
基于 Kafka 的实时数仓在搜索的实践应用
作者:vivo互联网服务器团队-Deng jie
一、概述
Apache Kafka 发展至今,已经是一个很成熟的消息队列组件了,也是大数据生态圈中不可或缺的一员。Apache Kafka 社区非常的活跃,通过社区成员不断的贡献代码和迭代项目,使得 Apache Kafka 功能越发丰富、性能越发稳定,成为企业大数据技术架构解决方案中重要的一环。
Apache Kafka 作为一个热门消息队列中间件,具备高效可靠的消息处理能力,且拥有非常广泛的应用领域。那么,今天就来聊一聊基于 Kafka 的实时数仓在搜索的实践应用。
二、为什么需要 Kafka
在设计大数据技术架构之前,通常会做一些技术调研。我们会去思考一下为什么需要 Kafka?怎么判断选择的 Kafka 技术能否满足当前的技术要求?
2.1 早期的数据架构
早期的数据类型比较简单,业务架构也比较简单,就是将需要的数据存储下来。比如将游戏类的数据存储到数据库(MySQL、Oracle)。但是,随着业务的增量,存储的数据类型也随之增加了,然后我们需要使用的大数据集群,利用数据仓库来将这些数据进行分类存储,如下图所示:
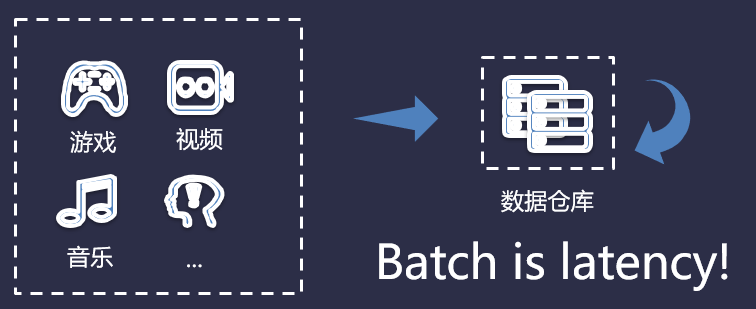
但是,数据仓库存储数据是有时延的,通常时延为T+1。而现在的数据服务对象对时延要求均有很高的要求,例如物联网、微服务、移动端APP等等,皆需要实时处理这些数据。
2.2 Kafka 的出现
Kafka 的出现,给日益增长的复杂业务,提供了新的存储方案。将各种复杂的业务数据统一存储到 Kafka 里面,然后在通过 Kafka 做数据分流。如下图所示:
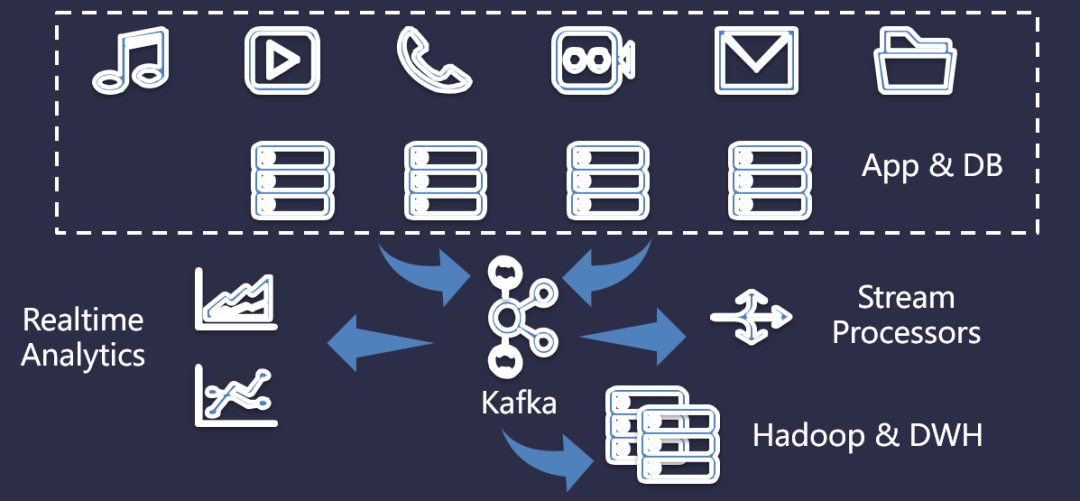
