
我都服了,为啥上游接口返回的汉字总是乱码?
前言
想必大家编写代码时肯定和我一样,也遇到过汉字乱码的问题。特别是,有时候和上下游对接接口,不能统一编码格式的话,一堆乱码问题,让人头皮发麻。
那么为什么会有这么多的乱码问题?
什么是字符编码?什么是字符集?他们之间有什么区别和联系?
什么是 Unicode ?Unicode 和我们常说的 UTF-8 又有什么关系?
字符编码和解码
要想搞清楚上面的问题,首先我们要知道,在计算机中,不管是一段文字、一张图片还是一段视频,最终都是以二进制的方式来存储。也就是最终都会转化为 0001 1011 0010 0110 这样的格式。
换句话说,计算机只认识 0 和 1 这样的数字,并不能直接存储字符。所以我们需要告诉它什么样的字符对应的是什么数字。
例如,我们的业务中有记录客户端的客户行为日志,然后导出文件来分析,字段间会以 ESC 来分隔。
我在编写代码的时候,就需要定义一下这个ESC 字符应该对应什么数字,这样计算机才能识别并存储。
比如我把它定为 0001 1011,这样计算机就把 ESC 这个字符存了下来。等我下次需要查看的时候,根据对应关系把它解出来就可以了。
上边的两个过程就对应字符的编码和解码过程。
字符编码就是把字符按一定的规则,转换成数字。字符解码是编码的逆过程,即把数字按规则转换成字符。
这样看来,貌似没有什么问题。
但是,这是我自己定义的编码规则,我同桌阿霄就不乐意了。他非要认为 ESC 应该定义为 1101 1000,好家伙正好和我定义的二进制数字顺序相反。
那结果肯定不用说了,我把 0001 1011 这串数字给他之后,按照他的编码规则来解,肯定是 &$#!这样的东西。
所以,乱码问题说到底,就是编码和解码的规则对应不上导致的。
ASCII 码
为了避免我和阿霄因为编码问题打起来,美国国家标准学会(AMERICAN NATIONAL STANDARDS INSTITUTE) ANSI 组织发话了。
停、停、停。不就是个编码问题吗,这种小事犯不着动手,我定义一个统一的规则,大家都按照我的规则来编码和解码不就好了嘛。
于是,ASCII 码出现了,它定义了一个常用字符集,用来表示字符和数字的对应关系,如下表。
ASCII 码全称:美国信息交换标准代码 (American Standard Code for Information Interchange)
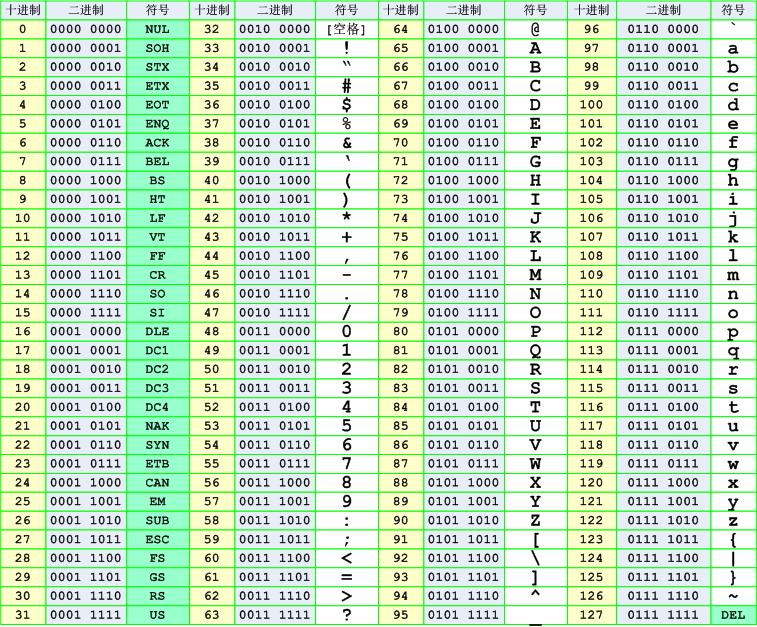
我一查表,ESC 字符不就对应 27 吗,对应的二进制就是 0001 1011 。我去,没想到我定义的规则竟和 ANSI 不谋而合。
同桌阿霄把抡在空中的拳头收了起来,默默地回去敲代码了。
ASCII 码扩展码
在使用英语的国家,ASCII 码就足够用了。但是,在其他欧洲发达国家比如法国,使用的语言是法语,有类似于这样的 á 符号,ASCII 码就不能表示了。那怎么办呢?
