复用?
支持灵活的上下文参数传递,有好用的 UI 以及简单明确的工作流定义?
······
那么,不妨试试 Erda Pipeline 吧~
CI/CD 快数据平台 自动化测试平台 SRE 运维链路 ……
自研能更快地响应业务需求,进行定制化开发; 时至今日,开源社区还没有一个实质上的流水线标准,各种产品百花齐放; K8s、DC/OS 等的 Job 实现都偏弱、上下文传递缺失,无法满足我们的需求,更不用说灵活好用的 Flow 了,例如:嵌套流水线。
整体架构
内部架构
水平扩展
分布式架构
功能特性
实现细节

Pipeline 支持灵活的使用方式,目前支持 UI 可视化操作、OPENAPI 开放接口、CLI 命令行工具几种方式。
协议层面,在 Erda-Infra 微服务框架的加持下,以 HTTP 和 gRPC 形式对外提供服务:在早期的时候,我们只提供了 HTTP 服务,由于 Erda 平台本身内部是微服务架构,服务间调用就需要手动编写 HTTP 客户端,不好自动生成,麻烦且容易出错。后来我们改为使用 Protobuf 作为 IDL(Interface Define Language),在 Erda-Infra 中自动生成 gRPC 的客户端调用代码和服务端框架代码,内部服务间的调用都改为使用 gRPC 调用。
在中间件依赖层面,我们使用 ETCD 做分布式协调,用 MySQL 做数据持久化。ETCD 我们也有计划把它替换掉,使用 MySQL 来做分布式协调。
最关键的任务运行时(Task Runtime)层面,我们支持任务可以运行在 K8s、DC/OS(分布式云 OS,在 2017-2019 年非常火)、用户本地 Docker 环境等。
我们还有开放的任务扩展市场,在平台级别内置了非常多的流水线任务扩展,开箱即用。同时,用户也可以开发企业/项目/应用/个人级别的任务扩展,这部分功能在代码层面已经完全支持,产品层面正在开发中,在后续迭代中很快就可以和大家见面。