这里,可以将视频、游戏、音乐等不同类型的数据统一存储到 Kafka 里面,然后在通过流处理对 Kafka 里面的数据做分流操作。例如,将数据存储到数据仓库、将计算的结果存储到KV做实时分析等。
通常消息系统常见的有两种,它们分别是:
消息队列:队列消费者充当了工作组的角色,每条消息记录只能传递给一个工作进程,从而有效的划分工作流程;
生产&消费:消费者通常是互相独立的,每个消费者都可以获得每条消息的副本。
这两种方式都是有效和实用的,通过消息队列将工作内容分开,用于容错和扩展;生产和消费能够允许多租户,来使得系统解耦。而 Apache Kafka 的优点之一在于它将消息队列、生产和消费结合到了一个强大的消息系统当中。
同时,Kafka 拥有正确的消息处理特性,主要体现在以下几个方面:
可扩展性:当 Kafka 的性能(如存储、吞吐等)达到瓶颈时,可以通过水平扩展来提升性能;
真实存储:Kafka 的数据是实时落地在磁盘上的,不会因为集群重启或故障而丢失数据;
实时处理:能够集成主流的计算引擎(如Flink、Spark等),对数据进行实时处理;
顺序写入:磁盘顺序 I/O 读写,跳过磁头“寻址”时间,提高读写速度;
内存映射:操作系统分页存储利用内存提升 I/O 性能,实现文件到内存的映射,通过同步或者异步来控制 Flush;
零拷贝:将磁盘文件的数据复制到“页面缓存”一次,然后将数据从“页面缓存”直接发送到网络;
高效存储:Topic 和 Partition 拆为多个文件片段(Segment),定期清理无效文件。采用稀疏存储,间隔若干字节建立一条索引,防止索引文件过大。
2.3 简单的应用场景
这里,我们可以通过一个简单直观的应用场景,来了解 Kafka 的用途。
