
JavaScript 逆向爬虫中的浏览器调试常见技巧(下)

上一篇文章聊到 JS 逆向中关于浏览器调试的常用技巧,文末的实战并没有阐述加密参数的破解过程
本篇文章将继续聊聊破解加密参数的完整流程
1. 分析
在 Network 面板下的 Filter 输入框中输入关键字:api/movie status-code:200
然后,在底部页面导航区域切换页面,筛选出发送的网络请求
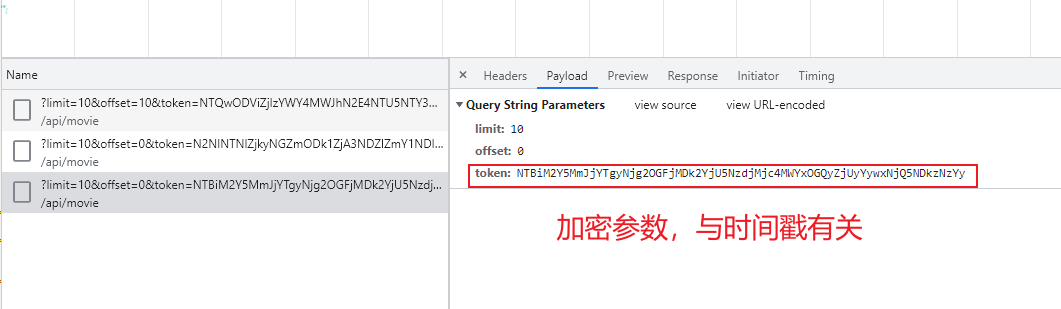
PS:同一个页面重复发送请求时,token 值都不一同,说明 token 值的生成规则与时间戳有一定的关系
回到上一节通过 XHR 断点 + Call Stack 从源码中找到真实发送网络请求的位置
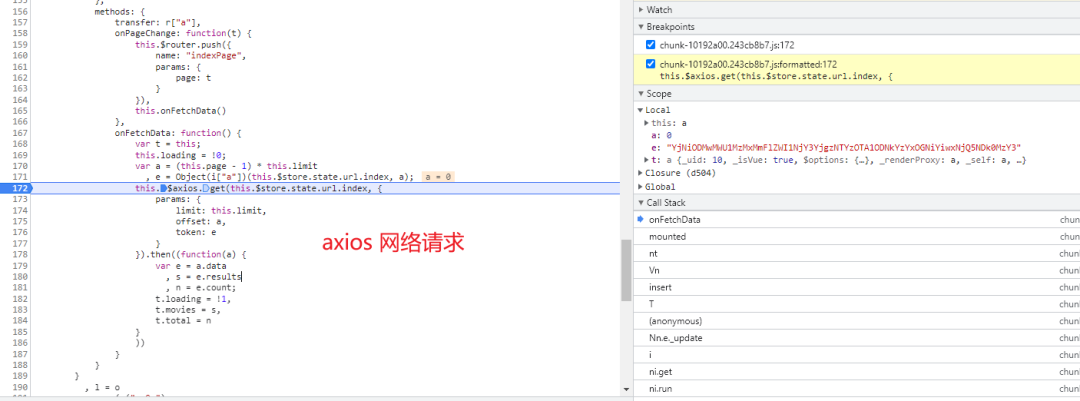
参数 params 中的 token 值来源于变量 e,我们继续进行分析
变量 a
变量 a 由页码数 page、每一页的限制数目 limit 计算所得
即:
var a = (this.page - 1) * this.limitObject(i["a"])
在 console 控制台打印后发送是一个具体的函数,变量 e 由这个函数生成
其中,参数
this.$store.state.url.index为当前请求的路径这里为:
/api/movie
接下来,在右侧 Watch 面板添加对函数名 Object(i["a"]) 的监听,获取函数的真实位置
即:函数 i 的返回值即为 token
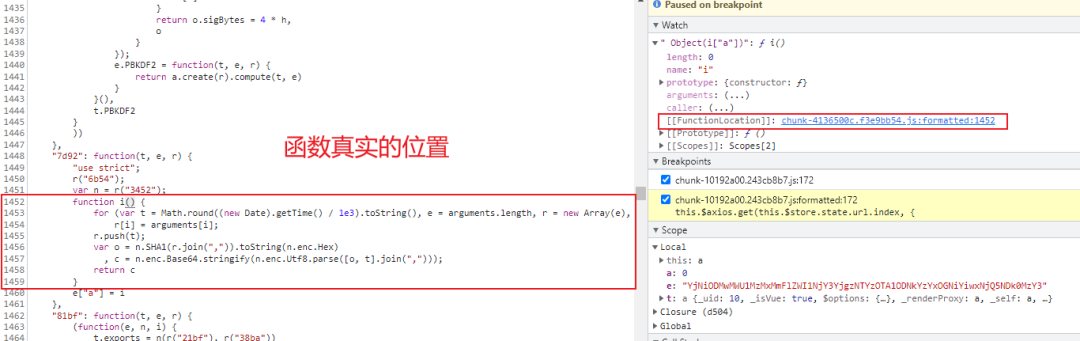
在函数 i 中添加断点,重新刷新页面后观察右侧的Scope 面板区

我们发现以下规律:
arguments
该数组来源上面 Object(i["a"]) 函数传递的两个参数,即:path 和变量 a
r
数组 r 在 arguments 的基础上添加了一个 10 位的时间戳
n.SHA1(r.join(",")).toString(n.enc.Hex)
数组 r 通过符号
,合并成一个字符串,通过 SHA1 加密后赋值给 on.enc.Base64.stringify(n.enc.Utf8.parse([o, t].join(",")))
字符串 o 和时间戳字符串组成一个数组,然后通过符号 , 合并成一个新的字符串
,转换为 base64 赋值给 c,最后作为函数返回值返回
2. 逆向
首先,我们新建一个 JS 文件,用于编写生成 token 的逻辑
2-1 时间戳及参数
其中函数 get_token() 中的参数 page、limit 分别对应页码数(从 0 开始)、分页数目
/**
* 当前时间戳(10位)
*/
function get_timestramp() {
return Math.round(new Date().getTime() / 1000).toString();
}
function get_token(page, limit){
//获取时间戳
