
NVIDIA Chat With RTX(1)——TensorRT-LLM
- Demo介绍:将自定义资料(文档、笔记、视频或其他数据)与LLM建立连接,从而令 LLM 更具个性化。支持多种文件格式,包括文本文件、pdf、doc/docx 和 xml。只需在该应用中指定包含目标文件的文件夹,该应用便会在几秒内将目标文件加载到库中。不仅如此,还可以提供YouTube 播放列表的URL,然后该应用会自动加载播放列表中的视频转写内容,使之能够查询视频中包含的内容。
- 视频介绍:https://images.nvidia.cn/cn/youtube-replicates/gdsRJZT3IJw.mp4
- Demo的【核心参考】代码:https://github.com/NVIDIA/trt-llm-rag-windows (注意:Demo是参照此代码进行二次开发)
- 整包下载链接(35G):https://us.download.nvidia.cn/RTX/NVIDIA_ChatWithRTX_Demo.zip
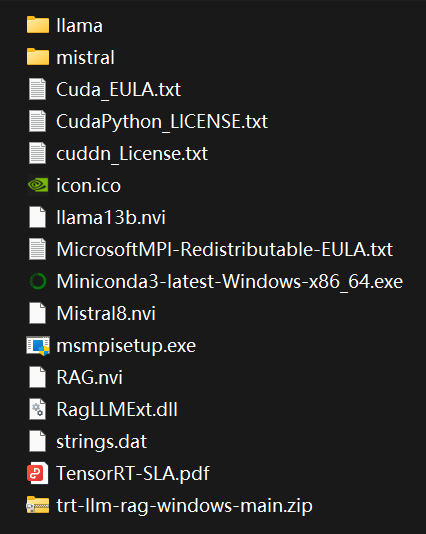 解压后目录结构如上。该包已经把llama2-13B-int4量化模型(约25G)和mistral-7B-int4量化模型(约14G)集成进去,也把trt-llm-rag-windows代码集成到trt-llm-rag-windows-main中。
解压后目录结构如上。该包已经把llama2-13B-int4量化模型(约25G)和mistral-7B-int4量化模型(约14G)集成进去,也把trt-llm-rag-windows代码集成到trt-llm-rag-windows-main中。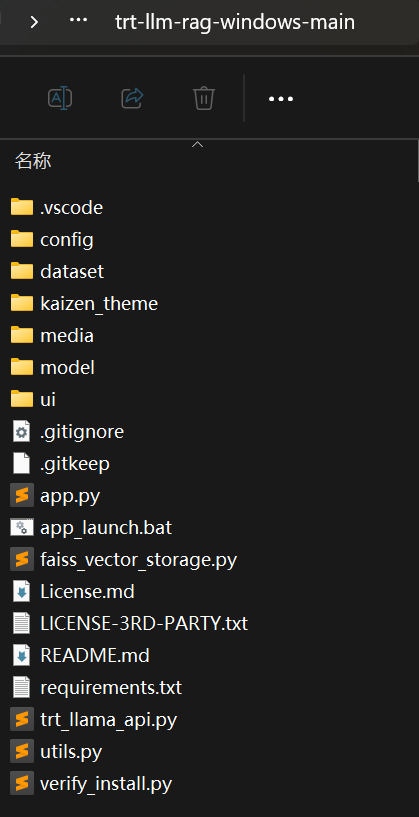 运行平台和资源要求如下:
运行平台和资源要求如下: 总的来说,整个技术栈包括几个方面:
总的来说,整个技术栈包括几个方面:
- LLM:Llama2-13B、Mistral-7B、AWQ量化技术
- 加速框架:TensorRT-LLM
- RAG:基于llama-index、langchain、Faiss实现RAG
TensorRT-LLM

1. 简介
首先介绍TensorRT-LLM,这是一个用于优化LLM推理的工具包。它提供了Python API来定义模型并将其编译成针对NVIDIA GPU的高效TensorRT引擎。它还包含Python和C++组件来构建Runtime以执行这些引擎,以及Triton推理服务器的后端,以便于创建基于Web的LLM服务。
2. 主要特点
- TensorRT-LLM支持通过两种不同的模型并行模式实现多GPU支持:
- 张量并行(Tensor Parallelism) :将模型的不同层分割到不同的GPU上,每个GPU运行整个网络并在需要时与其他GPU同步。
- 流水线并行(Pipeline Parallelism) :将模型的不同层分配给不同的GPU,每个GPU运行模型的一个子集,在这些层子集之间的边界发生通信。
3. 使用TensorRT-LLM的几个关键步骤
- 定义模型:使用Python API描述LLM;可以定义自定义模型或使用预定义的网络架构。
- 训练模型:使用其他训练框架进行训练,获得checkpoint。
- 编译引擎:使用TensorRT-LLM的Builder API将模型编译成优化的TensorRT引擎。
- 构架Runtime:使用TensorRT-LLM的运行时组件加载并驱动引擎的执行。
- 服务化部署:使用Triton后端快速创建基于Web的服务。
4. LLM推理性能指标
衡量LLM推理服务的4个主要性能指标:
- 第一次生成词汇时间(Time to First Token,TTFT):度量模型在收到用户查询后生成第一个词汇的时间。TTFT越短,用户体验越好。