场景:假如用户A正在玩一款游戏,某一天用户A喜欢上了游戏里面的一款道具,打算购买,于是在当天 14:00 时充值了 10 元,在逛游戏商店时又喜欢上了另一款道具,于是在 14:30 时又充值了 30 元,接着在 15:00 时开始下单购买,花费了 20 元,剩余金额为 20 元。那么,整个事件流,对应到库表里面的数据明细应该是如下图所示:

三、Kafka解决了什么问题
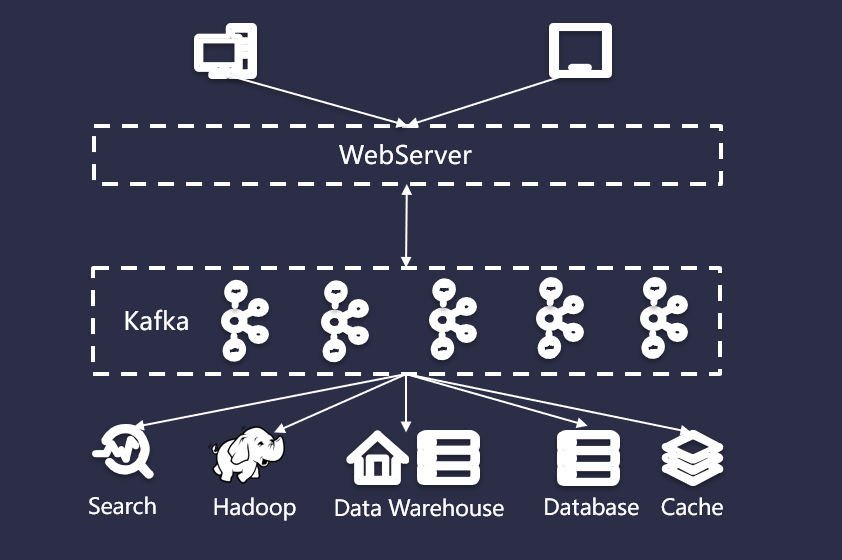
早期为响应项目快速上线,在服务器或者云服务器上部署一个 WebServer,为个人电脑或者移动用户提供访问体验,然后后台在对接一个数据库,为 Web 应用提供数据持久化以及数据查询,流程如下图所示:
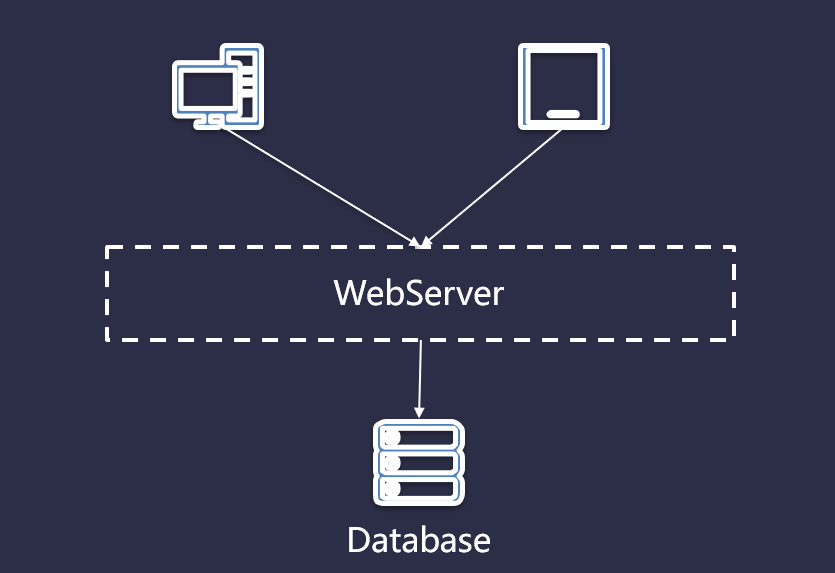
但是,随着用户的迅速增长,用户所有的访问都直接通过 SQL 数据库使得它不堪重负,数据库的压力也越来越大,不得不加上缓存服务以降低 SQL 数据库的荷载。
同时,为了理解用户行为,又开始收集日志并保存到 Hadoop 这样的大数据集群上做离线处理,并且把日志放在全文检索系统(比如 ElasticSearch)中以便快速定位问题。由于需要给投资方看业务状况,也需要把数据汇总到数据仓库(比如 Hive)中以便提供交互式报表。此时的系统架构已经具有一定的复杂性了,将来可能还会加入实时模块以及外部数据交互。
本质上,这是一个数据集成问题。没有任何一个系统能够解决所有的事情,所以业务数据根据不同用途,存放在不同的系统,比如归档、分析、搜索、缓存等。数据冗余本身没有任何问题,但是不同系统之间太过复杂的数据同步却是一种挑战。如下图所示:
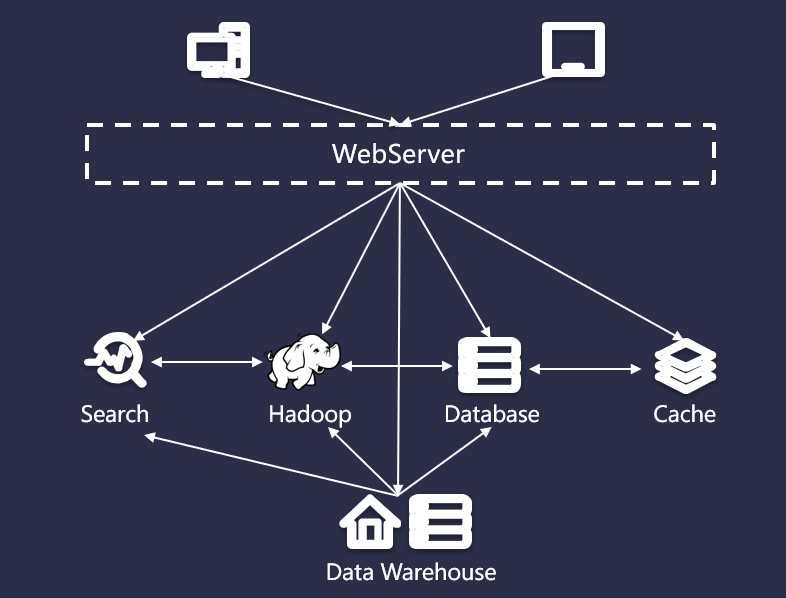
