
HBase-整体架构及读写原理
1.HBase架构图
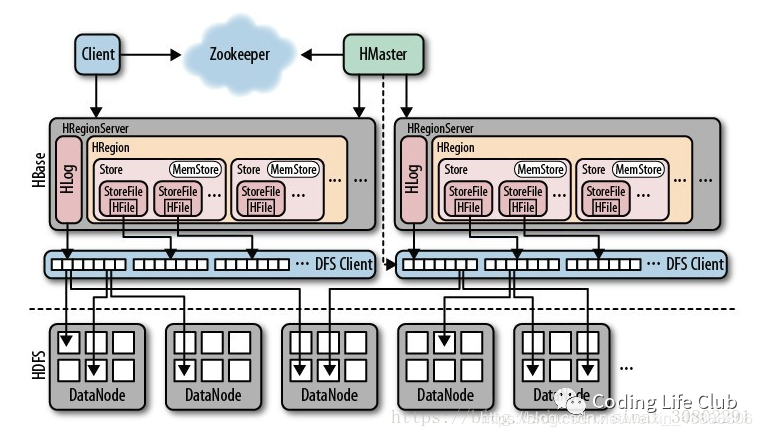
上图标明了HBase各个组件及其内在联系,主要有以下几部分
HMaster:HBase的管理节点,可以为多个,实现HA,负责将region分配给HRegionServer,协调RegionServer的负载并维护集群的状态,维护元数据,不参与数据的输入输出。
HRegionServer:HBase的工作节点,主要作用为依托ZookeeperWatcher进行分布式信息共享与任务协调;Region的管理;WAL(Write-Ahead-Log)管理;Metrics
zookeeper:zk的本质是注册中心,集成在HBase内部负责以下任务,hbase regionserver 向zookeeper注册,提供hbase regionserver状态信息(是否在线);hmaster启动时候会将hbase 系统表-ROOT- 加载到 zookeeper cluster,通过zookeeper cluster可以获取当前系统表.META.的存储所对应的regionserver信息;
client:hbase的客户端,可以使用第三方封装好的client。也可以使用hbase自带的client
HDFS:HBase的底层存储系统。
2.HBase写入为什么那么快?
HBase写入优先,它并不会直接写入磁盘,而是写入MemStore,待MemStore达到阈值,再异步刷入文件形成一个StoreFile。多个小的StoreFile会合并成一个大的StoreFile。当大的StoreFile达到阈值,就会触发split,将当前的Region分割成两个子的Region并被HMaster分配到不同的RegionServer上。整个写入过程由于全内存操作,所以很快。
3.HBase读取为什么那么快?
首先看一下HBase读取数据的大致流程
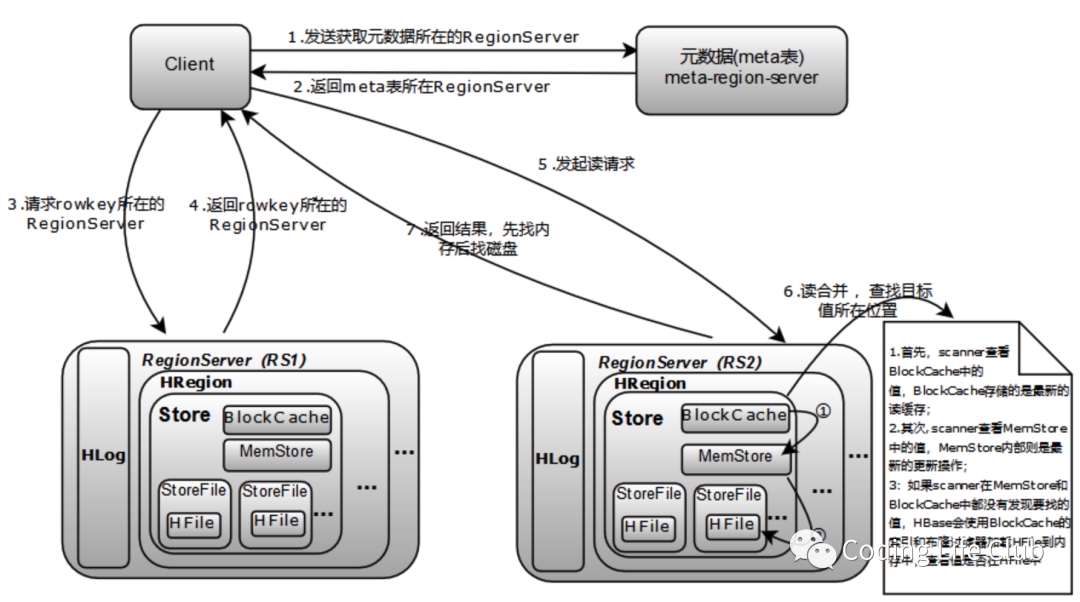
寻址流程
client–>Zookeeper–>ROOT表–>META表–>RegionServer–>Region–>client
具体流程
先到zk找到root表的RegionServer(root表的地址);
到root表中找到meta表的RegionServer(meta表的地址);root表的region只会有一个,meta表的region会有多个;为了加快访问速度meta表的数据会被缓存到client且不会主动过期。在应用中就有主动flush client cache的操作;
到meta表中找到对应数据的RegionServer;
到数据的RegionServer中找到对应的Region;
先到BlockCache查找,找不到再到MemStore查找,再找不到就到StoreFile中查找,然后缓存到BlockCache中;BlockCache负责读,MemStore负责写,这种读写分离的设计是HBase写和读都很快的基础。为了加快查询,在StoreFile中使用了布隆过滤器(LSM树的优化方式)。HBase只是增加数据(因为HFile是只读的),更新和删除数据都是在合并(Compact)阶段完成的。
4.HBase宕机如何处理?
宕机分为 HMaster 宕机和 HRegisoner 宕机,如果是HRegionServer宕机, HMaster 会将其所管理的region重新分布到其他活动的RegionServer上,由于数据和日志都持久在 HDFS中,该操作不会导致数据丢失。所以数据的一致性和安全性是有保障的。如果是HMaster宕机, HMaster没有单点问题, HBase中可以启动多个HMaster,通过Zookeeper 的 Master Election机制保证总有一个Master运行。即 ZooKeeper 会保证总会有一个 HMaster 在对外提供服务。5.HBase中compact用途是什么,什么时候触发,分为哪两种?
用途:合并文件;清除过期,多余的版本;提高读写文件的效率;
触发:store的storeFile达到一定阈值后,就会进行compact。
分类:
minor:合并部分文件;不做任何删除数据、多版本数据的清理工作;
major:对一个store下的所有storefile执行合并,最终合并成一个文件,多余版本会在这时清理;更新、删除也在这时进行;