- 每输出词汇时间(Time Per Output Token,TPOT):计算模型为一个指定查询生成一个词汇所需的时间。TPOT越快,用户感知到的模型越快。
- 延迟(Latency):将TTFT和生成所有词汇的总时间(用TPOT计算)相加,测量模型整体响应一个查询的时间。
- 吞吐量(Throughput):测量服务器为所有用户和查询每秒生成的输出词汇数量。优化最大吞吐量可以提高服务器容量和用户体验。
5. 部署LLM的挑战
- 高内存使用:LLM需要大量内存来存储它们的参数和中间激活,尤其是是来自注意力层的key和value参数。这使得在资源有限的环境中部署它们变得困难。
- 可扩展性有限:传统实现难以处理大量并发推理请求,导致可扩展性和响应性问题。当在生产服务器上运行LLM时,GPU的利用率不高时,这一点尤为突出。
- 计算开销:LLM推理涉及的广泛矩阵计算可能很昂贵,尤其是对于大型模型。高内存使用和低吞吐量的结合进一步增加了运营成本。
这些挑战凸显了需要更高效和可扩展的方法来部署LLM进行推理。通过解决这些挑战,可以释放LLM的全部潜力,并实现它们在各种应用中的无缝集成。
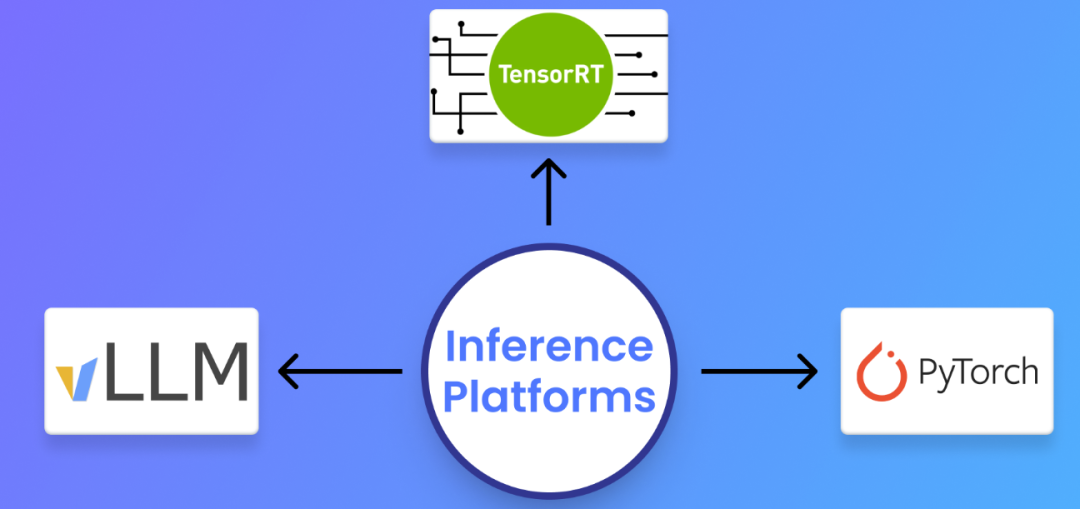
6. 和vLLM、PyTorch的Flash-Decoding对比分析
| Feature / Aspect | Nvidia TensorRT-LLM | vLLM | PyTorch (Flash-Decoding) |
|---|---|---|---|
| 内存效率 | 利用NVIDIA硬件优化LLM的内存使用 | 采用PagedAttention算法进行高效内存管理 | 采用Flash-Decoding来优化长上下文推理的内存使用 |
| 吞吐量 | 利用诸如在in-flight batching等技术以获得高吞吐量 | 声称与传统Transformer相比实现了更高的吞吐量 | 即使处理非常长的序列也能实现高吞吐量的有效并行化 |
| 计算效率 | 使用流式tokens和量化技术 | 具有高速性能,并在基准测试中实现了实质性改进 | 由于优化的注意力计算,对于非常长的序列生成速度高达8倍 |
| 平台/硬件利用 | 针对NVIDIA硬件进行优化,利用NVIDIA Hopper Transformer引擎等功能 | 为LLM工作负载设计的高效性能,适用于受限环境 | 即使处理小批量和大上下文,也充分利用GPU能力进行推理 |
| 兼容性和集成 | 提供与各种LLM的兼容性,支持集成到NVIDIA AI平台 | 与Hugging Face模型兼容的API、集成 | 与PyTorch生态系统紧密集成,适用于各种LLM的应用 |
| 性能指标** | 与传统方法相比展示更好的性能 | 优于HuggingFace serving和HuggingFace TGI | 对于序列长度的扩展性改进,在基准测试中胜过其他方法 |
| 适用场景 | 适用于利用NVIDIA生态系统的各种LLM应用 | 适用于内存有限且需要高吞吐量的环境 | 在摘要、对话或代码库等长上下文处理任务中具有优势 |
| 成本效益 | 旨在通过高效利用计算资源降低运营成本 | 设计用于经济有效的LLM部署,提高可访问性 | 为长上下文应用提供经济有效的推理 |
| 技术创新点 | 包括为LLM优化的内核和处理函数 | 持续改进服务引擎设计 | 引入新的并行化维度以提高推理效率 |
5. 参考资料
- 代码:https://github.com/NVIDIA/TensorRT-LLM/tree/main
- 文档:https://nvidia.github.io/TensorRT-LLM/
- Trt-llm在H100、A100和Ada上的表现:https://github.com/NVIDIA/TensorRT-LLM/blob/main/docs/source/performance.md
评论