而 Kafka 可以让合适的数据以合适的形式出现在合适的地方。Kafka 的做法是提供消息队列,让生产者向队列的末尾添加数据,让多个消费者从队列里面依次读取数据然后自行处理。如果说之前连接的复杂度是 O(N^2),那么现在复杂度降低到了 O(N),扩展起来也方便多了,流程如下图所示:
四、Kafka的实践应用
4.1 为什么需要建设实时数仓
4.1.1 目的
通常情况下,在大数据场景中,存储海量数据建设数据仓库一般都是离线数仓(时延T+1),通过定时任务每天拉取增量数据,然后创建各个业务不同维度的数据,对外提供 T+1 的数据服务。计算和数据的实时性均比较差,业务人员无法根据自己的即时性需求获取几分钟之前的实时数据。数据本身的价值随着时间的流逝会逐步减弱,因此数据产生后必须尽快的到达用户的手中,实时数仓的建设需求由此而来。
4.1.2 目标
为了适应业务高速迭代的特点,分析用户行为,挖掘用户价值,提高用户留存,在实时数据可用性、可扩展性、易用性、以及准确性等方面提供更好的支持,因此需要建设实时数仓。主要目标包含如下所示:
统一收敛数据出口:统一数据口径,减少数据重复性建设;
降低数据维护成本:提升数据准确性、及时性,优化数据使用体验和成本;
减少数据使用成本:提高数据复用率,避免实时数据重复消费。
4.2 如何构建实时数仓为搜索提供数据
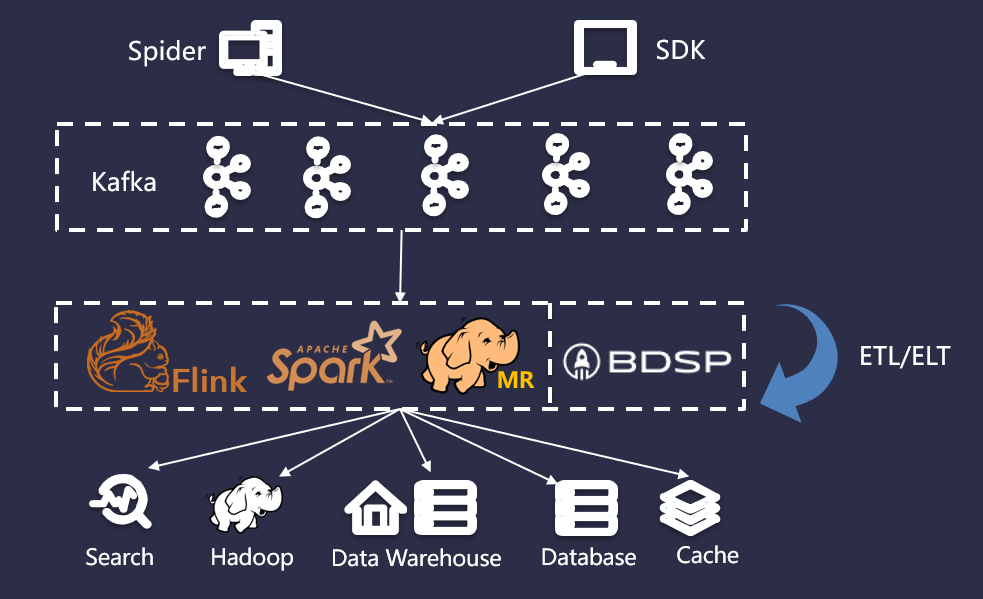
当前实时数仓比较主流的架构一般来说包含三个大的模块,它们分别是消息队列、计算引擎、以及存储。结合上述对 Kafka 的综合分析,结合搜索的业务场景,引入 Kafka 作为消息队列,复用大数据平台(BDSP)的能力作为计算引擎和存储,具体架构如下图所示:
4.3 流处理引擎选择
目前业界比较通用的流处理引擎主要有两种,它们分别是Flink和Spark,那么如何选择流处理引擎呢?我们可以对比以下特征来决定选择哪一种流处理引擎?
