
Python更新Elasticsearch数据方法大全

大家好,我是村长
今天总结一下通过 Python 更新 Elasticsearch 数据的几个方法
Elasticsearch 是一个实时的分布式搜索分析引擎,它能让你以前所未有的速度和规模,去探索你的数据。它被用作全文检索、结构化搜索、分析以及这三个功能的组合
全局更新
在 Elasticsearch 中,通过指定文档的 _id, 使用 Elasticsearch 自带的 index api 可以实现插入一条 document , 如果该 _id 已存在,将直接更新该 document
因此,通过 index API 来对已有的文档实现更新,其实是进行了一次 reindex 的操作 如 ES 中已有数据如下

通过代码将其更新:
es.index(index="test", doc_type="doc", id="dfebcXcBCWwWKoXwQ2Gk", body={
"name": "Python编程实战",
"num": 5})
修改后结果

通过这种方法修改,因为是 reindex 过程,所以当数据量或者 document 很大的时候,效率非常的低
局部更新
update
Elasticsearch 中的 update API 支持根据用户提供的脚本去实现更新
Update 更新操作允许 ES 获得某个指定的文档,可以通过脚本等操作对该文档进行更新。
可以把它看成是先删除再索引的原子操作,只是省略了返回的过程,这样即节省了来回传输的网络流量,也避免了中间时间造成的文档修改冲突。
在 Python 中可以直接通过包装好的接口来更新
es.update(index="test", doc_type="doc", id="4Z6XcXcBChYTHL1ZdwjL", body={"doc": {"name": "Jerry"}})
注意 body 参数,我们需要添加 doc 或者 script 变量来指定修改的内容
增加字段:
es.update(index="test", doc_type="doc", id="4Z6XcXcBChYTHL1ZdwjL", body={"doc": {"name": "Jerry", "age": 25}})
运行完之后,在 kibana 上查看结果
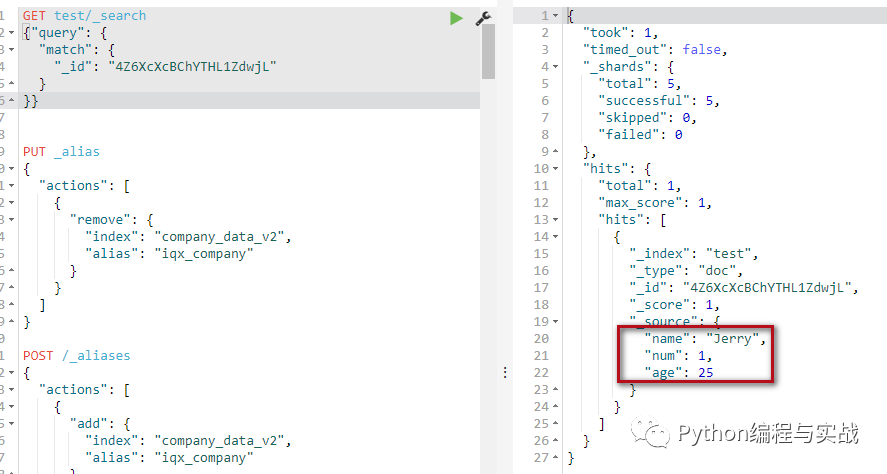
搜索更新
update_by_query
update_by_query,顾名思义,这种更新方式,即通过查询再更新。
该方法的优点是可以指定某些数据,然后达到更新的目的
在 ES 中,我们通过 update_by_query 中的 query 和 script 来实现先查询再更新的机制
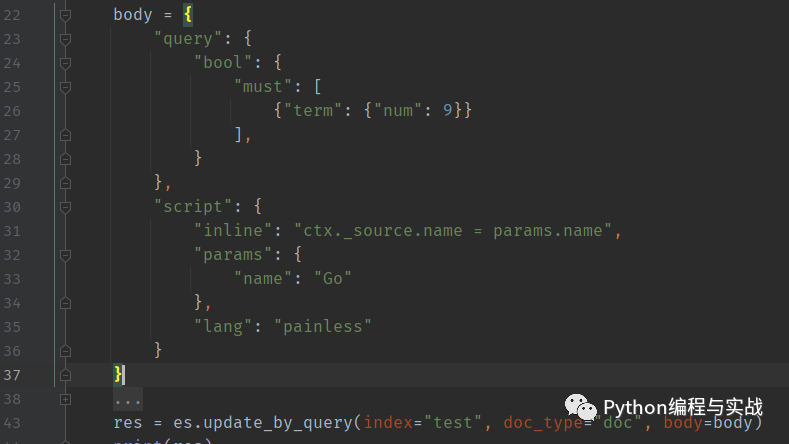
在上面的操作中:query 字段,表示我们要查询的条件,根据该条件找到对应的数据 script 字段包含以下关键字:
source 是将要执行的脚本内容; lang 表示的是当前脚本的语言*; param 则是脚本执行的参数;
参考详情:https://www.elastic.co/guide/en/elasticsearch/reference/master/modules-scripting-painless.html
批量更新
在实际需求中,面对最多的还是批量更新
当然你也可以通过 for 循环一条一条来更新,不过这种方法效率太低了。
尤其是面对数据量很大的时候,那真的是急死人..
好在 ES 有提供批量操作的接口 bulk
在 Python 中可以直接导入使用
from elasticsearch.helpers import bulk
那么在 bulk 中如何使用 update 呢?请看代码
actions = []
for item in data_list:
_id = item.get("_id")
doc = item.get("doc")
index_action = {
'_op_type': 'update',
'_index': index_name,
'_type': "doc",
'_id': _id,
'doc': doc
}
actions.append(index_action)
if actions:
bulk(es, actions)
可以看到有个 doc 的参数,和上面介绍的 update 方法类似,doc中的值便是我们需要修改的字段内容
_op_type 为操作类型为update,表明是更新的操作
以该种方式组合的 index_action 组成数组,通过 bulk 便能实现批量更新 !
以上便是通过 Python 更新 Elasticsearch 的几种方法
个人推荐通过 update 接口或者 bulk 批量来做更新,你学废了吗?
推荐阅读

手机最强Python编程神器,在手机上运行Python

Python高效代码实践:性能、内存和可用性