我们看上表就会发现,ASCII 码表的表示范围是十进制 0~127,也就是二进制 0000 0000 到 0111 1111 。其实只是用了后边的 7 位,第一位都是 0 。
而计算机二进制中一个字节是 8 个位,现在只用了 7 位。不行啊太浪费了,要充分利用第一个高位,扩展一下,这样多了一位,能表示的字符范围就多了一倍。(2的8次方=256)
这样一些欧洲其他国家,也能在计算机中表示自己的文字了。
后来,随着计算机的普及,中国的用户也多了起来。却发现,一个字节只能表示 256 个字符,远远不能满足我们的要求。
于是,就出现了 GB2312 编码,它使用了两个字节来表示一个汉字。但是,并没有把所有的位都用完,前面一个字节范围 0xA1 ~ 0xF7 (即 10110001 ~ 11110111),后面一个字节范围 0xA1 ~ 0xFE (即 10110001 ~ 11111110) 。这样就能表示简体汉字 6763 个。
GB2312 是国家标准总局发布的《信息交换用汉字编码字符集》,也可以说是简体中文的字符集。
但是,台湾和香港等使用繁体字的地区怎么办。于是,就有了大五码 Big5 编码来存储繁体。高字节(第一个字节)表示范围 0x81~0xFE,低字节(第二个字节)表示范围 0x40 ~ 0x7E,以及0xA1 ~ 0xFE 。
需要注意的是,GB2312 是简体中文,Big5 是繁体中文。如果用其中一种编码文字去读另外一种编码文字就会乱码。所以,就出来了 GBK 编码,把简体中文和繁体中文,以及一些 GB2312 不支持的人名(如历代总理有的名字用 GB2312 打不出来),还有一些我们不认识的古汉语都包含进去,共 2 万多个字符。
再然后,我们发现少数民族像藏文,蒙古文这些少数民族的语言,GBK 也支持不了,就再进行扩展,出现了 GB18030 。又多了几千个少数民族的文字。
所以,我们使用的 GB 国标系列文字都是在 ASCII 码之上扩展的,它们是依次向下兼容的。表示文字范围从小到大为 GB2312 = Big5 < GBK < GB18030 。
Unicode 字符集
我们在打开一个文档之前,就必须要知道它的编码格式,否则用错误的方式解码就会出现乱码情况。
设想,如果一个文本中,有多种类型文字,包括中文,韩语,德语,日语,应该用哪种编码方式?貌似怎么处理都会有乱码问题,那怎么办呢?
ISO(国际标准化组织)说:这好办啊,我把地球上,只要是人们使用的,所有语言和符号都囊括其中,为每个字符都指定一个唯一的字符码,这样就没有乱码问题了。于是 Unicode 出现了,又叫统一码,万国码。

如上图表,汉字“一”对应的 unicode 码是 \u4e00。我们通常在字符码前加个 \u代表这是 unicode 码。4e00 是十六进制表示。
也有很多在线转码工具供我们使用,如:http://tool.chinaz.com/tools/unicode.aspx
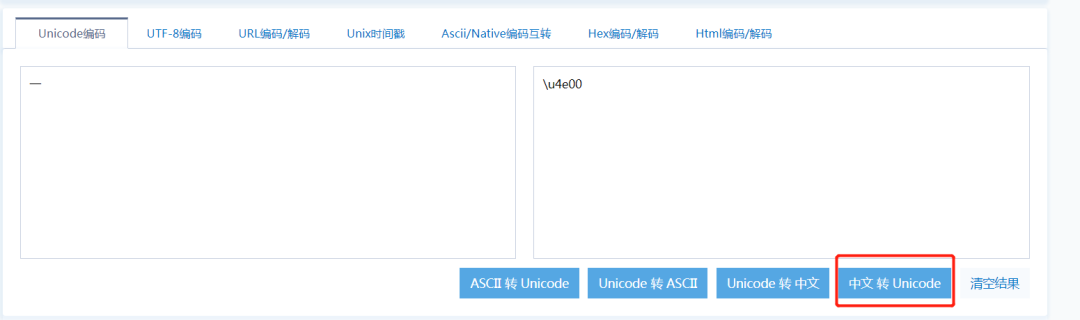
Unicode 编码方案
首先强调一下以下几个概念的区别:
字符:就是我们看到的一个字母或一个汉字、一个标点符号都叫字符。如上边的汉字“一”就是一个字符。
字符码:在指定的字符集中,一个字符对应唯一一个数字,这个数字就叫字符码。如上边的字符“一”,在 Unicode 字符集中,对应的字符码为
\u4e00。字符集:规定了字符和字符码之间的对应关系。
字符编码:规定了一个字符码在计算机中如何存储。
需要注意的是,Unicode 只是一个字符集,它规定了每个字符对应的唯一字符码,却没有规定这个字符码在计算机中怎样存储(也就是它的字符编码格式)。
例如,上边的汉字“一”,它的 Unicode 字符码为 \u4e00,转换成二进制就是 100 1110 0000 0000 。可以看到,它有 15 位二进制数,至少需要两个字节来存储。
这只是简单的汉字,如果其他复杂的字符有可能会需要 三、四 个字节或者更多字节来存储。
那么到底应该用几个字节来存储呢?
于是 UTF-32 编码 制定了标准,一个字符就用四个字节来表示。这样编码和解码都方便,固定取 32 位二进制就行了。
但是这样又引来一个问题。比如 A 字符其实只需要一个字节就可以存储了。如果必须要用四个字节来存储,那么前边三个字节都要补 0 ,这样势必会造成空间的浪费。