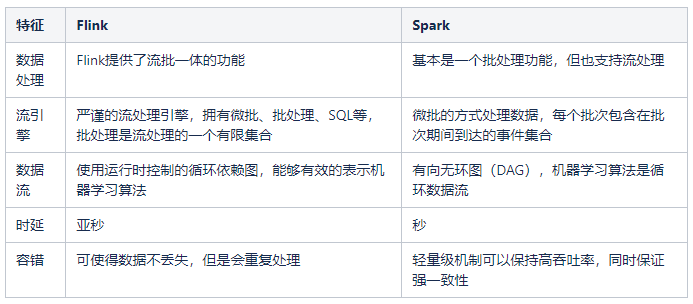
Flink作为一款开源的大数据流式计算引擎,它同时支持流批一体,引入Flink作为实时数仓建设的流引擎的主要原因如下:
高吞吐、低延时;
灵活的流窗口;
轻量级容错机制;
流批一体
4.4 建设实时数仓遇到的问题
在建设初期,用于实时处理的 Kafka 集群规模较小,单个 Topic 的数据容量非常大,不同的实时任务都会消费同一个大数据量的 Topic,这样会导致 Kafka 集群的 I/O 压力非常的大。
因此,在使用的过程中会发现 Kafka 的压力非常大,经常出现延时、I/O能性能告警。因此,我们采取了将大数据量的单 Topic 进行实时分发来解决这种问题,基于 Flink 设计了如下图所示的数据分发流程。
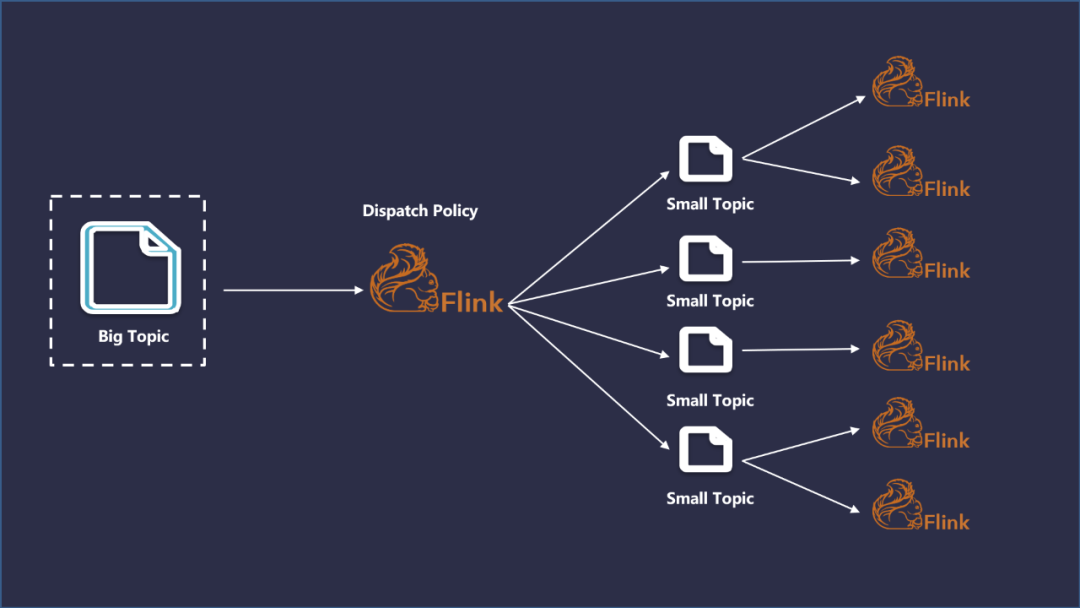
上述流程,随着业务类型和数据量的增加,又会面临新的问题:
数据量增加,随着消费任务的增加,Kafka 集群 I/O 负载大时会影响消费;
不用业务之间 Topic 的消费没有落地存储(比如HDFS、HBase存储等),会产生重复消费的情况;
数据耦合度过高,迁移数据和任务难度大。
4.5 实时数仓方案进阶
目前,主流的实时数仓架构通常有2种,它们分别是Lambda、Kappa。
4.5.1 Lambda
随着实时性需求的提出,为了快速计算一些实时指标(比如,实时点击、曝光等),会在离线数仓大数据架构的基础上增加一个实时计算的链路,并对消息队列实现数据来源的流失处理,通过消费消息队列中的数据 ,用流计算引擎来实现指标的增量计算,并推送到下游的数据服务中去,由下游数据服务层完成离线和实时结果的汇总。具体流程如下:
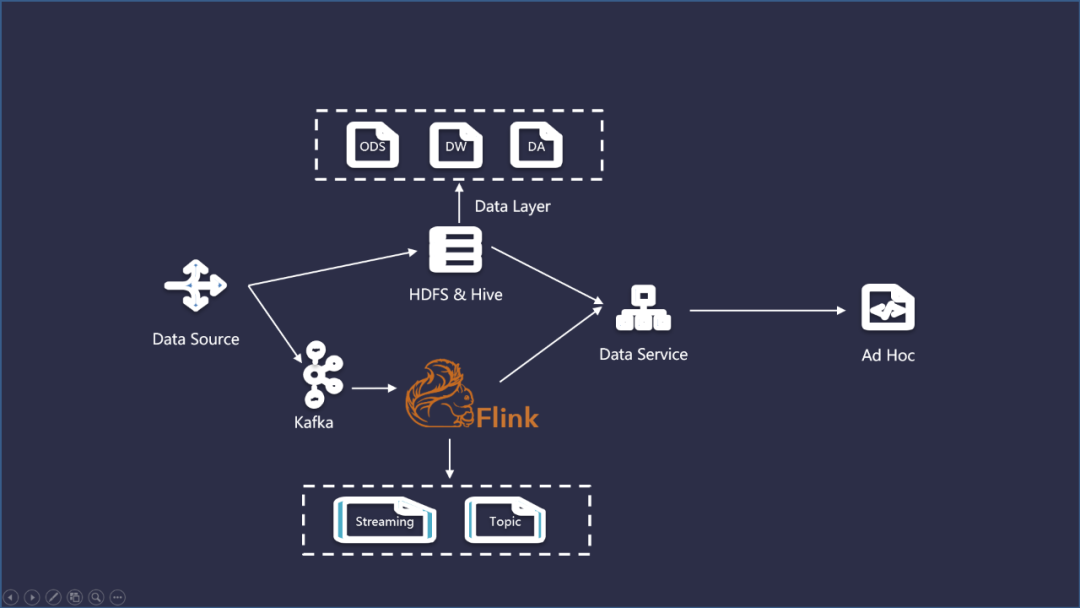
4.5.2 Kappa
Kappa架构只关心流式计算,数据以流的方式写入到 Kafka ,然后通过 Flink 这类实时计算引擎将计算结果存放到数据服务层以供查询。可以看作是在Lambda架构的基础上简化了离线数仓的部分。具体流程如下:
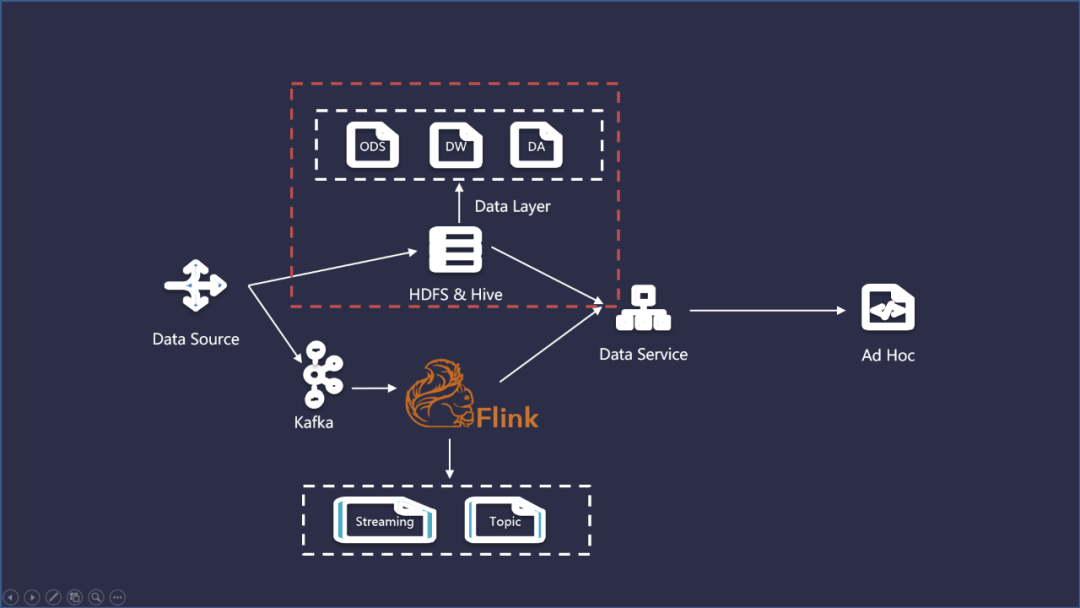
在实际建设实时数仓的过程中,我们结合这2种架构的思想来使用。实时数仓引入了类似于离线数仓的分层理念,主要是为了提供模型的复用率,同时也要考虑易用性、一致性、以及计算的成本。
4.5.3 实时数仓分层
在进阶建设实时数仓时,分层架构的设计并不会像离线数仓那边复杂,这是为了避免数据计算链路过长造成不必要的延时情况。具体流程图如下所示:
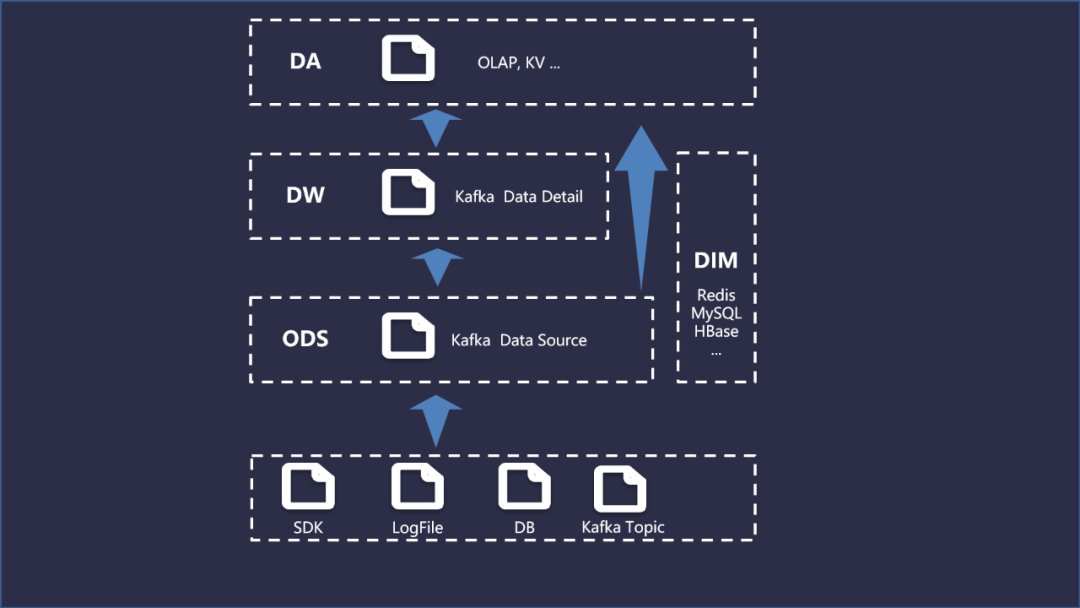
ODS层:以Kafka 作为消息队列,将所有需要实时计算处理的数据放到对应的 Topic 进行处理;
DW层:通过Flink实时消费Topic中的数据,然后通过数据清理、多维度关联(JOIN)等,将一些相同维度的业务系统、维表中的特征属性进行关联,提供数据易用性和复用性能力,最终得到实时明细数据;
DIM层:用来存储关联的查询的维度信息,存储介质可以按需选择,比如HBase、Redis、MySQL等;
DA层:针对实时数据场景需求,进行高度聚合汇总,服务于KV、BI等场景。OLAP分析可以使用ClickHouse,KV可以选择HBase(若数据量较小,可以采用Redis)。
通过上面的流程,建设实时数仓分层时,确保了对实时计算要求比较高的任务不会影响到BI报表、或者KV查询。但是,会有新的问题需要解决:
Kafka 实时数据如何点查?