使用 Erda-Infra 微服务框架开发,功能模块划分清晰:
Server 层包括业务逻辑,对 Pipeline 来说业务就是创建、执行、重试、重试失败节点等。
Modules 层提供不含业务逻辑的公共模块,其余两层均可调用,包括预校验机制、定时守护进程、YAML 解析器、配置管理、事件管理等。
Engine 层负责流水线的推进,包括:
Queue Manager 队列管理器,支持队列内工作流的优先级动态调整、资源检查、依赖检查等。
Dispatcher 任务分发器,用于将满足出队条件的流水线分发给合适的 Worker 进行推进。
Reconciler 协调器,负责将一条完整的流水线解析为 DAG 结构后进行推进,直至终态。
模块内部使用插件机制,对接各种任务运行时。
AOP 扩展点机制(借鉴 Spring),把代码关键节点进行暴露,方便开发同学在不修改核心代码的前提下定制流水线行为。
目前已经有的一些扩展点插件,譬如自动化测试报告嵌套生成、队列弹出前检查、接口测试自动登录保持等。
这个能力后续我们还会开放给调用方,包括用户,去做一些有意思的事情。
统一使用 Event,封装了 WebHook / WebSocket / Metrics。
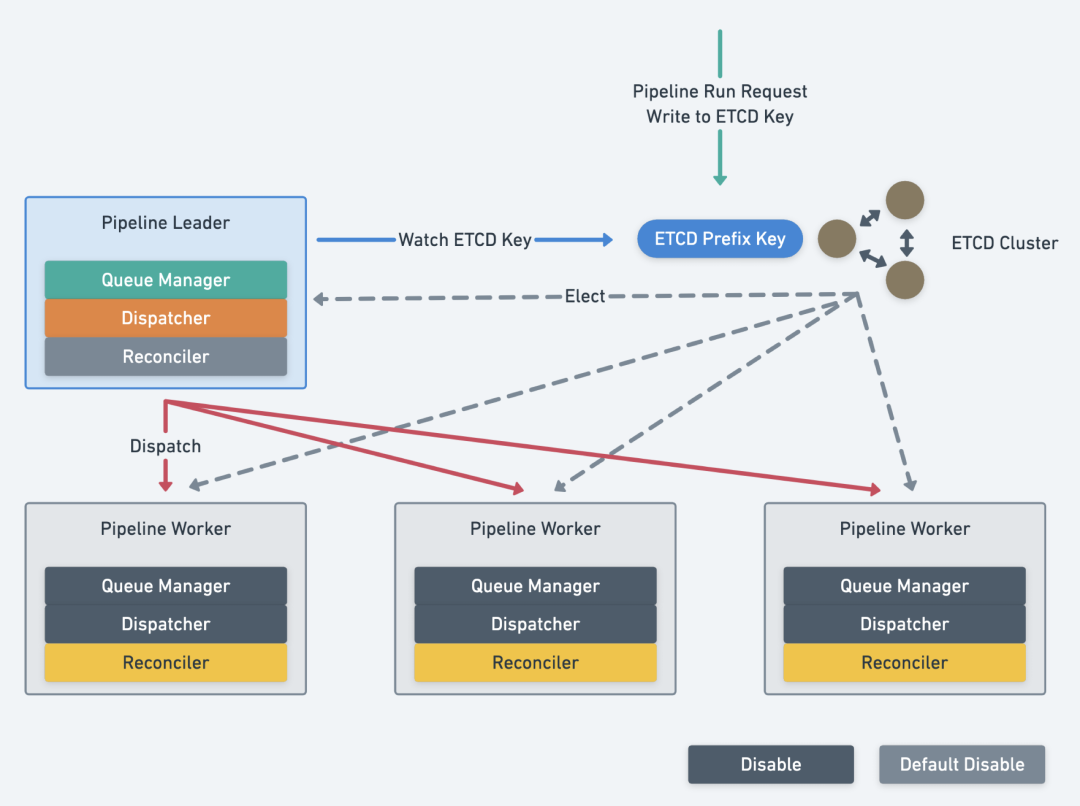
Leader & Worker 模式,两者在部署上不区分状态,仅为 Replicas 多实例:
使用 ETCD 选举,每个实例都可以是 Leader。
只有 Leader 开启 Queue Manager 和 Dispatcher,分发任务给 Worker。
Leader 本身也可以作为 Worker,支持单节点部署模式,Leader 必须开启 Reconciler。
Dispatch 使用有界负载的一致性哈希算法:
使用一致性哈希来分配任务。但一致性哈希会超载,例如某些热点内容会持续打到一个节点上。
有界负载算法(The bounded-load algorithm):
只要服务器未过载,请求的分配策略与一致性哈希相同。
过载服务器的溢出负载将在可用服务器之间分配。
Pipeline 实例增减时,已经被分配的流水线不重新分配,尽可能减少切换成本,防止重复推进;新增的流水线使用一致性 Hash 算法进行分配。
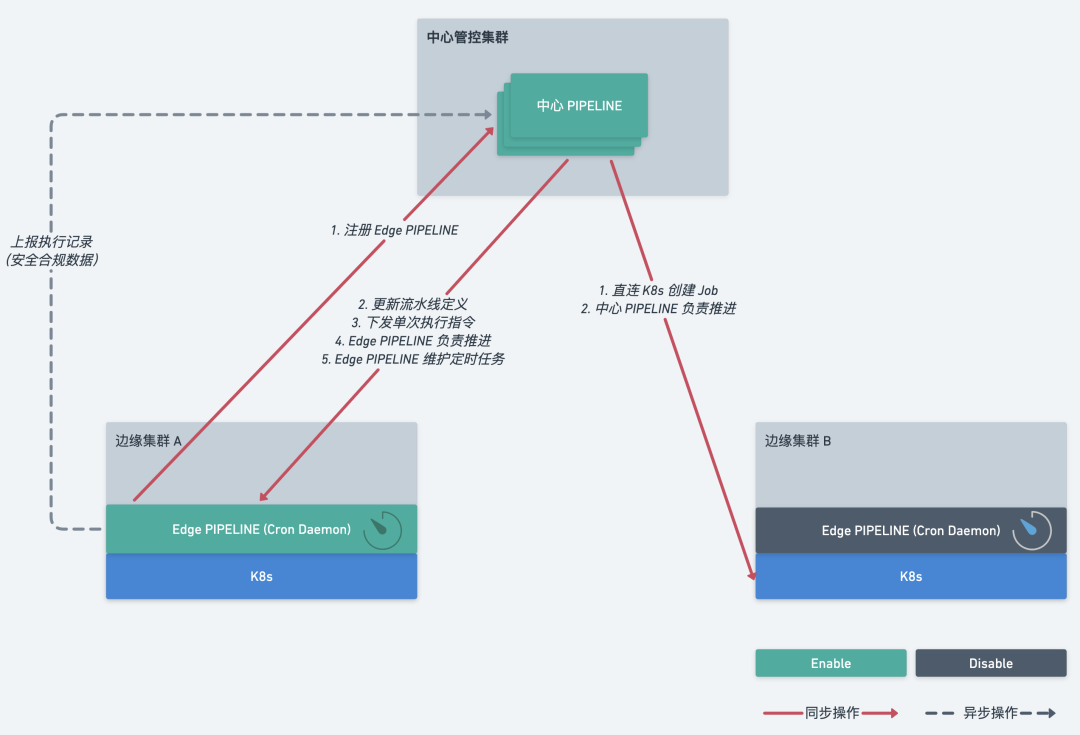
该分布式架构是典型的 AP 模型,数据层面遵循最终一致性。
中心 Pipeline 直接负责流程推进,调用边缘 K8s 创建 Job。
当网络分区时,原有部署架构下,定时任务无法正常执行。
中心下发任务定义,由 Edge Pipeline 负责推进,直连 K8s,更加稳定。
在网络分区恢复时,主动上报执行数据,实现数据最终一致性。
这里简单列举一些比较常见的功能特性:
配置即代码 扩展市场丰富 可视化编辑 支持嵌套流水线 灵活的执行策略,支持 OnPush / OnMerge 等触发策略 支持工作流优先队列 多维度的重试机制 定时流水线及定时补偿功能 动态配置,支持“值”和“文件”两种类型,均支持加密存储,确保数据安全性 上下文传递,后置任务可以引用前置任务的“值”和“文件” 开放的 OpenAPI 接口,方便第三方系统快速接入
 如何实现上下文传递(值引用)
如何实现上下文传递(值引用)
每个节点的特殊输出(按格式写入指定文件或者打印到标准输出)会被保存在 Pipeline 数据库中; 后续节点通过 outputs 语法声明的表达式会在节点开始执行前被替换为真正的值。