于是 UTF-16 编码(一个字符用两个字节或者四个字节)和我们熟悉的 UTF-8 编码格式就出现了。
这里我们重点介绍 UTF-8 。它使用一种变长的编码方式,可以使用 1~4 个字节来表示一个字符。根据不同的字符变换长度。
变长听起来很美好,但是它的不固定性,就让计算机懵逼了。比如,计算机怎么知道这四个字节代表的是一个字符,还是四个字符,亦或是两个字符呢?
于是,UTF-8 规定了以下编码规则,来避免以上问题。
对于单字节的符号,第一位设为0,后边 7 位对应这个字符的ASCII码值。因此,像“A"这样的英文字母,UTF-8 编码和 ASCII 编码是相同的。
对于大于一个字节的符号,假设为 n 字节,那么第一个字节的前 n 位都设为 1,这样有几个 1 就说明有几个字节。然后,第 n+1 位设为0 。后边的字节,前两位都设为10 ,剩余的其他二进制位都用这个字符的 Unicode 码填充(从后向前填充,不够补0)。

刚开始看上表,可能比较懵逼。其实,Unicode 符号表示的范围最大为四个字节,因此二进制为 4*8=32 位。我们知道,二进制转换十六进制时,以四位为一个单位转换,因此,对应的十六进制为 32/4=8 位。
上表中的 Unicode 符号范围是以 16 进制表示,可以看到就是 8 位的。
我们还是以汉字 “一” 为例,16进制表示为 4e00,补全所有位,其实就是 0000 4E00 (不区分大小写)。因此,查上表发现,它处在三个字节的 Unicode 范围内(0000 0800 < 0000 4e00 < 0000 FFFF)。
所以,它用 UTF-8 来编码,就是三个字节的,即格式是这样的 1110xxxx 10xxxxxx 10xxxxxx 。
把 4e00 转换为二进制为 100 1110 0000 0000,二进制位从后向前依次填充到上述格式中的x位置(也是从后向前填充)。
于是,就得出汉字 “一” 的 UTF-8 编码后的二进制表示为:1110 0100 1011 1000 1000 0000 。
其实,可以发现,汉字的二进制为 15 位,前边补零一位即为 16 位 0100 1110 0000 0000。而三个字节的 UTF-8 编码格式中的 x 个数也为 3*8 - (4+2+2) = 16 位,正好一一对应。
那么,我们这一通推算,是否正确呢。可以在程序中打印这个字符的二进制格式,以及UTF-8编码后的二进制。程序如下,
public class Test {
public static void main(String[] args) throws UnsupportedEncodingException {
System.out.println("字符'一'的二进制为:" + Integer.toBinaryString('一'));
System.out.println("========");
String str = "一";
System.out.println("转换为UTF-8编码格式的二进制为:"+ toBinary(str,"utf-8"));
}
public static String toBinary(String str, String encode) throws UnsupportedEncodingException {
StringBuilder sb = new StringBuilder();
byte[] bytes = str.getBytes(encode);
for (int i = 0; i < bytes.length; i++) {
byte b = bytes[i];
sb.append(Integer.toBinaryString(b & 0xFF));
}
return sb.toString();
}
}
打印结果为:
字符'一'的二进制为:100111000000000
========
转换为UTF-8编码格式的二进制为:111001001011100010000000
PS:通常的,我们发现常用的汉字以 16 进制表示都在 0000 0800 ~ 0000 FFFF 范围内。因此,汉字在 UTF-8 编码下通常占用三个字节。
细心的同学可能发现了,我上边转换的汉字可以用 char 类型来存储,这是为什么呢?