var current_timestrap = get_timestramp()
let a = (page - 1) * limit
//组成第一个参数
var arguments = ['/api/movie', a, current_timestrap]
...
}
2-2 加密
通过上面的分析,先进行一次 SHA1 加密,然后再进行一次 Base64 编码转换
//加密
function encode(r, t) {
var o = sha1(r.join(","))
console.log("SHA1加密后的结果为:", o)
//转为base64
var pre = [o, t].join(",")
var result = stringToBase64(pre)
return result
}
...
//SHA1加密
function sha1(s) {
...
//受限篇幅,源码上传在文末
}
...
//字符串base64编码
function stringToBase64(str) {
return new Buffer.from(str).toString("base64");
}
2-3 安装依赖
由于需要通过 Python 调用 JS,这里以 PyExecJS 这种方式为例进行说明
# 安装依赖库
pip3 install PyExecJS
当然,也可以参考下面文章中的其他方案
2-4 测试一下
读取本地 JS 文件,调用该文件中获取 token 的方法,返回值作为 token 作为参数进行请求即可
import requests
import execjs
# 安装依赖:pip3 install PyExecJS
headers = {
...
}
def js_from_file(file_name):
"""
读取js文件
:return:
"""
with open(file_name, 'r', encoding='UTF-8') as file:
result = file.read()
return result
# 参数
page = 2
limit = 10
context = execjs.compile(js_from_file('./mt.js'))
token = context.call("get_token", page, limit)
print("获取token:", token)
params = {
'limit': limit,
'offset': (page - 1) * 10,
'token': token,
}
response = requests.get('**', headers=headers, params=params)
print(response.text)
print(response.status_code)3. 总结
本文作为上篇文章的一个补充,详细说明了获取加密参数的完整流程
我已将文中所有源码上传到后台,回复关键字「 js220409」即可以获取
如果你觉得文章还不错,请大家 点赞、分享、留言 下,因为这将是我持续输出更多优质文章的最强动力!
END