消费任务异常时如何分析?
4.5.4 Kafka监控
针对这些问题,我们调研和引入了Kafka 监控系统——Kafka Eagle(目前改名为EFAK)。复用该监控系统中比较重要的维度监控功能。
Kafka Eagle处理能够满足上诉两个维度的监控需求之外,还提供了一些日常比较实用的功能,比如Topic记录查看、Topic容量查看、消费和生产任务的速率、消费积压等。我们采用了 Kafka-Eagle 来作为对实时数仓的任务监控。Kafka-Eagle 系统设计架构如下图所示:
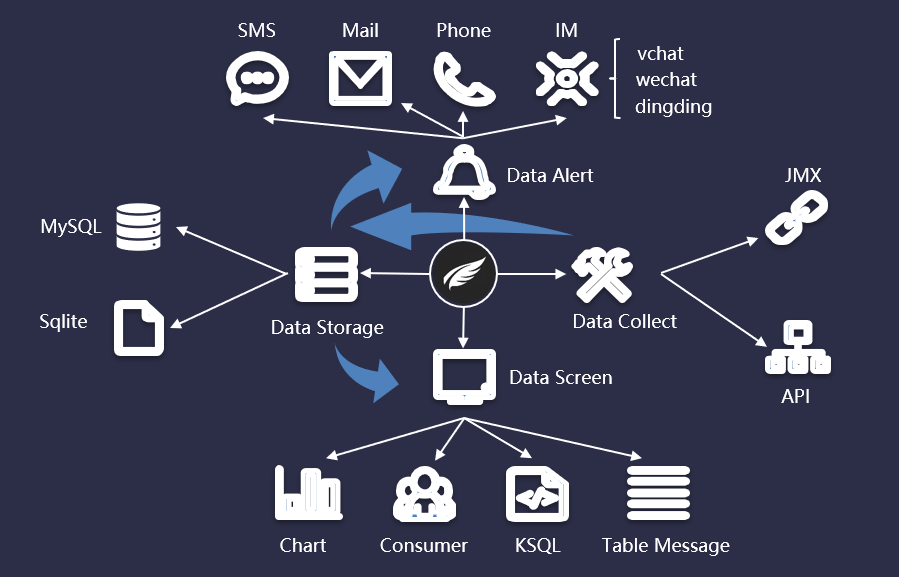
Kafka-Eagle 是一款完全开源的对 Kafka 集群及应用做全面监控的系统,其核心由以下几个部分组成:
数据采集:核心数据来源 JMX 和 API 获取;
数据存储:支持 MySQL 和 Sqlite 存储;
数据展示:消费者应用、图表趋势监控(包括集群状态、消费生产速率、消费积压等)、开发的分布式 KSQL 查询引擎,通过 KSQL 消息查询;