这是因为,在 Java 中,默认使用的字符集就是 Unicode,可以容纳 100 多万个字符,其中就包括汉字。
我们使用的绝对大多数汉字,都在0000 0800 ~ 0000 FFFF 这个范围内,可以看出来前边的四位十六进制都用不到(都是0000),因此,只需要后边的四位十六进制位,转换为二进制就是 4*4=16 位,只占用了两个字节(16/8=2)。而 char 在 Java 中占用两个字节,完全可以用来存储汉字。
总结
最后,来解答下文章开头的问题。
乱码的问题,究其根本原因,其实是编码和解码时的规则不一样导致的。
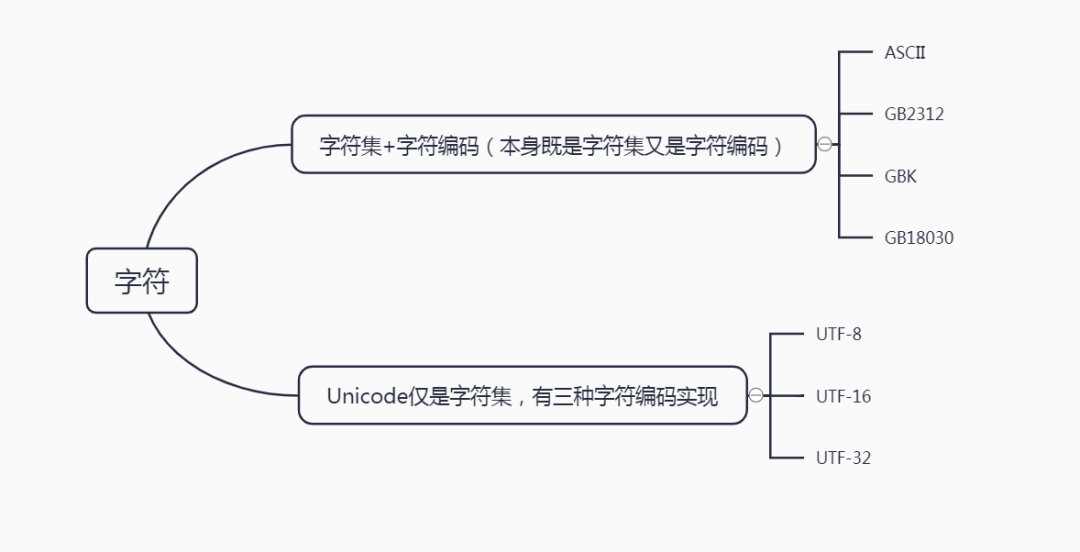
字符编码和字符集是两个不同的概念。一句话表示:字符集定义了字符到数字的映射关系,字符编码定义了这个数字如何在计算机中表达(存储)。
对于 ASCII 和 GB 系列,他们既是字符集也是字符编码。GB 兼容 ASCII 码。
而对于 Unicode 来说,字符集是 Unicode,而字符编码可以是 UTF-8,UTF-16 和 UTF-32 。所以,我们平时常用的 UTF-8 编码其实只是 Unicode 的一种编码实现方式而已。
有道无术,术可成;有术无道,止于术
欢迎大家关注Java之道公众号
好文章,我在看❤️