如图所示:第一个节点 repo 拉取代码;第二个节点 build erda 则是构建 Erda 项目。
 如何实现上下文传递(文件引用)
如何实现上下文传递(文件引用)文件引用比值引用复杂,因为文件的数据量比值大得多,不能存储在数据库中,而是存储在卷中。 这里又根据是否使用共享存储而分为两种情况,两者的区别在于申请的卷的类型和个数。 对于流水线使用者而言,没有任何区别。

使用共享存储
 如何实现缓存加速
如何实现缓存加速
在许多流水线场景中,同一条流水线的多次执行之间是有关联的。如果能够用到上一次的执行结果,则可以大幅缩短执行时间。
典型场景是 CI/CD 构建,我们以 Java 应用 Maven 构建举例:不但同一条流水线不同的多次执行可以复用 ${HOME}/.m2 目录(缓存目录),甚至同一个应用下的多个分支之间都可以使用同一个缓存目录,就像本地构建一样~

仍然使用前面的例子,在第二步 build erda 里加上 cache 即可。

Action Agent
对敏感日志进行脱敏处理,保证数据安全
无感知的错误分析和数据上报
文件变动监听及实时上报
……
上述所有机制都是由 Action Agent 程序完成的,它是一个静态编译的 Go 程序,可以运行在任意 Action 镜像中。Agent 完整的执行链路如下:
 Action Executor 扩展机制
Action Executor 扩展机制恰当的任务执行器抽象,使得 Batch/Streaming/InMemory Job 的配置方式和使用方式完全一致,流批一体,对使用者屏蔽底层细节,做到无感知切换。
在同一条流水线中,可以混用各种 ActionExecutor。
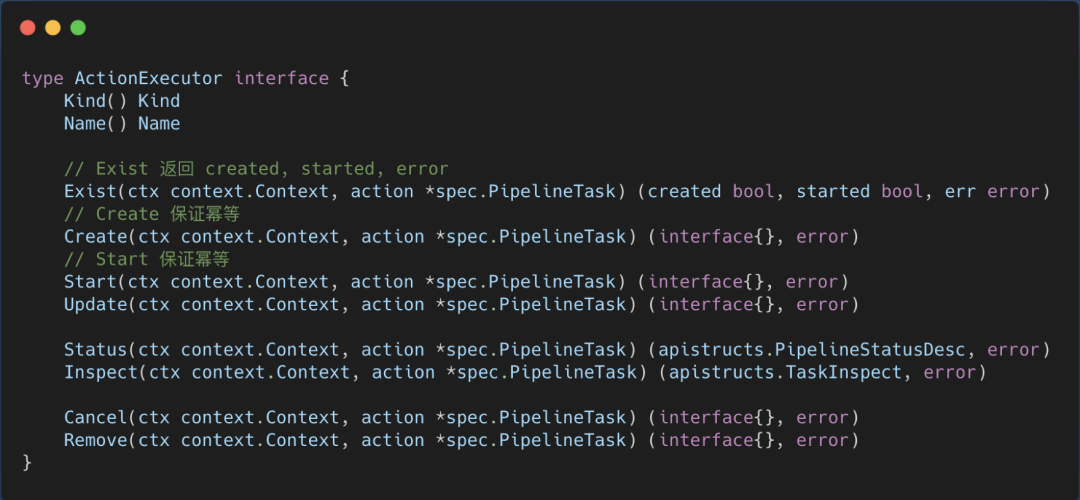
Go 接口定义

AOP 扩展点机制