数据告警:支持常用的 IM 告警(微信,钉钉,WebHook等),同时邮件、短信、电话告警也一并支持。
部分预览截图如下:
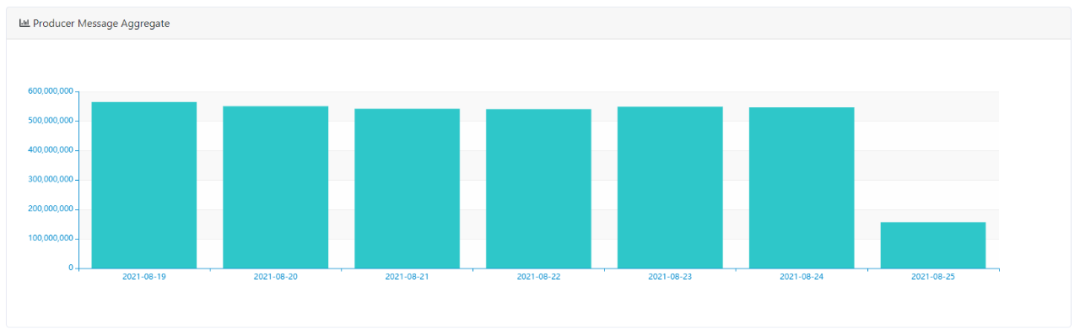
1)Topic最近7天写入量分布
默认展示所有Topic的每天写入总量分布,可选择时间维度、Topic聚合维度,来查看写入量的分布情况,预览截图如下所示:
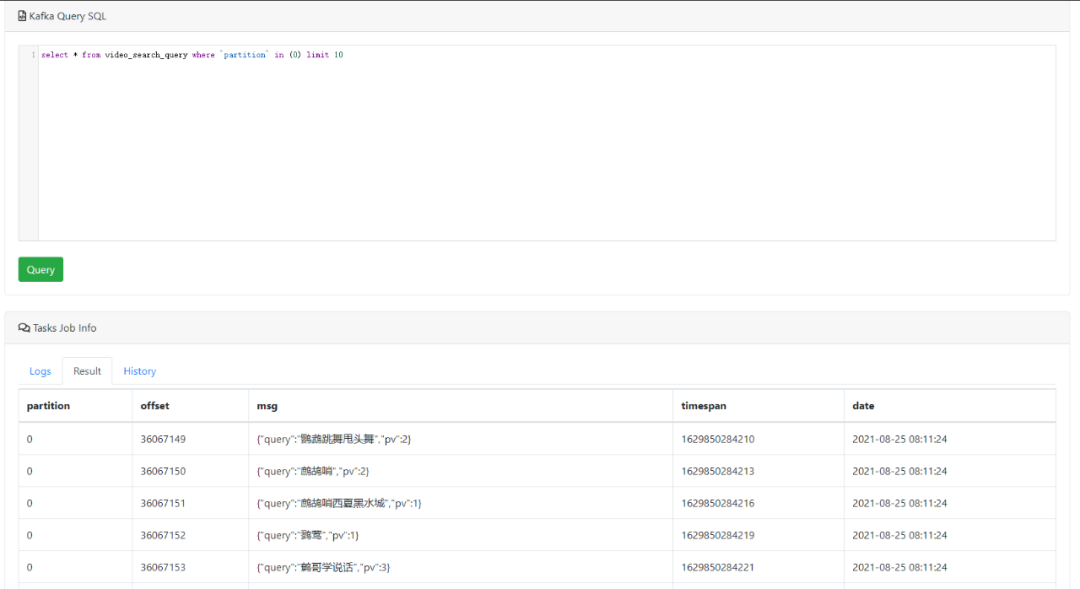
2)KSQL查询Topic消息记录
可以通过编写SQL语句,来查询(支持过滤条件)Topic中的消息记录,预览截图如下所示:
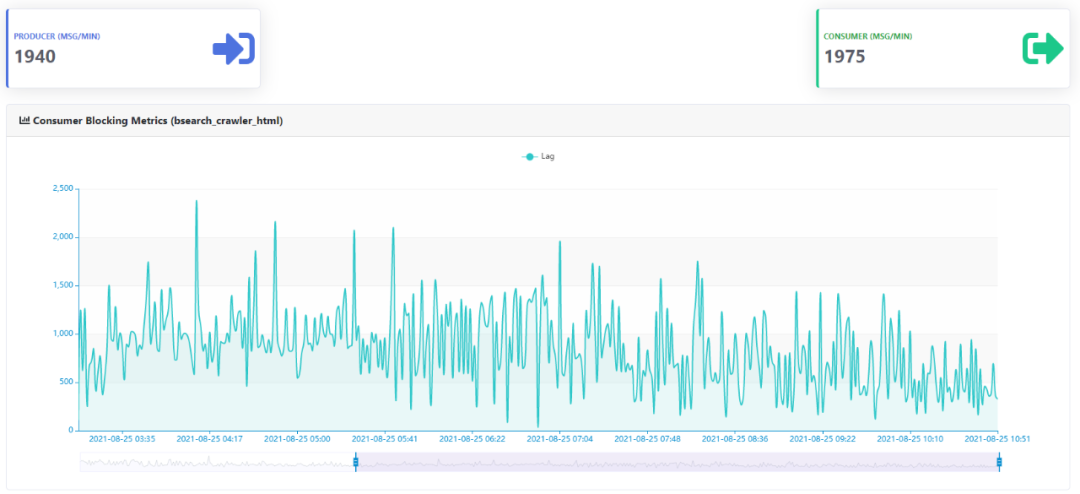
3)消费Topic积压详情
可以监控所有被消费的Topic的消费速率、消费积压等详情,预览截图如下所示:
五、参考资料
1.https://kafka.apache.org/documentation/
2.http://www.kafka-eagle.org/
3.https://github.com/smartloli/kafka-eagle